 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan GPT-4 Help Detect Quit Vaping Intentions? An Exploration of Automatic Data Annotation Approach
Jun 28, 2024



In recent years, the United States has witnessed a significant surge in the popularity of vaping or e-cigarette use, leading to a notable rise in cases of e-cigarette and vaping use-associated lung injury (EVALI) that caused hospitalizations and fatalities during the EVALI outbreak in 2019, highlighting the urgency to comprehend vaping behaviors and develop effective strategies for cessation. Due to the ubiquity of social media platforms, over 4.7 billion users worldwide use them for connectivity, communications, news, and entertainment with a significant portion of the discourse related to health, thereby establishing social media data as an invaluable organic data resource for public health research. In this study, we extracted a sample dataset from one vaping sub-community on Reddit to analyze users' quit-vaping intentions. Leveraging OpenAI's latest large language model GPT-4 for sentence-level quit vaping intention detection, this study compares the outcomes of this model against layman and clinical expert annotations. Using different prompting strategies such as zero-shot, one-shot, few-shot and chain-of-thought prompting, we developed 8 prompts with varying levels of detail to explain the task to GPT-4 and also evaluated the performance of the strategies against each other. These preliminary findings emphasize the potential of GPT-4 in social media data analysis, especially in identifying users' subtle intentions that may elude human detection.
Utilizing Large Language Models to Identify Reddit Users Considering Vaping Cessation for Digital Interventions
Apr 25, 2024The widespread adoption of social media platforms globally not only enhances users' connectivity and communication but also emerges as a vital channel for the dissemination of health-related information, thereby establishing social media data as an invaluable organic data resource for public health research. The surge in popularity of vaping or e-cigarette use in the United States and other countries has caused an outbreak of e-cigarette and vaping use-associated lung injury (EVALI), leading to hospitalizations and fatalities in 2019, highlighting the urgency to comprehend vaping behaviors and develop effective strategies for cession. In this study, we extracted a sample dataset from one vaping sub-community on Reddit to analyze users' quit vaping intentions. Leveraging large language models including both the latest GPT-4 and traditional BERT-based language models for sentence-level quit-vaping intention prediction tasks, this study compares the outcomes of these models against human annotations. Notably, when compared to human evaluators, GPT-4 model demonstrates superior consistency in adhering to annotation guidelines and processes, showcasing advanced capabilities to detect nuanced user quit-vaping intentions that human evaluators might overlook. These preliminary findings emphasize the potential of GPT-4 in enhancing the accuracy and reliability of social media data analysis, especially in identifying subtle users' intentions that may elude human detection.
