 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoes of Human Malice in Agents: Benchmarking LLMs for Multi-Turn Online Harassment Attacks
Oct 16, 2025Large Language Model (LLM) agents are powering a growing share of interactive web applications, yet remain vulnerable to misuse and harm. Prior jailbreak research has largely focused on single-turn prompts, whereas real harassment often unfolds over multi-turn interactions. In this work, we present the Online Harassment Agentic Benchmark consisting of: (i) a synthetic multi-turn harassment conversation dataset, (ii) a multi-agent (e.g., harasser, victim) simulation informed by repeated game theory, (iii) three jailbreak methods attacking agents across memory, planning, and fine-tuning, and (iv) a mixed-methods evaluation framework. We utilize two prominent LLMs, LLaMA-3.1-8B-Instruct (open-source) and Gemini-2.0-flash (closed-source). Our results show that jailbreak tuning makes harassment nearly guaranteed with an attack success rate of 95.78--96.89% vs. 57.25--64.19% without tuning in Llama, and 99.33% vs. 98.46% without tuning in Gemini, while sharply reducing refusal rate to 1-2% in both models. The most prevalent toxic behaviors are Insult with 84.9--87.8% vs. 44.2--50.8% without tuning, and Flaming with 81.2--85.1% vs. 31.5--38.8% without tuning, indicating weaker guardrails compared to sensitive categories such as sexual or racial harassment. Qualitative evaluation further reveals that attacked agents reproduce human-like aggression profiles, such as Machiavellian/psychopathic patterns under planning, and narcissistic tendencies with memory. Counterintuitively, closed-source and open-source models exhibit distinct escalation trajectories across turns, with closed-source models showing significant vulnerability. Overall, our findings show that multi-turn and theory-grounded attacks not only succeed at high rates but also mimic human-like harassment dynamics, motivating the development of robust safety guardrails to ultimately keep online platforms safe and responsible.
From Reddit to Generative AI: Evaluating Large Language Models for Anxiety Support Fine-tuned on Social Media Data
May 24, 2025The growing demand for accessible mental health support, compounded by workforce shortages and logistical barriers, has led to increased interest in utilizing Large Language Models (LLMs) for scalable and real-time assistance. However, their use in sensitive domains such as anxiety support remains underexamined. This study presents a systematic evaluation of LLMs (GPT and Llama) for their potential utility in anxiety support by using real user-generated posts from the r/Anxiety subreddit for both prompting and fine-tuning. Our approach utilizes a mixed-method evaluation framework incorporating three main categories of criteria: (i) linguistic quality, (ii) safety and trustworthiness, and (iii) supportiveness. Results show that fine-tuning LLMs with naturalistic anxiety-related data enhanced linguistic quality but increased toxicity and bias, and diminished emotional responsiveness. While LLMs exhibited limited empathy, GPT was evaluated as more supportive overall. Our findings highlight the risks of fine-tuning LLMs on unprocessed social media content without mitigation strategies.
Large Language Models for Cancer Communication: Evaluating Linguistic Quality, Safety, and Accessibility in Generative AI
May 15, 2025Effective communication about breast and cervical cancers remains a persistent health challenge, with significant gaps in public understanding of cancer prevention, screening, and treatment, potentially leading to delayed diagnoses and inadequate treatments. This study evaluates the capabilities and limitations of Large Language Models (LLMs) in generating accurate, safe, and accessible cancer-related information to support patient understanding. We evaluated five general-purpose and three medical LLMs using a mixed-methods evaluation framework across linguistic quality, safety and trustworthiness, and communication accessibility and affectiveness. Our approach utilized quantitative metrics, qualitative expert ratings, and statistical analysis using Welch's ANOVA, Games-Howell, and Hedges' g. Our results show that general-purpose LLMs produced outputs of higher linguistic quality and affectiveness, while medical LLMs demonstrate greater communication accessibility. However, medical LLMs tend to exhibit higher levels of potential harm, toxicity, and bias, reducing their performance in safety and trustworthiness. Our findings indicate a duality between domain-specific knowledge and safety in health communications. The results highlight the need for intentional model design with targeted improvements, particularly in mitigating harm and bias, and improving safety and affectiveness. This study provides a comprehensive evaluation of LLMs for cancer communication, offering critical insights for improving AI-generated health content and informing future development of accurate, safe, and accessible digital health tools.
