 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Models via Policy-Guided Trajectory Diffusion
Dec 17, 2023



World models are a powerful tool for developing intelligent agents. By predicting the outcome of a sequence of actions, world models enable policies to be optimised via on-policy reinforcement learning (RL) using synthetic data, i.e. in "in imagination". Existing world models are autoregressive in that they interleave predicting the next state with sampling the next action from the policy. Prediction error inevitably compounds as the trajectory length grows. In this work, we propose a novel world modelling approach that is not autoregressive and generates entire on-policy trajectories in a single pass through a diffusion model. Our approach, Policy-Guided Trajectory Diffusion (PolyGRAD), leverages a denoising model in addition to the gradient of the action distribution of the policy to diffuse a trajectory of initially random states and actions into an on-policy synthetic trajectory. We analyse the connections between PolyGRAD, score-based generative models, and classifier-guided diffusion models. Our results demonstrate that PolyGRAD outperforms state-of-the-art baselines in terms of trajectory prediction error for moderate-length trajectories, with the exception of autoregressive diffusion. At short horizons, PolyGRAD obtains comparable errors to autoregressive diffusion, but with significantly lower computational requirements. Our experiments also demonstrate that PolyGRAD enables performant policies to be trained via on-policy RL in imagination for MuJoCo continuous control domains. Thus, PolyGRAD introduces a new paradigm for scalable and non-autoregressive on-policy world modelling.
TWIST: Teacher-Student World Model Distillation for Efficient Sim-to-Real Transfer
Nov 07, 2023Model-based RL is a promising approach for real-world robotics due to its improved sample efficiency and generalization capabilities compared to model-free RL. However, effective model-based RL solutions for vision-based real-world applications require bridging the sim-to-real gap for any world model learnt. Due to its significant computational cost, standard domain randomisation does not provide an effective solution to this problem. This paper proposes TWIST (Teacher-Student World Model Distillation for Sim-to-Real Transfer) to achieve efficient sim-to-real transfer of vision-based model-based RL using distillation. Specifically, TWIST leverages state observations as readily accessible, privileged information commonly garnered from a simulator to significantly accelerate sim-to-real transfer. Specifically, a teacher world model is trained efficiently on state information. At the same time, a matching dataset is collected of domain-randomised image observations. The teacher world model then supervises a student world model that takes the domain-randomised image observations as input. By distilling the learned latent dynamics model from the teacher to the student model, TWIST achieves efficient and effective sim-to-real transfer for vision-based model-based RL tasks. Experiments in simulated and real robotics tasks demonstrate that our approach outperforms naive domain randomisation and model-free methods in terms of sample efficiency and task performance of sim-to-real transfer.
Reward-Free Curricula for Training Robust World Models
Jun 15, 2023There has been a recent surge of interest in developing generally-capable agents that can adapt to new tasks without additional training in the environment. Learning world models from reward-free exploration is a promising approach, and enables policies to be trained using imagined experience for new tasks. Achieving a general agent requires robustness across different environments. However, different environments may require different amounts of data to learn a suitable world model. In this work, we address the problem of efficiently learning robust world models in the reward-free setting. As a measure of robustness, we consider the minimax regret objective. We show that the minimax regret objective can be connected to minimising the maximum error in the world model across environments. This informs our algorithm, WAKER: Weighted Acquisition of Knowledge across Environments for Robustness. WAKER selects environments for data collection based on the estimated error of the world model for each environment. Our experiments demonstrate that WAKER outperforms naive domain randomisation, resulting in improved robustness, efficiency, and generalisation.
