 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAMBO-RL: Robust Adversarial Model-Based Offline Reinforcement Learning
Paper and Code
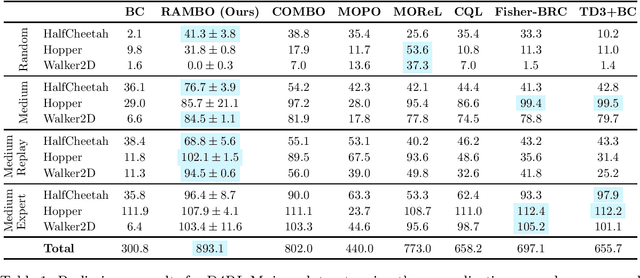

Offline reinforcement learning (RL) aims to find near-optimal policies from logged data without further environment interaction. Model-based algorithms, which learn a model of the environment from the dataset and perform conservative policy optimisation within that model, have emerged as a promising approach to this problem. In this work, we present Robust Adversarial Model-Based Offline RL (RAMBO), a novel approach to model-based offline RL. To achieve conservatism, we formulate the problem as a two-player zero sum game against an adversarial environment model. The model is trained minimise the value function while still accurately predicting the transitions in the dataset, forcing the policy to act conservatively in areas not covered by the dataset. To approximately solve the two-player game, we alternate between optimising the policy and optimising the model adversarially. The problem formulation that we address is theoretically grounded, resulting in a PAC performance guarantee and a pessimistic value function which lower bounds the value function in the true environment. We evaluate our approach on widely studied offline RL benchmarks, and demonstrate that our approach achieves state of the art performance.