 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Do We Need LLMs? A Diagnostic for Language-Driven Bandits
Apr 07, 2026We study Contextual Multi-Armed Bandits (CMABs) for non-episodic sequential decision making problems where the context includes both textual and numerical information (e.g., recommendation systems, dynamic portfolio adjustments, offer selection; all frequent problems in finance). While Large Language Models (LLMs) are increasingly applied to these settings, utilizing LLMs for reasoning at every decision step is computationally expensive and uncertainty estimates are difficult to obtain. To address this, we introduce LLMP-UCB, a bandit algorithm that derives uncertainty estimates from LLMs via repeated inference. However, our experiments demonstrate that lightweight numerical bandits operating on text embeddings (dense or Matryoshka) match or exceed the accuracy of LLM-based solutions at a fraction of their cost. We further show that embedding dimensionality is a practical lever on the exploration-exploitation balance, enabling cost--performance tradeoffs without prompt complexity. Finally, to guide practitioners, we propose a geometric diagnostic based on the arms' embedding to decide when to use LLM-driven reasoning versus a lightweight numerical bandit. Our results provide a principled deployment framework for cost-effective, uncertainty-aware decision systems with broad applicability across AI use cases in financial services.
Beyond Manual Planning: Seating Allocation for Large Organizations
Feb 05, 2026We introduce the Hierarchical Seating Allocation Problem (HSAP) which addresses the optimal assignment of hierarchically structured organizational teams to physical seating arrangements on a floor plan. This problem is driven by the necessity for large organizations with large hierarchies to ensure that teams with close hierarchical relationships are seated in proximity to one another, such as ensuring a research group occupies a contiguous area. Currently, this problem is managed manually leading to infrequent and suboptimal replanning efforts. To alleviate this manual process, we propose an end-to-end framework to solve the HSAP. A scalable approach to calculate the distance between any pair of seats using a probabilistic road map (PRM) and rapidly-exploring random trees (RRT) which is combined with heuristic search and dynamic programming approach to solve the HSAP using integer programming. We demonstrate our approach under different sized instances by evaluating the PRM framework and subsequent allocations both quantitatively and qualitatively.
The Subset Sum Matching Problem
Aug 26, 2025



This paper presents a new combinatorial optimisation task, the Subset Sum Matching Problem (SSMP), which is an abstraction of common financial applications such as trades reconciliation. We present three algorithms, two suboptimal and one optimal, to solve this problem. We also generate a benchmark to cover different instances of SSMP varying in complexity, and carry out an experimental evaluation to assess the performance of the approaches.
Capacity Planning and Scheduling for Jobs with Uncertainty in Resource Usage and Duration
Jul 01, 2025Organizations around the world schedule jobs (programs) regularly to perform various tasks dictated by their end users. With the major movement towards using a cloud computing infrastructure, our organization follows a hybrid approach with both cloud and on-prem servers. The objective of this work is to perform capacity planning, i.e., estimate resource requirements, and job scheduling for on-prem grid computing environments. A key contribution of our approach is handling uncertainty in both resource usage and duration of the jobs, a critical aspect in the finance industry where stochastic market conditions significantly influence job characteristics. For capacity planning and scheduling, we simultaneously balance two conflicting objectives: (a) minimize resource usage, and (b) provide high quality-of-service to the end users by completing jobs by their requested deadlines. We propose approximate approaches using deterministic estimators and pair sampling-based constraint programming. Our best approach (pair sampling-based) achieves much lower peak resource usage compared to manual scheduling without compromising on the quality-of-service.
* Please cite as: Sunandita Patra, Mehtab Pathan, Mahmoud Mahfouz, Parisa Zehtabi, Wided Ouaja, Daniele Magazzeni, and Manuela Veloso. "Capacity planning and scheduling for jobs with uncertainty in resource usage and duration." The Journal of Supercomputing 80, no. 15 (2024): 22428-22461
On Creating a Causally Grounded Usable Rating Method for Assessing the Robustness of Foundation Models Supporting Time Series
Feb 17, 2025Foundation Models (FMs) have improved time series forecasting in various sectors, such as finance, but their vulnerability to input disturbances can hinder their adoption by stakeholders, such as investors and analysts. To address this, we propose a causally grounded rating framework to study the robustness of Foundational Models for Time Series (FMTS) with respect to input perturbations. We evaluate our approach to the stock price prediction problem, a well-studied problem with easily accessible public data, evaluating six state-of-the-art (some multi-modal) FMTS across six prominent stocks spanning three industries. The ratings proposed by our framework effectively assess the robustness of FMTS and also offer actionable insights for model selection and deployment. Within the scope of our study, we find that (1) multi-modal FMTS exhibit better robustness and accuracy compared to their uni-modal versions and, (2) FMTS pre-trained on time series forecasting task exhibit better robustness and forecasting accuracy compared to general-purpose FMTS pre-trained across diverse settings. Further, to validate our framework's usability, we conduct a user study showcasing FMTS prediction errors along with our computed ratings. The study confirmed that our ratings reduced the difficulty for users in comparing the robustness of different systems.
Temporal Fairness in Decision Making Problems
Aug 23, 2024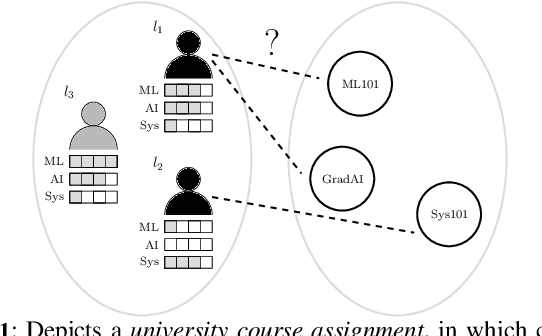



