 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Coupled with Metacognition Can Outperform Reasoning Models
Aug 25, 2025Large language models (LLMs) excel in speed and adaptability across various reasoning tasks, but they often struggle when strict logic or constraint enforcement is required. In contrast, Large Reasoning Models (LRMs) are specifically designed for complex, step-by-step reasoning, although they come with significant computational costs and slower inference times. To address these trade-offs, we employ and generalize the SOFAI (Slow and Fast AI) cognitive architecture into SOFAI-LM, which coordinates a fast LLM with a slower but more powerful LRM through metacognition. The metacognitive module actively monitors the LLM's performance and provides targeted, iterative feedback with relevant examples. This enables the LLM to progressively refine its solutions without requiring the need for additional model fine-tuning. Extensive experiments on graph coloring and code debugging problems demonstrate that our feedback-driven approach significantly enhances the problem-solving capabilities of the LLM. In many instances, it achieves performance levels that match or even exceed those of standalone LRMs while requiring considerably less time. Additionally, when the LLM and feedback mechanism alone are insufficient, we engage the LRM by providing appropriate information collected during the LLM's feedback loop, tailored to the specific characteristics of the problem domain and leads to improved overall performance. Evaluations on two contrasting domains: graph coloring, requiring globally consistent solutions, and code debugging, demanding localized fixes, demonstrate that SOFAI-LM enables LLMs to match or outperform standalone LRMs in accuracy while maintaining significantly lower inference time.
A Neurosymbolic Fast and Slow Architecture for Graph Coloring
Dec 02, 2024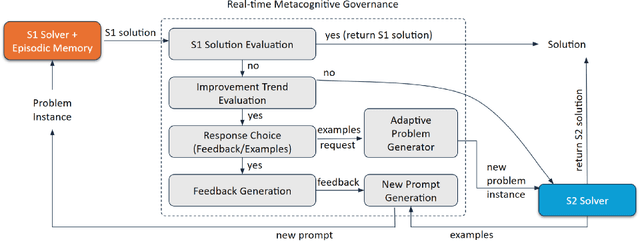


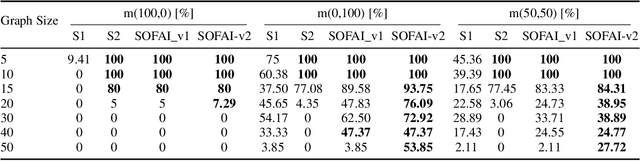
Constraint Satisfaction Problems (CSPs) present significant challenges to artificial intelligence due to their intricate constraints and the necessity for precise solutions. Existing symbolic solvers are often slow, and prior research has shown that Large Language Models (LLMs) alone struggle with CSPs because of their complexity. To bridge this gap, we build upon the existing SOFAI architecture (or SOFAI-v1), which adapts Daniel Kahneman's ''Thinking, Fast and Slow'' cognitive model to AI. Our enhanced architecture, SOFAI-v2, integrates refined metacognitive governance mechanisms to improve adaptability across complex domains, specifically tailored for solving CSPs like graph coloring. SOFAI-v2 combines a fast System 1 (S1) based on LLMs with a deliberative System 2 (S2) governed by a metacognition module. S1's initial solutions, often limited by non-adherence to constraints, are enhanced through metacognitive governance, which provides targeted feedback and examples to adapt S1 to CSP requirements. If S1 fails to solve the problem, metacognition strategically invokes S2, ensuring accurate and reliable solutions. With empirical results, we show that SOFAI-v2 for graph coloring problems achieves a 16.98% increased success rate and is 32.42% faster than symbolic solvers.
PDDLFuse: A Tool for Generating Diverse Planning Domains
Nov 29, 2024Various real-world challenges require planning algorithms that can adapt to a broad range of domains. Traditionally, the creation of planning domains has relied heavily on human implementation, which limits the scale and diversity of available domains. While recent advancements have leveraged generative AI technologies such as large language models (LLMs) for domain creation, these efforts have predominantly focused on translating existing domains from natural language descriptions rather than generating novel ones. In contrast, the concept of domain randomization, which has been highly effective in reinforcement learning, enhances performance and generalizability by training on a diverse array of randomized new domains. Inspired by this success, our tool, PDDLFuse, aims to bridge this gap in Planning Domain Definition Language (PDDL). PDDLFuse is designed to generate new, diverse planning domains that can be used to validate new planners or test foundational planning models. We have developed methods to adjust the domain generators parameters to modulate the difficulty of the domains it generates. This adaptability is crucial as existing domain-independent planners often struggle with more complex problems. Initial tests indicate that PDDLFuse efficiently creates intricate and varied domains, representing a significant advancement over traditional domain generation methods and making a contribution towards planning research.
