 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Creating a Causally Grounded Usable Rating Method for Assessing the Robustness of Foundation Models Supporting Time Series
Feb 17, 2025Foundation Models (FMs) have improved time series forecasting in various sectors, such as finance, but their vulnerability to input disturbances can hinder their adoption by stakeholders, such as investors and analysts. To address this, we propose a causally grounded rating framework to study the robustness of Foundational Models for Time Series (FMTS) with respect to input perturbations. We evaluate our approach to the stock price prediction problem, a well-studied problem with easily accessible public data, evaluating six state-of-the-art (some multi-modal) FMTS across six prominent stocks spanning three industries. The ratings proposed by our framework effectively assess the robustness of FMTS and also offer actionable insights for model selection and deployment. Within the scope of our study, we find that (1) multi-modal FMTS exhibit better robustness and accuracy compared to their uni-modal versions and, (2) FMTS pre-trained on time series forecasting task exhibit better robustness and forecasting accuracy compared to general-purpose FMTS pre-trained across diverse settings. Further, to validate our framework's usability, we conduct a user study showcasing FMTS prediction errors along with our computed ratings. The study confirmed that our ratings reduced the difficulty for users in comparing the robustness of different systems.
Rating Multi-Modal Time-Series Forecasting Models (MM-TSFM) for Robustness Through a Causal Lens
Jun 12, 2024



AI systems are notorious for their fragility; minor input changes can potentially cause major output swings. When such systems are deployed in critical areas like finance, the consequences of their uncertain behavior could be severe. In this paper, we focus on multi-modal time-series forecasting, where imprecision due to noisy or incorrect data can lead to erroneous predictions, impacting stakeholders such as analysts, investors, and traders. Recently, it has been shown that beyond numeric data, graphical transformations can be used with advanced visual models to achieve better performance. In this context, we introduce a rating methodology to assess the robustness of Multi-Modal Time-Series Forecasting Models (MM-TSFM) through causal analysis, which helps us understand and quantify the isolated impact of various attributes on the forecasting accuracy of MM-TSFM. We apply our novel rating method on a variety of numeric and multi-modal forecasting models in a large experimental setup (six input settings of control and perturbations, ten data distributions, time series from six leading stocks in three industries over a year of data, and five time-series forecasters) to draw insights on robust forecasting models and the context of their strengths. Within the scope of our study, our main result is that multi-modal (numeric + visual) forecasting, which was found to be more accurate than numeric forecasting in previous studies, can also be more robust in diverse settings. Our work will help different stakeholders of time-series forecasting understand the models` behaviors along trust (robustness) and accuracy dimensions to select an appropriate model for forecasting using our rating method, leading to improved decision-making.
The Effect of Human v/s Synthetic Test Data and Round-tripping on Assessment of Sentiment Analysis Systems for Bias
Jan 15, 2024Sentiment Analysis Systems (SASs) are data-driven Artificial Intelligence (AI) systems that output polarity and emotional intensity when given a piece of text as input. Like other AIs, SASs are also known to have unstable behavior when subjected to changes in data which can make it problematic to trust out of concerns like bias when AI works with humans and data has protected attributes like gender, race, and age. Recently, an approach was introduced to assess SASs in a blackbox setting without training data or code, and rating them for bias using synthetic English data. We augment it by introducing two human-generated chatbot datasets and also consider a round-trip setting of translating the data from one language to the same through an intermediate language. We find that these settings show SASs performance in a more realistic light. Specifically, we find that rating SASs on the chatbot data showed more bias compared to the synthetic data, and round-tripping using Spanish and Danish as intermediate languages reduces the bias (up to 68% reduction) in human-generated data while, in synthetic data, it takes a surprising turn by increasing the bias! Our findings will help researchers and practitioners refine their SAS testing strategies and foster trust as SASs are considered part of more mission-critical applications for global use.