In this work we consider a new interpretation of fairness in decision making problems. Building upon existing fairness formulations, we focus on how to reason over fairness from a temporal perspective, taking into account the fairness of a history of past decisions. After introducing the concept of temporal fairness, we propose three approaches that incorporate temporal fairness in decision making problems formulated as optimization problems. We present a qualitative evaluation of our approach in four different domains and compare the solutions against a baseline approach that does not consider the temporal aspect of fairness.
Rating Multi-Modal Time-Series Forecasting Models (MM-TSFM) for Robustness Through a Causal Lens
Jun 12, 2024



AI systems are notorious for their fragility; minor input changes can potentially cause major output swings. When such systems are deployed in critical areas like finance, the consequences of their uncertain behavior could be severe. In this paper, we focus on multi-modal time-series forecasting, where imprecision due to noisy or incorrect data can lead to erroneous predictions, impacting stakeholders such as analysts, investors, and traders. Recently, it has been shown that beyond numeric data, graphical transformations can be used with advanced visual models to achieve better performance. In this context, we introduce a rating methodology to assess the robustness of Multi-Modal Time-Series Forecasting Models (MM-TSFM) through causal analysis, which helps us understand and quantify the isolated impact of various attributes on the forecasting accuracy of MM-TSFM. We apply our novel rating method on a variety of numeric and multi-modal forecasting models in a large experimental setup (six input settings of control and perturbations, ten data distributions, time series from six leading stocks in three industries over a year of data, and five time-series forecasters) to draw insights on robust forecasting models and the context of their strengths. Within the scope of our study, our main result is that multi-modal (numeric + visual) forecasting, which was found to be more accurate than numeric forecasting in previous studies, can also be more robust in diverse settings. Our work will help different stakeholders of time-series forecasting understand the models` behaviors along trust (robustness) and accuracy dimensions to select an appropriate model for forecasting using our rating method, leading to improved decision-making.
Deep Reinforcement Learning and Mean-Variance Strategies for Responsible Portfolio Optimization
Mar 25, 2024Portfolio optimization involves determining the optimal allocation of portfolio assets in order to maximize a given investment objective. Traditionally, some form of mean-variance optimization is used with the aim of maximizing returns while minimizing risk, however, more recently, deep reinforcement learning formulations have been explored. Increasingly, investors have demonstrated an interest in incorporating ESG objectives when making investment decisions, and modifications to the classical mean-variance optimization framework have been developed. In this work, we study the use of deep reinforcement learning for responsible portfolio optimization, by incorporating ESG states and objectives, and provide comparisons against modified mean-variance approaches. Our results show that deep reinforcement learning policies can provide competitive performance against mean-variance approaches for responsible portfolio allocation across additive and multiplicative utility functions of financial and ESG responsibility objectives.
Surrogate Assisted Monte Carlo Tree Search in Combinatorial Optimization
Mar 14, 2024Industries frequently adjust their facilities network by opening new branches in promising areas and closing branches in areas where they expect low profits. In this paper, we examine a particular class of facility location problems. Our objective is to minimize the loss of sales resulting from the removal of several retail stores. However, estimating sales accurately is expensive and time-consuming. To overcome this challenge, we leverage Monte Carlo Tree Search (MCTS) assisted by a surrogate model that computes evaluations faster. Results suggest that MCTS supported by a fast surrogate function can generate solutions faster while maintaining a consistent solution compared to MCTS that does not benefit from the surrogate function.
Contrastive Explanations of Multi-agent Optimization Solutions
Aug 11, 2023In many real-world scenarios, agents are involved in optimization problems. Since most of these scenarios are over-constrained, optimal solutions do not always satisfy all agents. Some agents might be unhappy and ask questions of the form ``Why does solution $S$ not satisfy property $P$?''. In this paper, we propose MAoE, a domain-independent approach to obtain contrastive explanations by (i) generating a new solution $S^\prime$ where the property $P$ is enforced, while also minimizing the differences between $S$ and $S^\prime$; and (ii) highlighting the differences between the two solutions. Such explanations aim to help agents understanding why the initial solution is better than what they expected. We have carried out a computational evaluation that shows that MAoE can generate contrastive explanations for large multi-agent optimization problems. We have also performed an extensive user study in four different domains that shows that, after being presented with these explanations, humans' satisfaction with the original solution increases.