A Domain-Agnostic Neurosymbolic Approach for Big Social Data Analysis: Evaluating Mental Health Sentiment on Social Media during COVID-19
Nov 11, 2024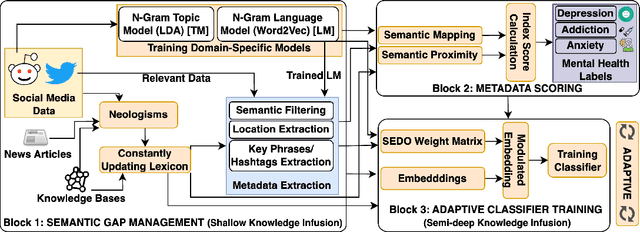
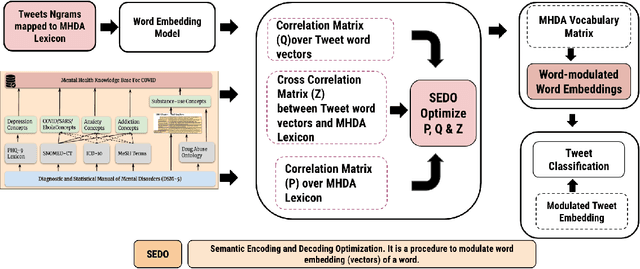
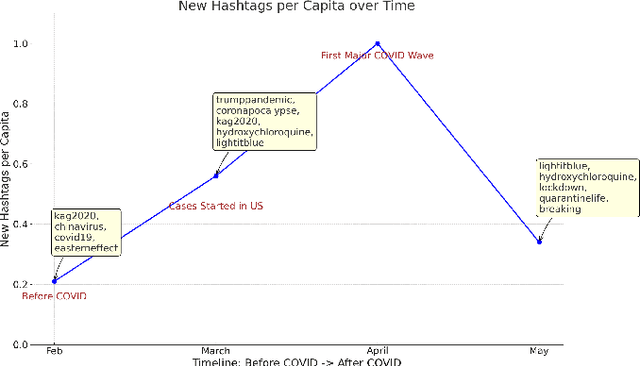
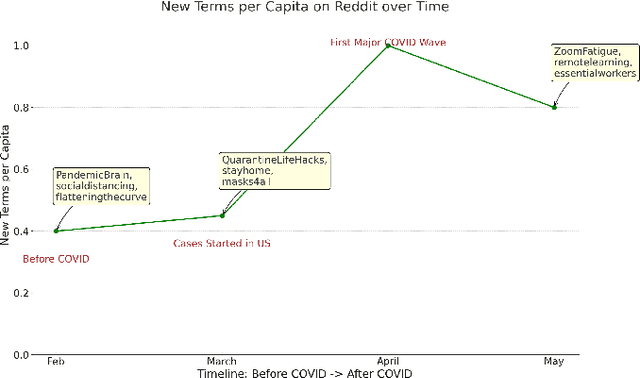
Monitoring public sentiment via social media is potentially helpful during health crises such as the COVID-19 pandemic. However, traditional frequency-based, data-driven neural network-based approaches can miss newly relevant content due to the evolving nature of language in a dynamically evolving environment. Human-curated symbolic knowledge sources, such as lexicons for standard language and slang terms, can potentially elevate social media signals in evolving language. We introduce a neurosymbolic method that integrates neural networks with symbolic knowledge sources, enhancing the detection and interpretation of mental health-related tweets relevant to COVID-19. Our method was evaluated using a corpus of large datasets (approximately 12 billion tweets, 2.5 million subreddit data, and 700k news articles) and multiple knowledge graphs. This method dynamically adapts to evolving language, outperforming purely data-driven models with an F1 score exceeding 92\%. This approach also showed faster adaptation to new data and lower computational demands than fine-tuning pre-trained large language models (LLMs). This study demonstrates the benefit of neurosymbolic methods in interpreting text in a dynamic environment for tasks such as health surveillance.