A Framework for Learning from Demonstration with Minimal Human Effort
Jun 15, 2023
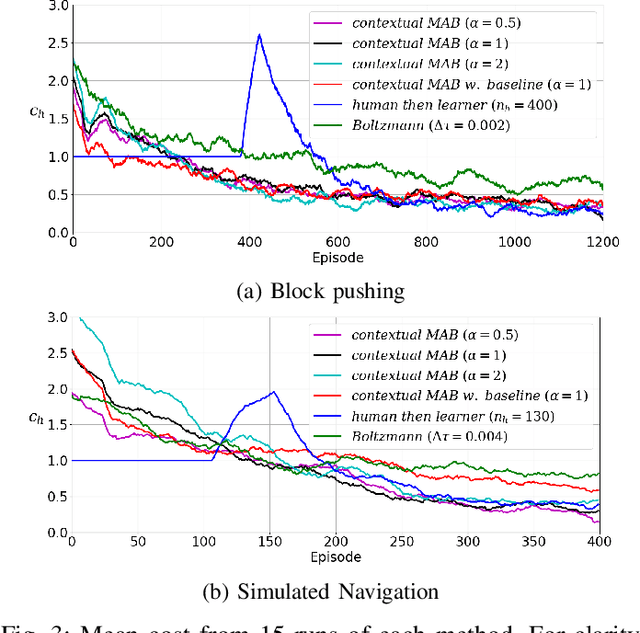
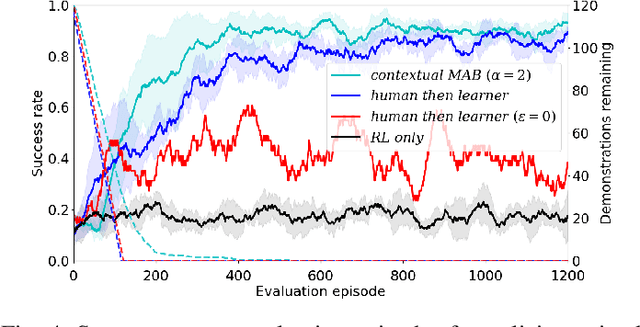
We consider robot learning in the context of shared autonomy, where control of the system can switch between a human teleoperator and autonomous control. In this setting we address reinforcement learning, and learning from demonstration, where there is a cost associated with human time. This cost represents the human time required to teleoperate the robot, or recover the robot from failures. For each episode, the agent must choose between requesting human teleoperation, or using one of its autonomous controllers. In our approach, we learn to predict the success probability for each controller, given the initial state of an episode. This is used in a contextual multi-armed bandit algorithm to choose the controller for the episode. A controller is learnt online from demonstrations and reinforcement learning so that autonomous performance improves, and the system becomes less reliant on the teleoperator with more experience. We show that our approach to controller selection reduces the human cost to perform two simulated tasks and a single real-world task.
Risk-Sensitive and Robust Model-Based Reinforcement Learning and Planning
Apr 02, 2023



Many sequential decision-making problems that are currently automated, such as those in manufacturing or recommender systems, operate in an environment where there is either little uncertainty, or zero risk of catastrophe. As companies and researchers attempt to deploy autonomous systems in less constrained environments, it is increasingly important that we endow sequential decision-making algorithms with the ability to reason about uncertainty and risk. In this thesis, we will address both planning and reinforcement learning (RL) approaches to sequential decision-making. In the planning setting, it is assumed that a model of the environment is provided, and a policy is optimised within that model. Reinforcement learning relies upon extensive random exploration, and therefore usually requires a simulator in which to perform training. In many real-world domains, it is impossible to construct a perfectly accurate model or simulator. Therefore, the performance of any policy is inevitably uncertain due to the incomplete knowledge about the environment. Furthermore, in stochastic domains, the outcome of any given run is also uncertain due to the inherent randomness of the environment. These two sources of uncertainty are usually classified as epistemic, and aleatoric uncertainty, respectively. The over-arching goal of this thesis is to contribute to developing algorithms that mitigate both sources of uncertainty in sequential decision-making problems. We make a number of contributions towards this goal, with a focus on model-based algorithms...
One Risk to Rule Them All: A Risk-Sensitive Perspective on Model-Based Offline Reinforcement Learning
Nov 30, 2022



Offline reinforcement learning (RL) is suitable for safety-critical domains where online exploration is too costly or dangerous. In safety-critical settings, decision-making should take into consideration the risk of catastrophic outcomes. In other words, decision-making should be risk-sensitive. Previous works on risk in offline RL combine together offline RL techniques, to avoid distributional shift, with risk-sensitive RL algorithms, to achieve risk-sensitivity. In this work, we propose risk-sensitivity as a mechanism to jointly address both of these issues. Our model-based approach is risk-averse to both epistemic and aleatoric uncertainty. Risk-aversion to epistemic uncertainty prevents distributional shift, as areas not covered by the dataset have high epistemic uncertainty. Risk-aversion to aleatoric uncertainty discourages actions that may result in poor outcomes due to environment stochasticity. Our experiments show that our algorithm achieves competitive performance on deterministic benchmarks, and outperforms existing approaches for risk-sensitive objectives in stochastic domains.