* arXiv admin note: text overlap with arXiv:2302.02038
Advances in Automatically Rating the Trustworthiness of Text Processing Services
Feb 04, 2023



AI services are known to have unstable behavior when subjected to changes in data, models or users. Such behaviors, whether triggered by omission or commission, lead to trust issues when AI works with humans. The current approach of assessing AI services in a black box setting, where the consumer does not have access to the AI's source code or training data, is limited. The consumer has to rely on the AI developer's documentation and trust that the system has been built as stated. Further, if the AI consumer reuses the service to build other services which they sell to their customers, the consumer is at the risk of the service providers (both data and model providers). Our approach, in this context, is inspired by the success of nutritional labeling in food industry to promote health and seeks to assess and rate AI services for trust from the perspective of an independent stakeholder. The ratings become a means to communicate the behavior of AI systems so that the consumer is informed about the risks and can make an informed decision. In this paper, we will first describe recent progress in developing rating methods for text-based machine translator AI services that have been found promising with user studies. Then, we will outline challenges and vision for a principled, multi-modal, causality-based rating methodologies and its implication for decision-support in real-world scenarios like health and food recommendation.
Rating Sentiment Analysis Systems for Bias through a Causal Lens
Feb 04, 2023Sentiment Analysis Systems (SASs) are data-driven Artificial Intelligence (AI) systems that, given a piece of text, assign one or more numbers conveying the polarity and emotional intensity expressed in the input. Like other automatic machine learning systems, they have also been known to exhibit model uncertainty where a (small) change in the input leads to drastic swings in the output. This can be especially problematic when inputs are related to protected features like gender or race since such behavior can be perceived as a lack of fairness, i.e., bias. We introduce a novel method to assess and rate SASs where inputs are perturbed in a controlled causal setting to test if the output sentiment is sensitive to protected variables even when other components of the textual input, e.g., chosen emotion words, are fixed. We then use the result to assign labels (ratings) at fine-grained and overall levels to convey the robustness of the SAS to input changes. The ratings serve as a principled basis to compare SASs and choose among them based on behavior. It benefits all users, especially developers who reuse off-the-shelf SASs to build larger AI systems but do not have access to their code or training data to compare.