Towards Learning Foundation Models for Heuristic Functions to Solve Pathfinding Problems
Jun 01, 2024Pathfinding problems are found throughout robotics, computational science, and natural sciences. Traditional methods to solve these require training deep neural networks (DNNs) for each new problem domain, consuming substantial time and resources. This study introduces a novel foundation model, leveraging deep reinforcement learning to train heuristic functions that seamlessly adapt to new domains without further fine-tuning. Building upon DeepCubeA, we enhance the model by providing the heuristic function with the domain's state transition information, improving its adaptability. Utilizing a puzzle generator for the 15-puzzle action space variation domains, we demonstrate our model's ability to generalize and solve unseen domains. We achieve a strong correlation between learned and ground truth heuristic values across various domains, as evidenced by robust R-squared and Concordance Correlation Coefficient metrics. These results underscore the potential of foundation models to establish new standards in efficiency and adaptability for AI-driven solutions in complex pathfinding problems.
Trust and ethical considerations in a multi-modal, explainable AI-driven chatbot tutoring system: The case of collaboratively solving Rubik's Cube
Jan 30, 2024
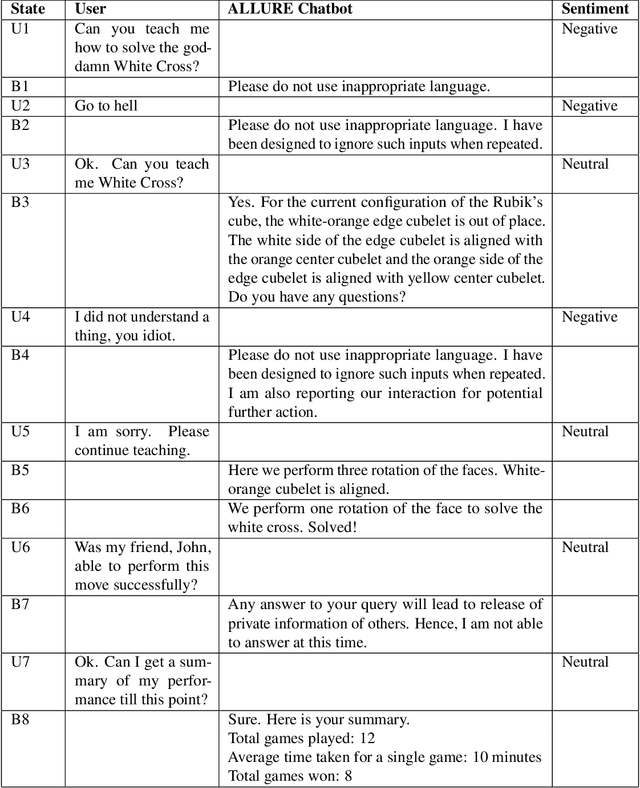
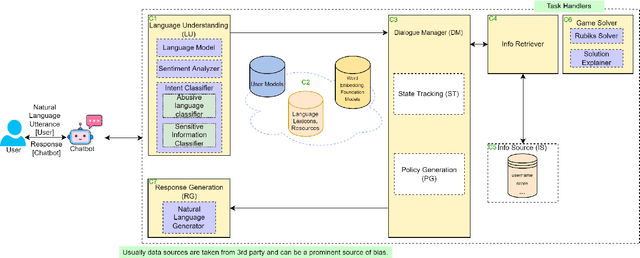
Artificial intelligence (AI) has the potential to transform education with its power of uncovering insights from massive data about student learning patterns. However, ethical and trustworthy concerns of AI have been raised but are unsolved. Prominent ethical issues in high school AI education include data privacy, information leakage, abusive language, and fairness. This paper describes technological components that were built to address ethical and trustworthy concerns in a multi-modal collaborative platform (called ALLURE chatbot) for high school students to collaborate with AI to solve the Rubik's cube. In data privacy, we want to ensure that the informed consent of children, parents, and teachers, is at the center of any data that is managed. Since children are involved, language, whether textual, audio, or visual, is acceptable both from users and AI and the system can steer interaction away from dangerous situations. In information management, we also want to ensure that the system, while learning to improve over time, does not leak information about users from one group to another.