Playing Devil's Advocate: Unmasking Toxicity and Vulnerabilities in Large Vision-Language Models
Jan 14, 2025



The rapid advancement of Large Vision-Language Models (LVLMs) has enhanced capabilities offering potential applications from content creation to productivity enhancement. Despite their innovative potential, LVLMs exhibit vulnerabilities, especially in generating potentially toxic or unsafe responses. Malicious actors can exploit these vulnerabilities to propagate toxic content in an automated (or semi-) manner, leveraging the susceptibility of LVLMs to deception via strategically crafted prompts without fine-tuning or compute-intensive procedures. Despite the red-teaming efforts and inherent potential risks associated with the LVLMs, exploring vulnerabilities of LVLMs remains nascent and yet to be fully addressed in a systematic manner. This study systematically examines the vulnerabilities of open-source LVLMs, including LLaVA, InstructBLIP, Fuyu, and Qwen, using adversarial prompt strategies that simulate real-world social manipulation tactics informed by social theories. Our findings show that (i) toxicity and insulting are the most prevalent behaviors, with the mean rates of 16.13% and 9.75%, respectively; (ii) Qwen-VL-Chat, LLaVA-v1.6-Vicuna-7b, and InstructBLIP-Vicuna-7b are the most vulnerable models, exhibiting toxic response rates of 21.50%, 18.30% and 17.90%, and insulting responses of 13.40%, 11.70% and 10.10%, respectively; (iii) prompting strategies incorporating dark humor and multimodal toxic prompt completion significantly elevated these vulnerabilities. Despite being fine-tuned for safety, these models still generate content with varying degrees of toxicity when prompted with adversarial inputs, highlighting the urgent need for enhanced safety mechanisms and robust guardrails in LVLM development.
Just KIDDIN: Knowledge Infusion and Distillation for Detection of INdecent Memes
Nov 19, 2024Toxicity identification in online multimodal environments remains a challenging task due to the complexity of contextual connections across modalities (e.g., textual and visual). In this paper, we propose a novel framework that integrates Knowledge Distillation (KD) from Large Visual Language Models (LVLMs) and knowledge infusion to enhance the performance of toxicity detection in hateful memes. Our approach extracts sub-knowledge graphs from ConceptNet, a large-scale commonsense Knowledge Graph (KG) to be infused within a compact VLM framework. The relational context between toxic phrases in captions and memes, as well as visual concepts in memes enhance the model's reasoning capabilities. Experimental results from our study on two hate speech benchmark datasets demonstrate superior performance over the state-of-the-art baselines across AU-ROC, F1, and Recall with improvements of 1.1%, 7%, and 35%, respectively. Given the contextual complexity of the toxicity detection task, our approach showcases the significance of learning from both explicit (i.e. KG) as well as implicit (i.e. LVLMs) contextual cues incorporated through a hybrid neurosymbolic approach. This is crucial for real-world applications where accurate and scalable recognition of toxic content is critical for creating safer online environments.
A Domain-Agnostic Neurosymbolic Approach for Big Social Data Analysis: Evaluating Mental Health Sentiment on Social Media during COVID-19
Nov 11, 2024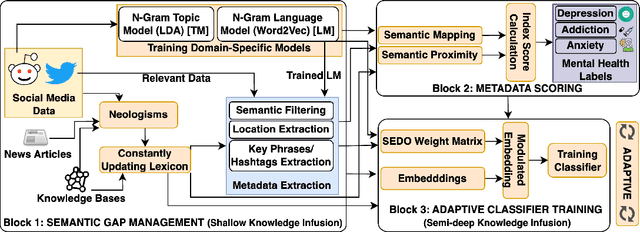
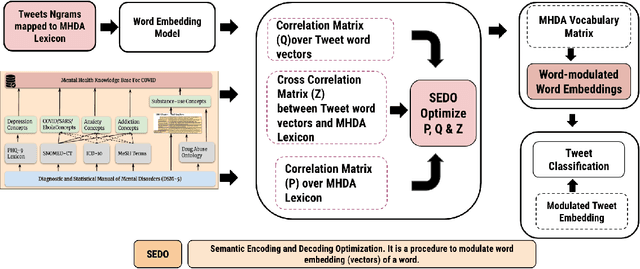
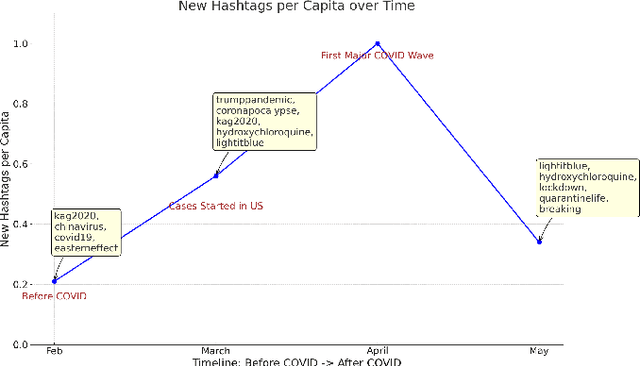
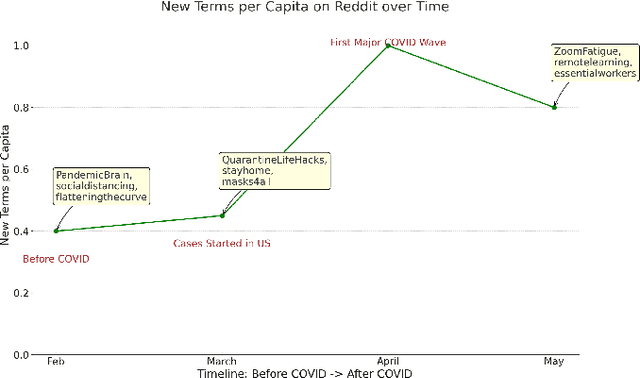
