 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Linear Coregionalization for Realistic Synthetic Multivariate Time Series
Apr 06, 2026Synthetic data is essential for training foundation models for time series (FMTS), but most generators assume static correlations, and are typically missing realistic inter-channel dependencies. We introduce DynLMC, a Dynamic Linear Model of Coregionalization, that incorporates time-varying, regime-switching correlations and cross-channel lag structures. Our approach produces synthetic multivariate time series with correlation dynamics that closely resemble real data. Fine-tuning three foundational models on DynLMC-generated data yields consistent zero-shot forecasting improvements across nine benchmarks. Our results demonstrate that modeling dynamic inter-channel correlations enhances FMTS transferability, highlighting the importance of data-centric pretraining.
Beyond Manual Planning: Seating Allocation for Large Organizations
Feb 05, 2026We introduce the Hierarchical Seating Allocation Problem (HSAP) which addresses the optimal assignment of hierarchically structured organizational teams to physical seating arrangements on a floor plan. This problem is driven by the necessity for large organizations with large hierarchies to ensure that teams with close hierarchical relationships are seated in proximity to one another, such as ensuring a research group occupies a contiguous area. Currently, this problem is managed manually leading to infrequent and suboptimal replanning efforts. To alleviate this manual process, we propose an end-to-end framework to solve the HSAP. A scalable approach to calculate the distance between any pair of seats using a probabilistic road map (PRM) and rapidly-exploring random trees (RRT) which is combined with heuristic search and dynamic programming approach to solve the HSAP using integer programming. We demonstrate our approach under different sized instances by evaluating the PRM framework and subsequent allocations both quantitatively and qualitatively.
Deep Reinforcement Learning and Mean-Variance Strategies for Responsible Portfolio Optimization
Mar 25, 2024Portfolio optimization involves determining the optimal allocation of portfolio assets in order to maximize a given investment objective. Traditionally, some form of mean-variance optimization is used with the aim of maximizing returns while minimizing risk, however, more recently, deep reinforcement learning formulations have been explored. Increasingly, investors have demonstrated an interest in incorporating ESG objectives when making investment decisions, and modifications to the classical mean-variance optimization framework have been developed. In this work, we study the use of deep reinforcement learning for responsible portfolio optimization, by incorporating ESG states and objectives, and provide comparisons against modified mean-variance approaches. Our results show that deep reinforcement learning policies can provide competitive performance against mean-variance approaches for responsible portfolio allocation across additive and multiplicative utility functions of financial and ESG responsibility objectives.
Rethinking Log Odds: Linear Probability Modelling and Expert Advice in Interpretable Machine Learning
Nov 11, 2022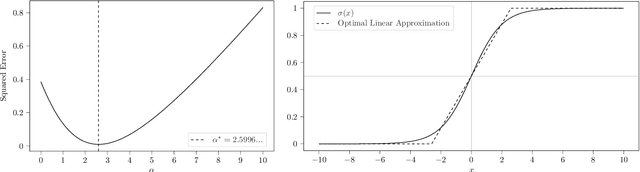

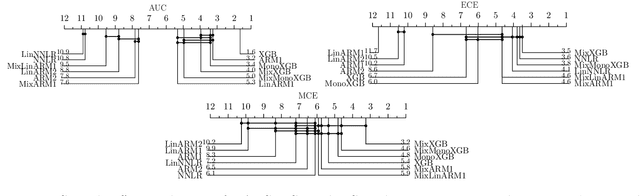

We introduce a family of interpretable machine learning models, with two broad additions: Linearised Additive Models (LAMs) which replace the ubiquitous logistic link function in General Additive Models (GAMs); and SubscaleHedge, an expert advice algorithm for combining base models trained on subsets of features called subscales. LAMs can augment any additive binary classification model equipped with a sigmoid link function. Moreover, they afford direct global and local attributions of additive components to the model output in probability space. We argue that LAMs and SubscaleHedge improve the interpretability of their base algorithms. Using rigorous null-hypothesis significance testing on a broad suite of financial modelling data, we show that our algorithms do not suffer from large performance penalties in terms of ROC-AUC and calibration.
Towards learning to explain with concept bottleneck models: mitigating information leakage
Nov 07, 2022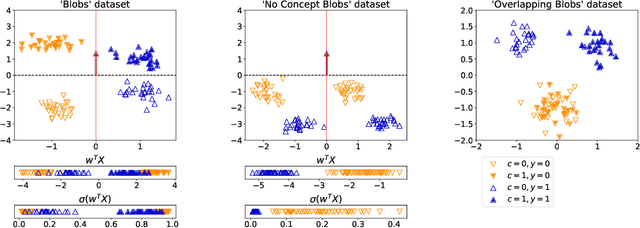
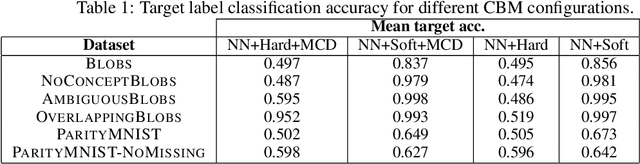
Concept bottleneck models perform classification by first predicting which of a list of human provided concepts are true about a datapoint. Then a downstream model uses these predicted concept labels to predict the target label. The predicted concepts act as a rationale for the target prediction. Model trust issues emerge in this paradigm when soft concept labels are used: it has previously been observed that extra information about the data distribution leaks into the concept predictions. In this work we show how Monte-Carlo Dropout can be used to attain soft concept predictions that do not contain leaked information.