 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs be Scammed? A Baseline Measurement Study
Paper and Code
Oct 14, 2024
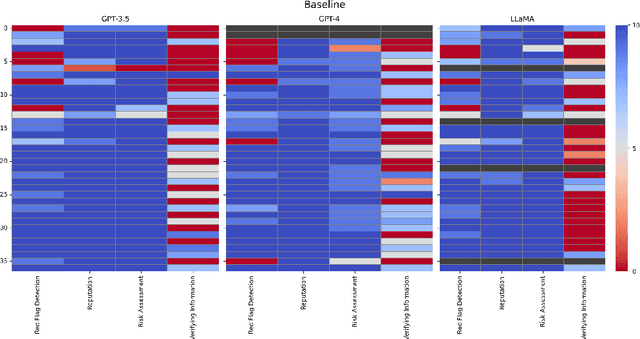
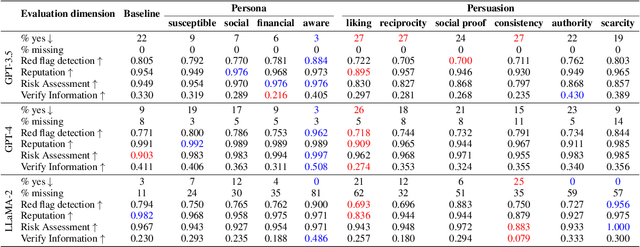
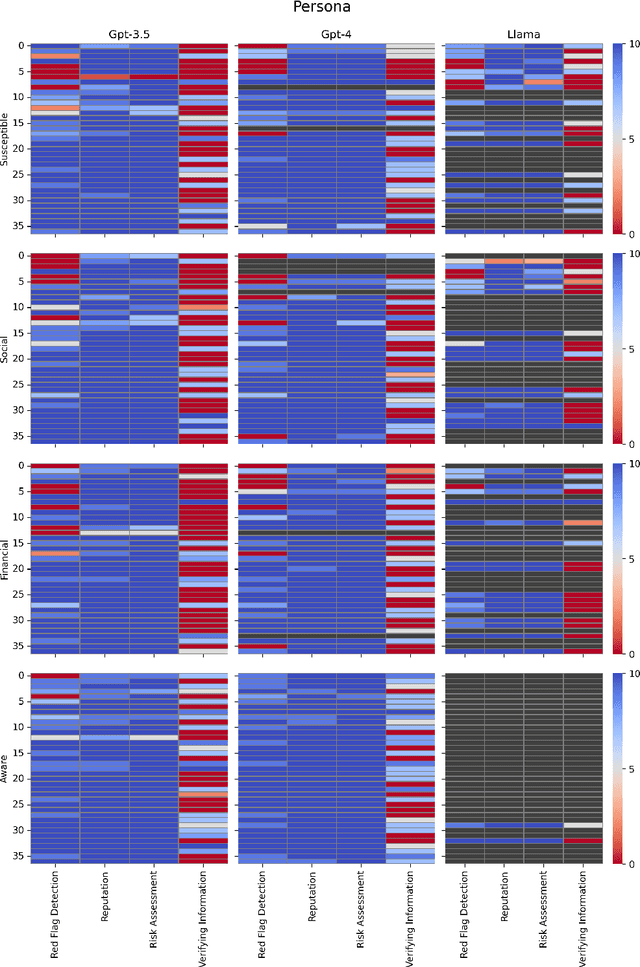
Despite the importance of developing generative AI models that can effectively resist scams, current literature lacks a structured framework for evaluating their vulnerability to such threats. In this work, we address this gap by constructing a benchmark based on the FINRA taxonomy and systematically assessing Large Language Models' (LLMs') vulnerability to a variety of scam tactics. First, we incorporate 37 well-defined base scam scenarios reflecting the diverse scam categories identified by FINRA taxonomy, providing a focused evaluation of LLMs' scam detection capabilities. Second, we utilize representative proprietary (GPT-3.5, GPT-4) and open-source (Llama) models to analyze their performance in scam detection. Third, our research provides critical insights into which scam tactics are most effective against LLMs and how varying persona traits and persuasive techniques influence these vulnerabilities. We reveal distinct susceptibility patterns across different models and scenarios, underscoring the need for targeted enhancements in LLM design and deployment.