Monitoring public sentiment via social media is potentially helpful during health crises such as the COVID-19 pandemic. However, traditional frequency-based, data-driven neural network-based approaches can miss newly relevant content due to the evolving nature of language in a dynamically evolving environment. Human-curated symbolic knowledge sources, such as lexicons for standard language and slang terms, can potentially elevate social media signals in evolving language. We introduce a neurosymbolic method that integrates neural networks with symbolic knowledge sources, enhancing the detection and interpretation of mental health-related tweets relevant to COVID-19. Our method was evaluated using a corpus of large datasets (approximately 12 billion tweets, 2.5 million subreddit data, and 700k news articles) and multiple knowledge graphs. This method dynamically adapts to evolving language, outperforming purely data-driven models with an F1 score exceeding 92\%. This approach also showed faster adaptation to new data and lower computational demands than fine-tuning pre-trained large language models (LLMs). This study demonstrates the benefit of neurosymbolic methods in interpreting text in a dynamic environment for tasks such as health surveillance.
Improving Contextual Congruence Across Modalities for Effective Multimodal Marketing using Knowledge-infused Learning
Feb 06, 2024The prevalence of smart devices with the ability to capture moments in multiple modalities has enabled users to experience multimodal information online. However, large Language (LLMs) and Vision models (LVMs) are still limited in capturing holistic meaning with cross-modal semantic relationships. Without explicit, common sense knowledge (e.g., as a knowledge graph), Visual Language Models (VLMs) only learn implicit representations by capturing high-level patterns in vast corpora, missing essential contextual cross-modal cues. In this work, we design a framework to couple explicit commonsense knowledge in the form of knowledge graphs with large VLMs to improve the performance of a downstream task, predicting the effectiveness of multi-modal marketing campaigns. While the marketing application provides a compelling metric for assessing our methods, our approach enables the early detection of likely persuasive multi-modal campaigns and the assessment and augmentation of marketing theory.
Characterization of Time-variant and Time-invariant Assessment of Suicidality on Reddit using C-SSRS
Apr 09, 2021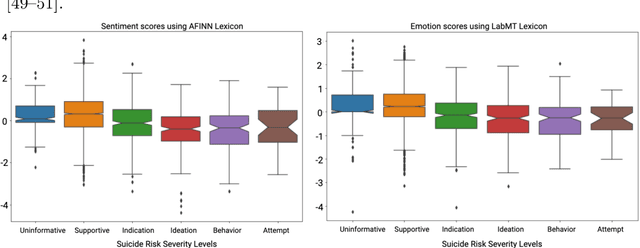
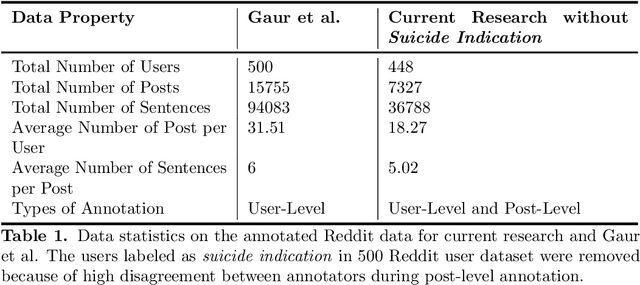
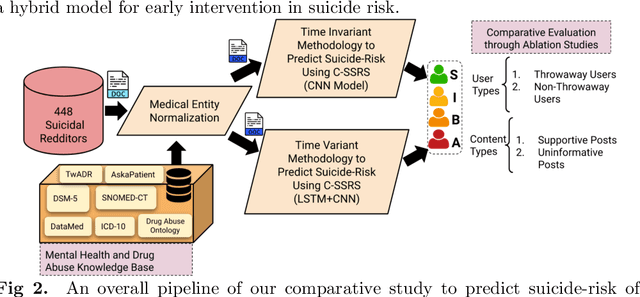

Suicide is the 10th leading cause of death in the U.S (1999-2019). However, predicting when someone will attempt suicide has been nearly impossible. In the modern world, many individuals suffering from mental illness seek emotional support and advice on well-known and easily-accessible social media platforms such as Reddit. While prior artificial intelligence research has demonstrated the ability to extract valuable information from social media on suicidal thoughts and behaviors, these efforts have not considered both severity and temporality of risk. The insights made possible by access to such data have enormous clinical potential - most dramatically envisioned as a trigger to employ timely and targeted interventions (i.e., voluntary and involuntary psychiatric hospitalization) to save lives. In this work, we address this knowledge gap by developing deep learning algorithms to assess suicide risk in terms of severity and temporality from Reddit data based on the Columbia Suicide Severity Rating Scale (C-SSRS). In particular, we employ two deep learning approaches: time-variant and time-invariant modeling, for user-level suicide risk assessment, and evaluate their performance against a clinician-adjudicated gold standard Reddit corpus annotated based on the C-SSRS. Our results suggest that the time-variant approach outperforms the time-invariant method in the assessment of suicide-related ideations and supportive behaviors (AUC:0.78), while the time-invariant model performed better in predicting suicide-related behaviors and suicide attempt (AUC:0.64). The proposed approach can be integrated with clinical diagnostic interviews for improving suicide risk assessments.