Learning LWF Chain Graphs: A Markov Blanket Discovery Approach
May 29, 2020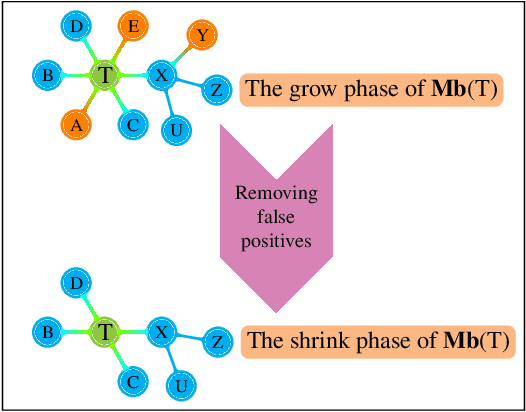
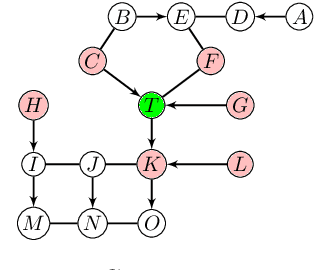
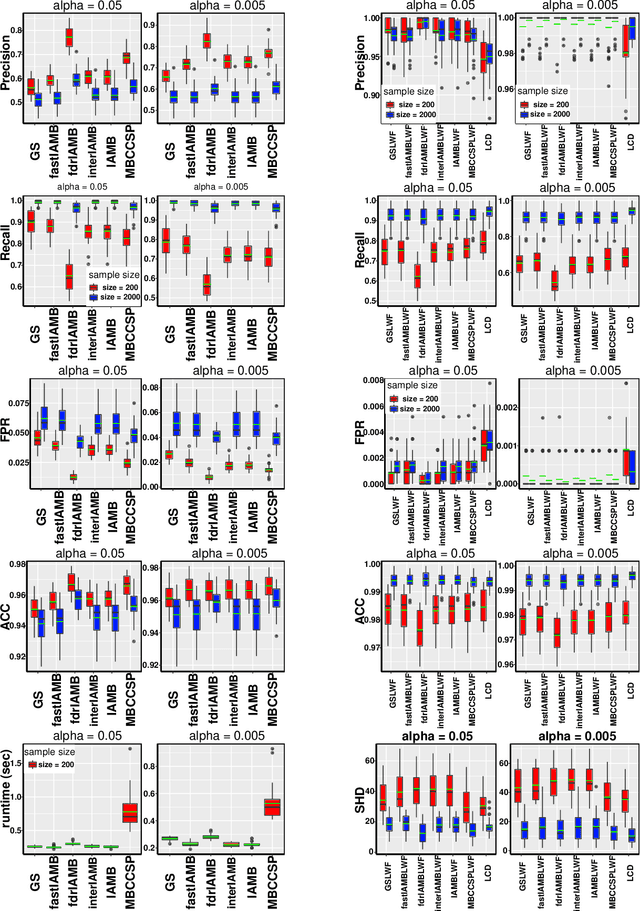
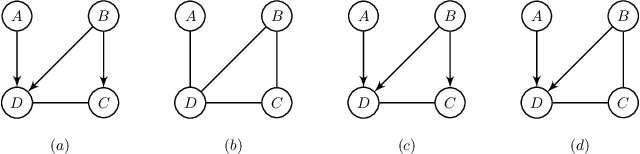
This paper provides a graphical characterization of Markov blankets in chain graphs (CGs) under the Lauritzen-Wermuth-Frydenberg (LWF) interpretation. The characterization is different from the well-known one for Bayesian networks and generalizes it. We provide a novel scalable and sound algorithm for Markov blanket discovery in LWF CGs and prove that the Grow-Shrink algorithm, the IAMB algorithm, and its variants are still correct for Markov blanket discovery in LWF CGs under the same assumptions as for Bayesian networks. We provide a sound and scalable constraint-based framework for learning the structure of LWF CGs from faithful causally sufficient data and prove its correctness when the Markov blanket discovery algorithms in this paper are used. Our proposed algorithms compare positively/competitively against the state-of-the-art LCD (Learn Chain graphs via Decomposition) algorithm, depending on the algorithm that is used for Markov blanket discovery. Our proposed algorithms make a broad range of inference/learning problems computationally tractable and more reliable because they exploit locality.
Learning LWF Chain Graphs: an Order Independent Algorithm
May 27, 2020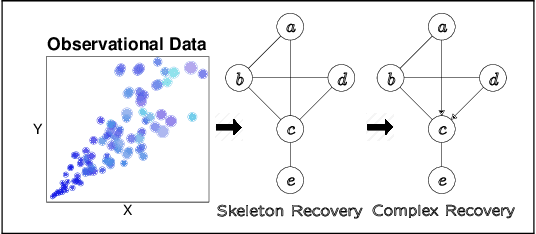
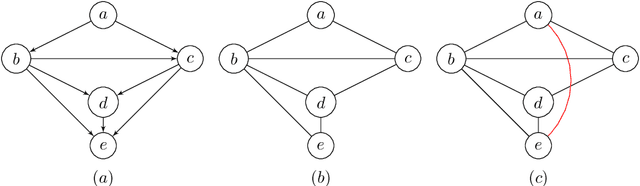
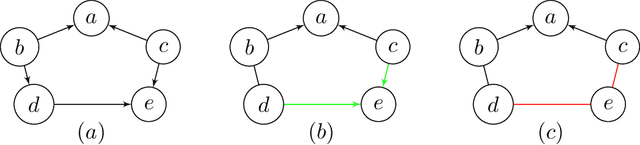
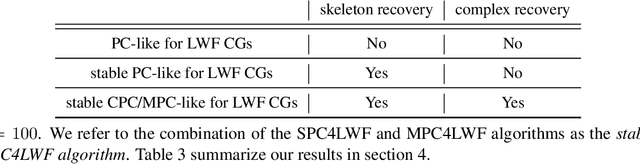
LWF chain graphs combine directed acyclic graphs and undirected graphs. We present a PC-like algorithm that finds the structure of chain graphs under the faithfulness assumption to resolve the problem of scalability of the proposed algorithm by Studeny (1997). We prove that our PC-like algorithm is order dependent, in the sense that the output can depend on the order in which the variables are given. This order dependence can be very pronounced in high-dimensional settings. We propose two modifications of the PC-like algorithm that remove part or all of this order dependence. Simulation results under a variety of settings demonstrate the competitive performance of the PC-like algorithms in comparison with the decomposition-based method, called LCD algorithm, proposed by Ma et al. (2008) in low-dimensional settings and improved performance in high-dimensional settings.
