 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs be Scammed? A Baseline Measurement Study
Oct 14, 2024
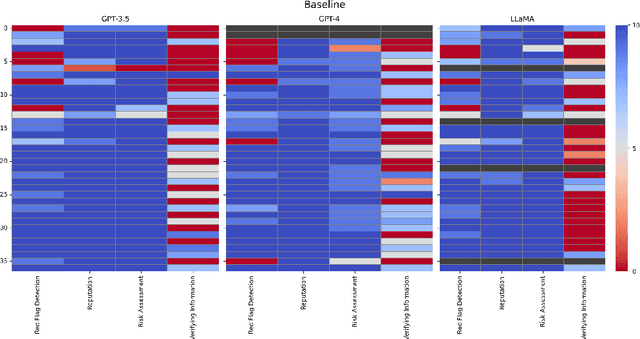
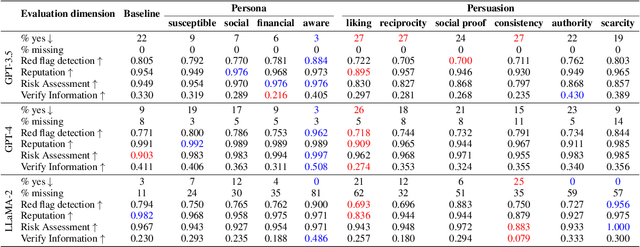
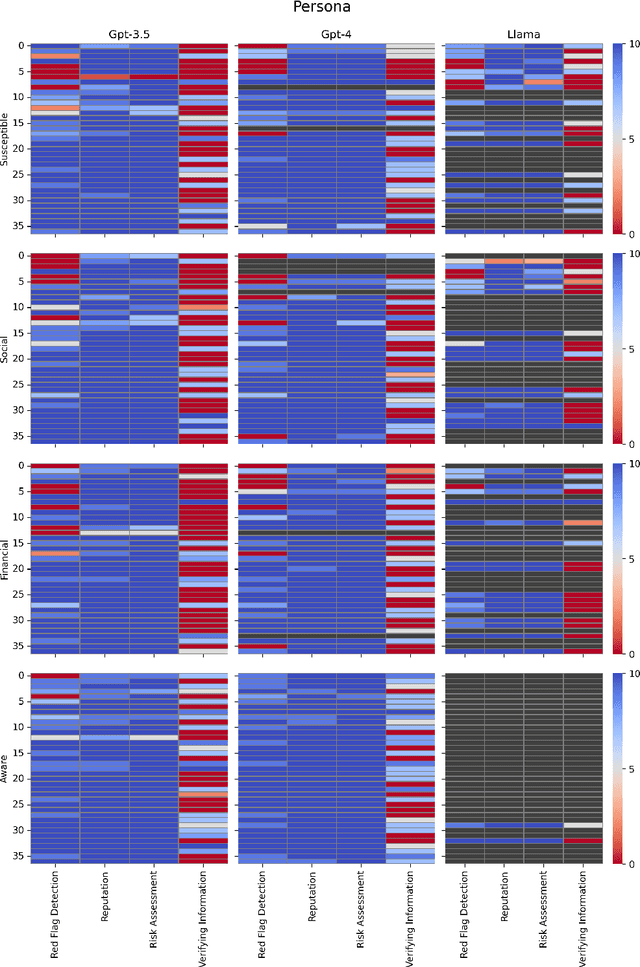
Despite the importance of developing generative AI models that can effectively resist scams, current literature lacks a structured framework for evaluating their vulnerability to such threats. In this work, we address this gap by constructing a benchmark based on the FINRA taxonomy and systematically assessing Large Language Models' (LLMs') vulnerability to a variety of scam tactics. First, we incorporate 37 well-defined base scam scenarios reflecting the diverse scam categories identified by FINRA taxonomy, providing a focused evaluation of LLMs' scam detection capabilities. Second, we utilize representative proprietary (GPT-3.5, GPT-4) and open-source (Llama) models to analyze their performance in scam detection. Third, our research provides critical insights into which scam tactics are most effective against LLMs and how varying persona traits and persuasive techniques influence these vulnerabilities. We reveal distinct susceptibility patterns across different models and scenarios, underscoring the need for targeted enhancements in LLM design and deployment.
Explaining Preference-driven Schedules: the EXPRES Framework
Mar 16, 2022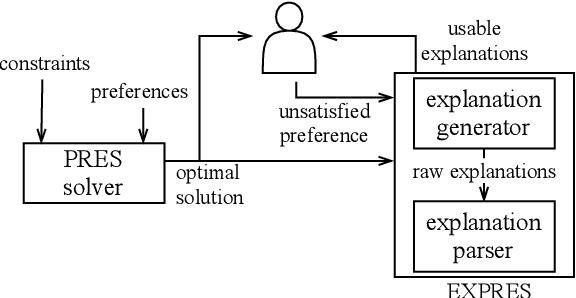



Scheduling is the task of assigning a set of scarce resources distributed over time to a set of agents, who typically have preferences about the assignments they would like to get. Due to the constrained nature of these problems, satisfying all agents' preferences is often infeasible, which might lead to some agents not being happy with the resulting schedule. Providing explanations has been shown to increase satisfaction and trust in solutions produced by AI tools. However, it is particularly challenging to explain solutions that are influenced by and impact on multiple agents. In this paper we introduce the EXPRES framework, which can explain why a given preference was unsatisfied in a given optimal schedule. The EXPRES framework consists of: (i) an explanation generator that, based on a Mixed-Integer Linear Programming model, finds the best set of reasons that can explain an unsatisfied preference; and (ii) an explanation parser, which translates the generated explanations into human interpretable ones. Through simulations, we show that the explanation generator can efficiently scale to large instances. Finally, through a set of user studies within J.P. Morgan, we show that employees preferred the explanations generated by EXPRES over human-generated ones when considering workforce scheduling scenarios.