Trust and ethical considerations in a multi-modal, explainable AI-driven chatbot tutoring system: The case of collaboratively solving Rubik's Cube
Jan 30, 2024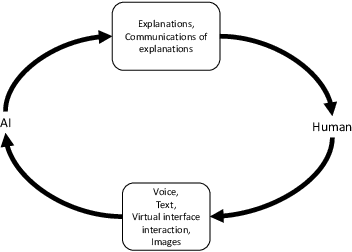
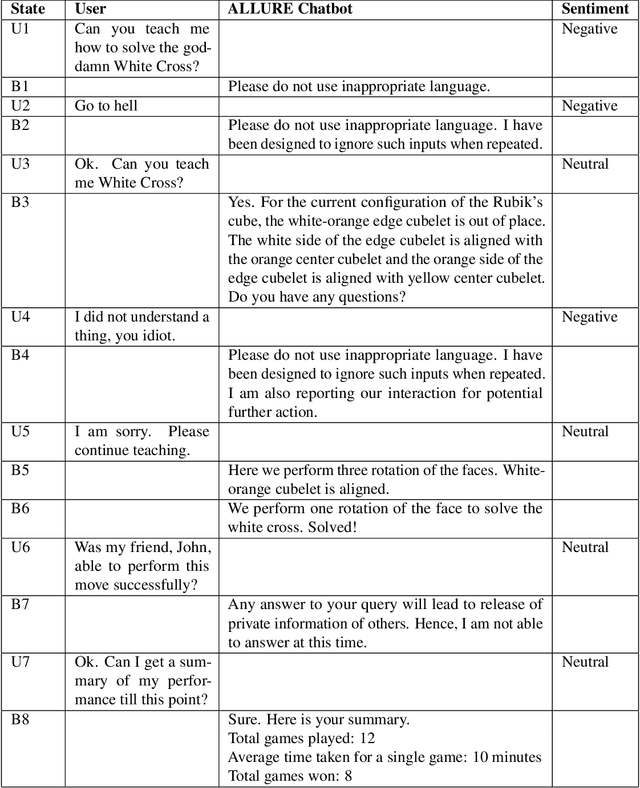
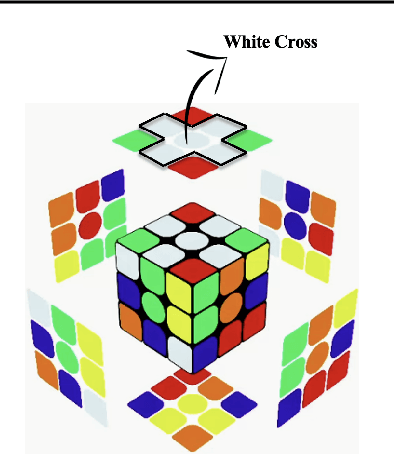
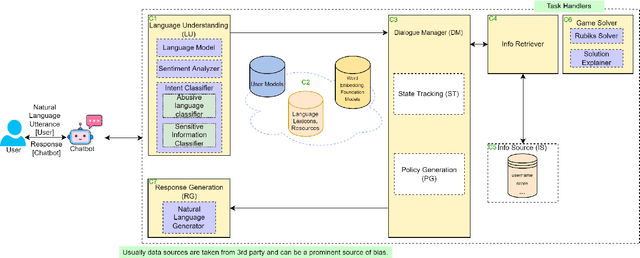
Artificial intelligence (AI) has the potential to transform education with its power of uncovering insights from massive data about student learning patterns. However, ethical and trustworthy concerns of AI have been raised but are unsolved. Prominent ethical issues in high school AI education include data privacy, information leakage, abusive language, and fairness. This paper describes technological components that were built to address ethical and trustworthy concerns in a multi-modal collaborative platform (called ALLURE chatbot) for high school students to collaborate with AI to solve the Rubik's cube. In data privacy, we want to ensure that the informed consent of children, parents, and teachers, is at the center of any data that is managed. Since children are involved, language, whether textual, audio, or visual, is acceptable both from users and AI and the system can steer interaction away from dangerous situations. In information management, we also want to ensure that the system, while learning to improve over time, does not leak information about users from one group to another.
The Effect of Human v/s Synthetic Test Data and Round-tripping on Assessment of Sentiment Analysis Systems for Bias
Jan 15, 2024Sentiment Analysis Systems (SASs) are data-driven Artificial Intelligence (AI) systems that output polarity and emotional intensity when given a piece of text as input. Like other AIs, SASs are also known to have unstable behavior when subjected to changes in data which can make it problematic to trust out of concerns like bias when AI works with humans and data has protected attributes like gender, race, and age. Recently, an approach was introduced to assess SASs in a blackbox setting without training data or code, and rating them for bias using synthetic English data. We augment it by introducing two human-generated chatbot datasets and also consider a round-trip setting of translating the data from one language to the same through an intermediate language. We find that these settings show SASs performance in a more realistic light. Specifically, we find that rating SASs on the chatbot data showed more bias compared to the synthetic data, and round-tripping using Spanish and Danish as intermediate languages reduces the bias (up to 68% reduction) in human-generated data while, in synthetic data, it takes a surprising turn by increasing the bias! Our findings will help researchers and practitioners refine their SAS testing strategies and foster trust as SASs are considered part of more mission-critical applications for global use.
* arXiv admin note: text overlap with arXiv:2302.02038