AMP Chain Graphs: Minimal Separators and Structure Learning Algorithms
Feb 24, 2020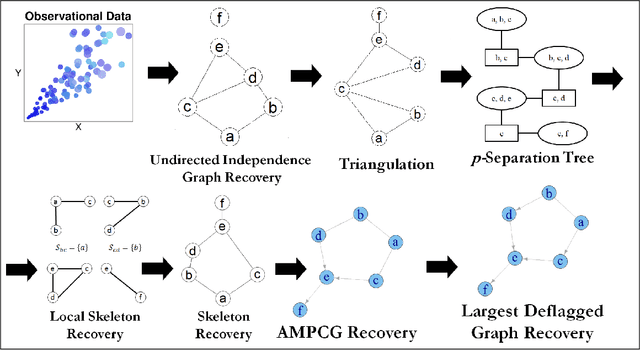

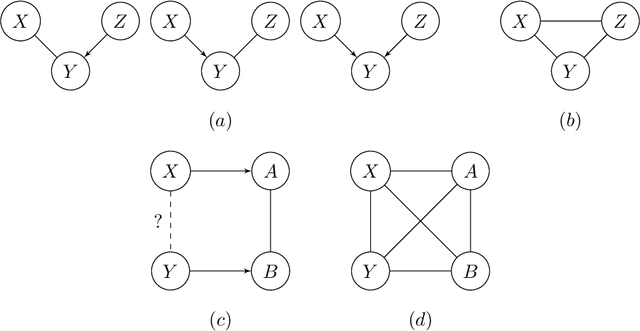
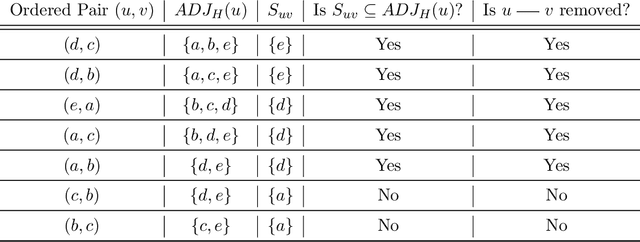
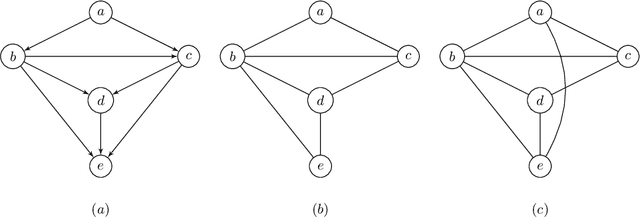
We address the problem of finding a minimal separator in an Andersson-Madigan-Perlman chain graph (AMP CG), namely, finding a set Z of nodes that separate a given non-adjacent pair of nodes such that no proper subset of Z separates that pair. We analyze several versions of this problem and offer polynomial-time algorithms for each. These include finding a minimal separator from a restricted set of nodes, finding a minimal separator for two given disjoint sets, and testing whether a given separator is minimal. We provide an extension of the decomposition approach for learning Bayesian networks (BNs) proposed by (Xie et. al.) to learn AMP CGs, which include BNs as a special case, under the faithfulness assumption and prove its correctness using the minimal separator results. The advantages of this decomposition approach hold in the more general setting: reduced complexity and increased power of computational independence tests. In addition, we show that the PC-like algorithm is order-dependent, in the sense that the output can depend on the order in which the variables are given. We propose two modifications of the PC-like algorithm that remove part or all of this order-dependence. Simulations under a variety of settings demonstrate the competitive performance of our decomposition-based method, called LCD-AMP, in comparison with the (modified version of) PC-like algorithm. In fact, the decomposition-based algorithm usually outperforms the PC-like algorithm. We empirically show that the results of both algorithms are more accurate and stable when the sample size is reasonably large and the underlying graph is sparse.