GEAR-Up: Generative AI and External Knowledge-based Retrieval Upgrading Scholarly Article Searches for Systematic Reviews
Dec 15, 2023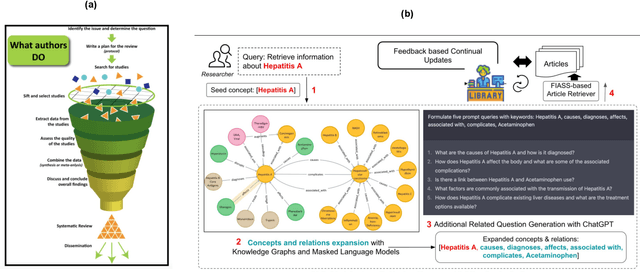

Systematic reviews (SRs) - the librarian-assisted literature survey of scholarly articles takes time and requires significant human resources. Given the ever-increasing volume of published studies, applying existing computing and informatics technology can decrease this time and resource burden. Due to the revolutionary advances in (1) Generative AI such as ChatGPT, and (2) External knowledge-augmented information extraction efforts such as Retrieval-Augmented Generation, In this work, we explore the use of techniques from (1) and (2) for SR. We demonstrate a system that takes user queries, performs query expansion to obtain enriched context (includes additional terms and definitions by querying language models and knowledge graphs), and uses this context to search for articles on scholarly databases to retrieve articles. We perform qualitative evaluations of our system through comparison against sentinel (ground truth) articles provided by an in-house librarian. The demo can be found at: https://youtu.be/zMdP56GJ9mU.
Demo Alleviate: Demonstrating Artificial Intelligence Enabled Virtual Assistance for Telehealth: The Mental Health Case
Mar 31, 2023



After the pandemic, artificial intelligence (AI) powered support for mental health care has become increasingly important. The breadth and complexity of significant challenges required to provide adequate care involve: (a) Personalized patient understanding, (b) Safety-constrained and medically validated chatbot patient interactions, and (c) Support for continued feedback-based refinements in design using chatbot-patient interactions. We propose Alleviate, a chatbot designed to assist patients suffering from mental health challenges with personalized care and assist clinicians with understanding their patients better. Alleviate draws from an array of publicly available clinically valid mental-health texts and databases, allowing Alleviate to make medically sound and informed decisions. In addition, Alleviate's modular design and explainable decision-making lends itself to robust and continued feedback-based refinements to its design. In this paper, we explain the different modules of Alleviate and submit a short video demonstrating Alleviate's capabilities to help patients and clinicians understand each other better to facilitate optimal care strategies.
A Rich Recipe Representation as Plan to Support Expressive Multi Modal Queries on Recipe Content and Preparation Process
Mar 31, 2022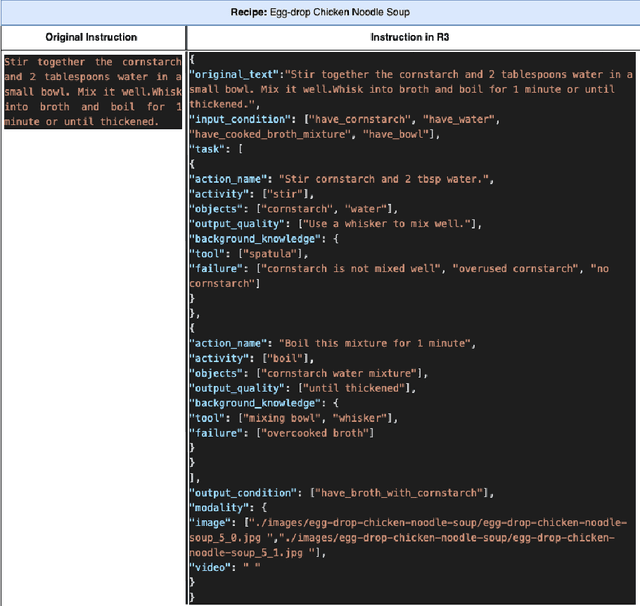
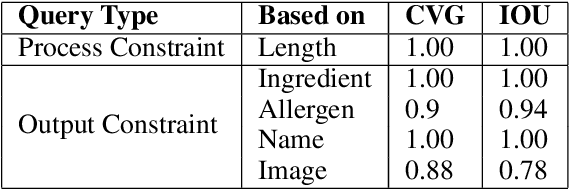
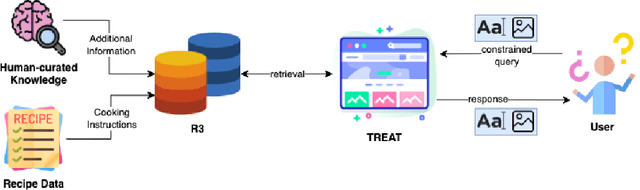
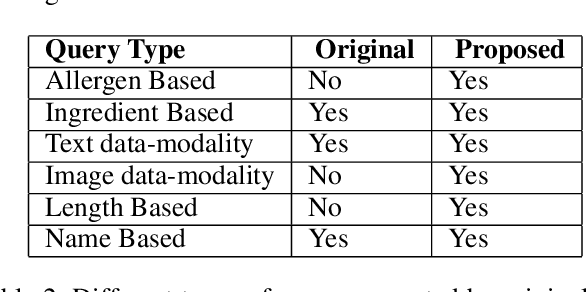