RAMBO-RL: Robust Adversarial Model-Based Offline Reinforcement Learning
Apr 26, 2022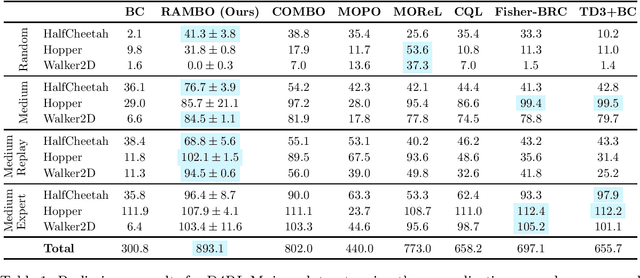
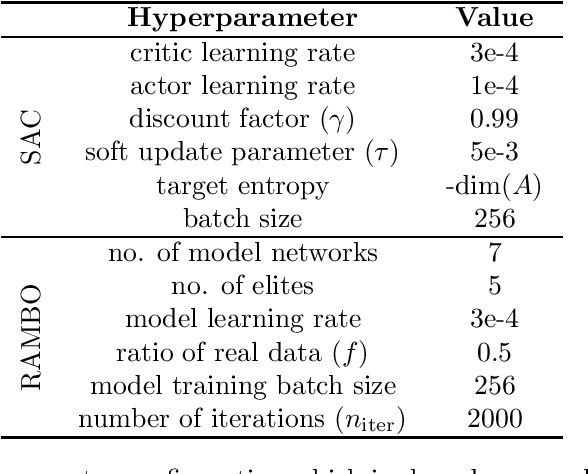

Offline reinforcement learning (RL) aims to find near-optimal policies from logged data without further environment interaction. Model-based algorithms, which learn a model of the environment from the dataset and perform conservative policy optimisation within that model, have emerged as a promising approach to this problem. In this work, we present Robust Adversarial Model-Based Offline RL (RAMBO), a novel approach to model-based offline RL. To achieve conservatism, we formulate the problem as a two-player zero sum game against an adversarial environment model. The model is trained minimise the value function while still accurately predicting the transitions in the dataset, forcing the policy to act conservatively in areas not covered by the dataset. To approximately solve the two-player game, we alternate between optimising the policy and optimising the model adversarially. The problem formulation that we address is theoretically grounded, resulting in a PAC performance guarantee and a pessimistic value function which lower bounds the value function in the true environment. We evaluate our approach on widely studied offline RL benchmarks, and demonstrate that our approach achieves state of the art performance.
Optimal Admission Control for Multiclass Queues with Time-Varying Arrival Rates via State Abstraction
Mar 14, 2022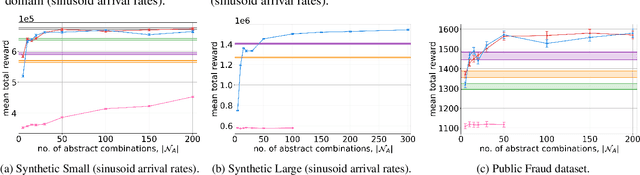
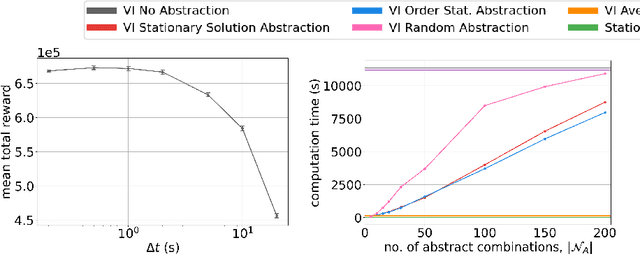
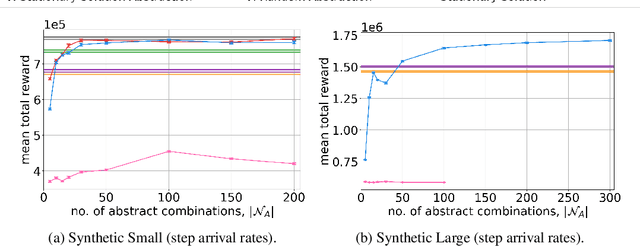
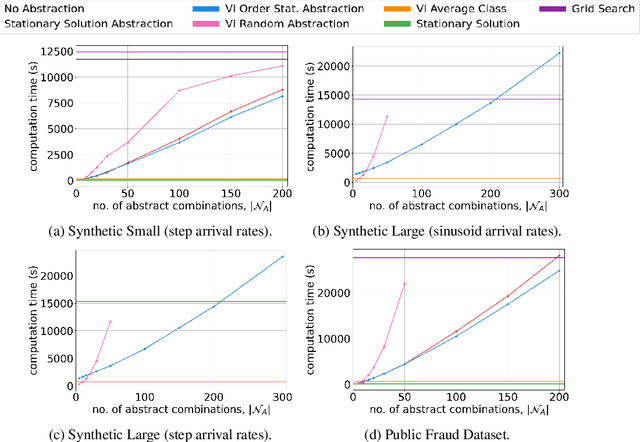
We consider a novel queuing problem where the decision-maker must choose to accept or reject randomly arriving tasks into a no buffer queue which are processed by $N$ identical servers. Each task has a price, which is a positive real number, and a class. Each class of task has a different price distribution and service rate, and arrives according to an inhomogenous Poisson process. The objective is to decide which tasks to accept so that the total price of tasks processed is maximised over a finite horizon. We formulate the problem as a discrete time Markov Decision Process (MDP) with a hybrid state space. We show that the optimal value function has a specific structure, which enables us to solve the hybrid MDP exactly. Moreover, we prove that as the time step is reduced, the discrete time solution approaches the optimal solution to the original continuous time problem. To improve the scalability of our approach to a greater number of task classes, we present an approximation based on state abstraction. We validate our approach on synthetic data, as well as a real financial fraud data set, which is the motivating application for this work.