Order-Independent Structure Learning of Multivariate Regression Chain Graphs
Oct 01, 2019

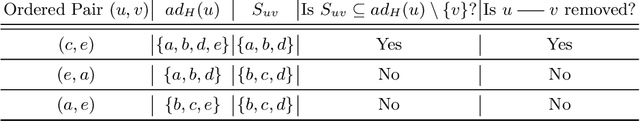
This paper deals with multivariate regression chain graphs (MVR CGs), which were introduced by Cox and Wermuth [3,4] to represent linear causal models with correlated errors. We consider the PC-like algorithm for structure learning of MVR CGs, which is a constraint-based method proposed by Sonntag and Pe\~{n}a in [18]. We show that the PC-like algorithm is order-dependent, in the sense that the output can depend on the order in which the variables are given. This order-dependence is a minor issue in low-dimensional settings. However, it can be very pronounced in high-dimensional settings, where it can lead to highly variable results. We propose two modifications of the PC-like algorithm that remove part or all of this order-dependence. Simulations under a variety of settings demonstrate the competitive performance of our algorithms in comparison with the original PC-like algorithm in low-dimensional settings and improved performance in high-dimensional settings.
Transfer Learning for Performance Modeling of Configurable Systems: A Causal Analysis
Feb 26, 2019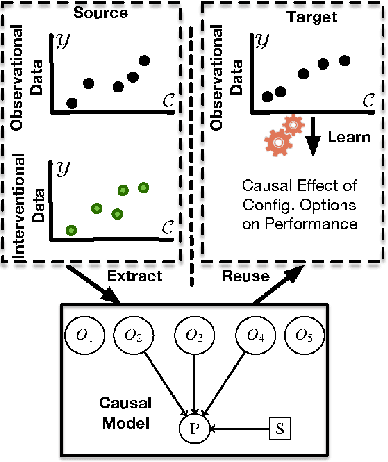

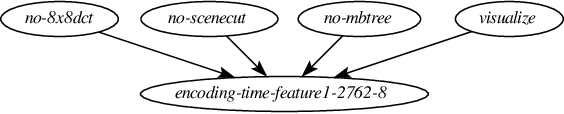
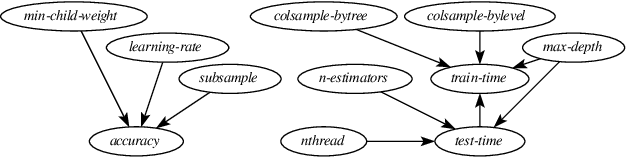
Modern systems (e.g., deep neural networks, big data analytics, and compilers) are highly configurable, which means they expose different performance behavior under different configurations. The fundamental challenge is that one cannot simply measure all configurations due to the sheer size of the configuration space. Transfer learning has been used to reduce the measurement efforts by transferring knowledge about performance behavior of systems across environments. Previously, research has shown that statistical models are indeed transferable across environments. In this work, we investigate identifiability and transportability of causal effects and statistical relations in highly-configurable systems. Our causal analysis agrees with previous exploratory analysis \cite{Jamshidi17} and confirms that the causal effects of configuration options can be carried over across environments with high confidence. We expect that the ability to carry over causal relations will enable effective performance analysis of highly-configurable systems.