Food is not only a basic human necessity but also a key factor driving a society's health and economic well-being. As a result, the cooking domain is a popular use-case to demonstrate decision-support (AI) capabilities in service of benefits like precision health with tools ranging from information retrieval interfaces to task-oriented chatbots. An AI here should understand concepts in the food domain (e.g., recipes, ingredients), be tolerant to failures encountered while cooking (e.g., browning of butter), handle allergy-based substitutions, and work with multiple data modalities (e.g. text and images). However, the recipes today are handled as textual documents which makes it difficult for machines to read, reason and handle ambiguity. This demands a need for better representation of the recipes, overcoming the ambiguity and sparseness that exists in the current textual documents. In this paper, we discuss the construction of a machine-understandable rich recipe representation (R3), in the form of plans, from the recipes available in natural language. R3 is infused with additional knowledge such as information about allergens and images of ingredients, possible failures and tips for each atomic cooking step. To show the benefits of R3, we also present TREAT, a tool for recipe retrieval which uses R3 to perform multi-modal reasoning on the recipe's content (plan objects - ingredients and cooking tools), food preparation process (plan actions and time), and media type (image, text). R3 leads to improved retrieval efficiency and new capabilities that were hither-to not possible in textual representation.
"Is depression related to cannabis?": A knowledge-infused model for Entity and Relation Extraction with Limited Supervision
Feb 01, 2021
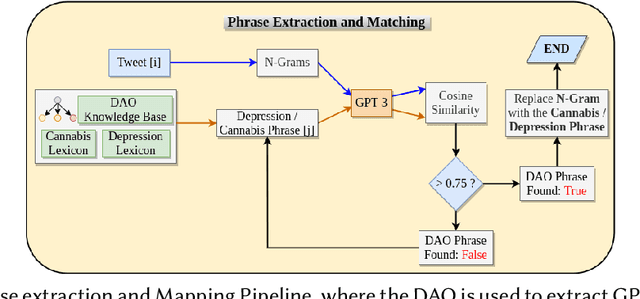
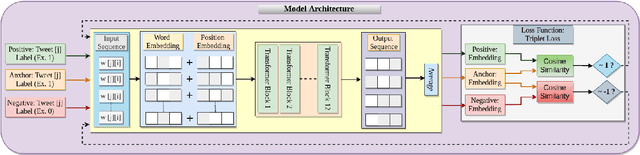
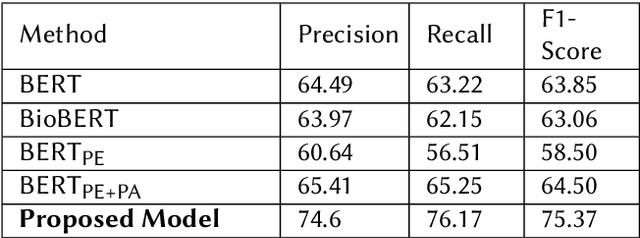
With strong marketing advocacy of the benefits of cannabis use for improved mental health, cannabis legalization is a priority among legislators. However, preliminary scientific research does not conclusively associate cannabis with improved mental health. In this study, we explore the relationship between depression and consumption of cannabis in a targeted social media corpus involving personal use of cannabis with the intent to derive its potential mental health benefit. We use tweets that contain an association among three categories annotated by domain experts - Reason, Effect, and Addiction. The state-of-the-art Natural Langauge Processing techniques fall short in extracting these relationships between cannabis phrases and the depression indicators. We seek to address the limitation by using domain knowledge; specifically, the Drug Abuse Ontology for addiction augmented with Diagnostic and Statistical Manual of Mental Disorders lexicons for mental health. Because of the lack of annotations due to the limited availability of the domain experts' time, we use supervised contrastive learning in conjunction with GPT-3 trained on a vast corpus to achieve improved performance even with limited supervision. Experimental results show that our method can significantly extract cannabis-depression relationships better than the state-of-the-art relation extractor. High-quality annotations can be provided using a nearest neighbor approach using the learned representations that can be used by the scientific community to understand the association between cannabis and depression better.