Lexicographic Optimisation of Conditional Value at Risk and Expected Value for Risk-Averse Planning in MDPs
Oct 25, 2021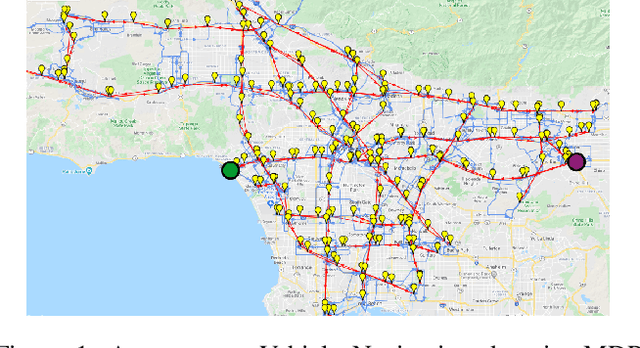
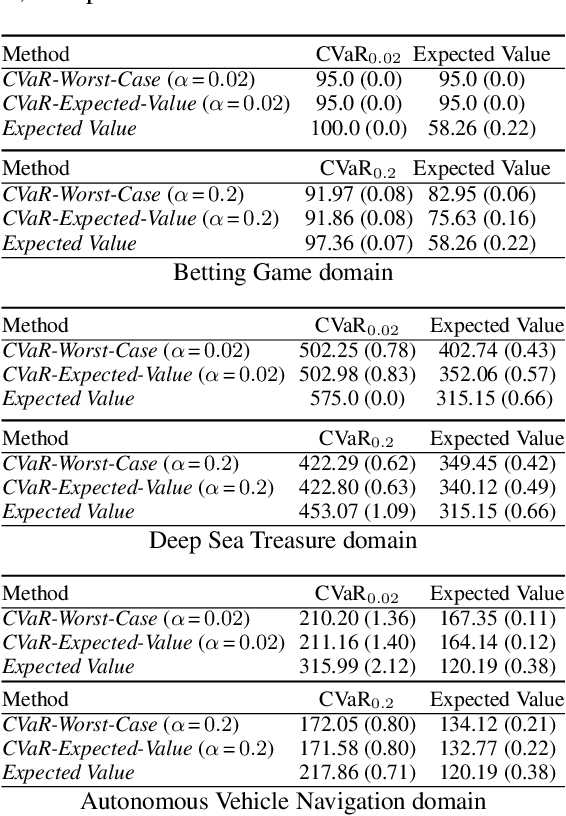
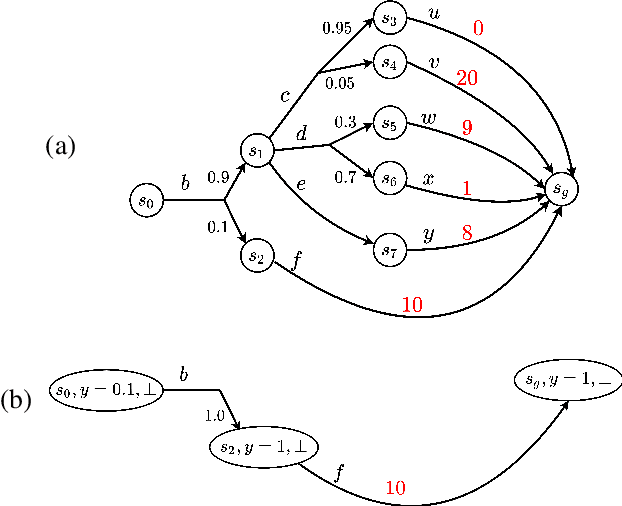
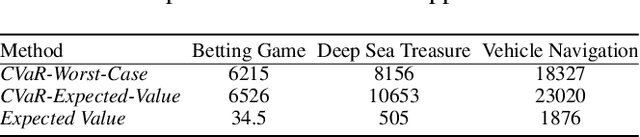
Planning in Markov decision processes (MDPs) typically optimises the expected cost. However, optimising the expectation does not consider the risk that for any given run of the MDP, the total cost received may be unacceptably high. An alternative approach is to find a policy which optimises a risk-averse objective such as conditional value at risk (CVaR). In this work, we begin by showing that there can be multiple policies which obtain the optimal CVaR. We formulate the lexicographic optimisation problem of minimising the expected cost subject to the constraint that the CVaR of the total cost is optimal. We present an algorithm for this problem and evaluate our approach on three domains, including a road navigation domain based on real traffic data. Our experimental results demonstrate that our lexicographic approach attains improved expected cost while maintaining the optimal CVaR.
Risk-Averse Bayes-Adaptive Reinforcement Learning
Feb 10, 2021
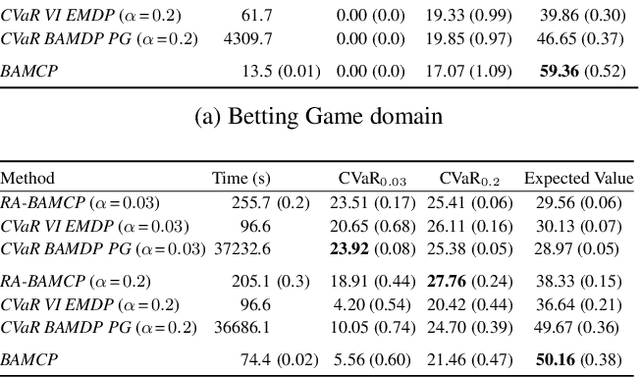
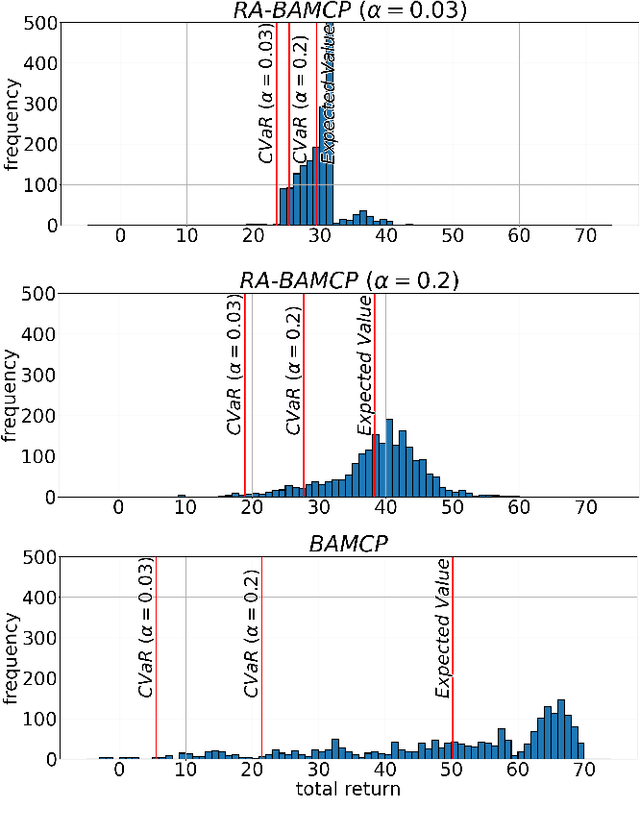

In this work, we address risk-averse Bayesadaptive reinforcement learning. We pose the problem of optimising the conditional value at risk (CVaR) of the total return in Bayes-adaptive Markov decision processes (MDPs). We show that a policy optimising CVaR in this setting is risk-averse to both the parametric uncertainty due to the prior distribution over MDPs, and the internal uncertainty due to the inherent stochasticity of MDPs. We reformulate the problem as a two-player stochastic game and propose an approximate algorithm based on Monte Carlo tree search and Bayesian optimisation. Our experiments demonstrate that our approach significantly outperforms baseline approaches for this problem.