Knowledge Infused Learning (K-IL): Towards Deep Incorporation of Knowledge in Deep Learning
Dec 01, 2019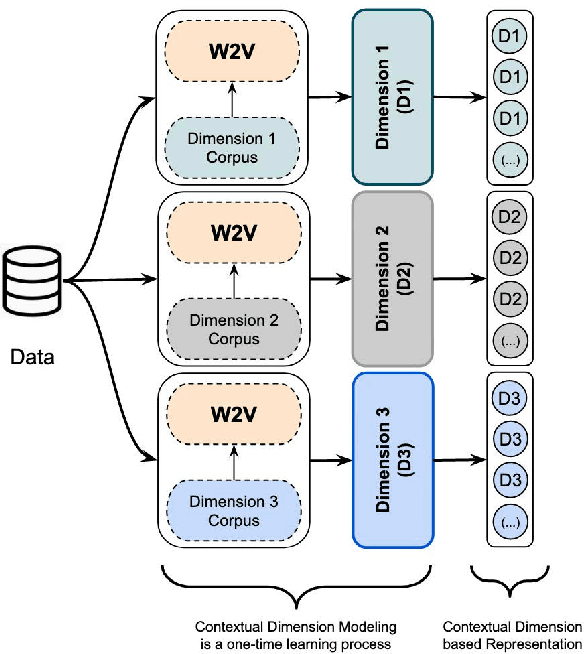
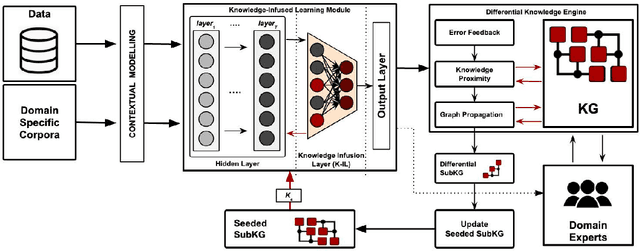
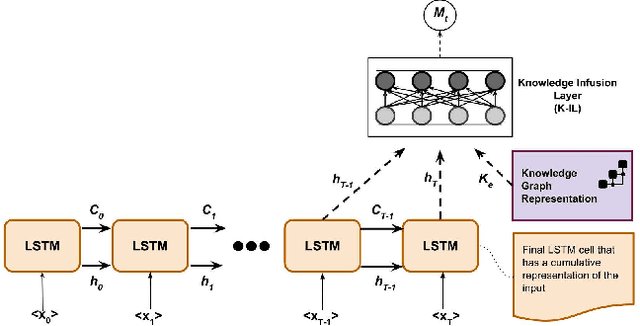
Learning the underlying patterns in the data goes beyond instance-based generalization to some external knowledge represented in structured graphs or networks. Deep Learning (DL) has shown significant advances in probabilistically learning latent patterns in the data using a multi-layered network of computational nodes (i.e. neurons/hidden units). However, with the tremendous amount of training data, uncertainty in generalization on domain-specific tasks, and delta improvement with an increase in complexity of models seem to raise a concern on the features learned by the model. As incorporation of domain specific knowledge will aid in supervising the learning of features for the model, infusion of knowledge from knowledge graphs within hidden layers will further enhance the learning process. Although much work remains, we believe that KGs will play an increasing role in developing hybrid neuro-symbolic intelligent systems (that is bottom up deep learning with top down symbolic computing) as well as in building explainable AI systems for which KGs will provide a scaffolding for punctuating neural computing. In this position paper, we describe our motivation for such hybrid approach and a framework that combines knowledge graph and neural networks.
Modeling Islamist Extremist Communications on Social Media using Contextual Dimensions: Religion, Ideology, and Hate
Aug 20, 2019
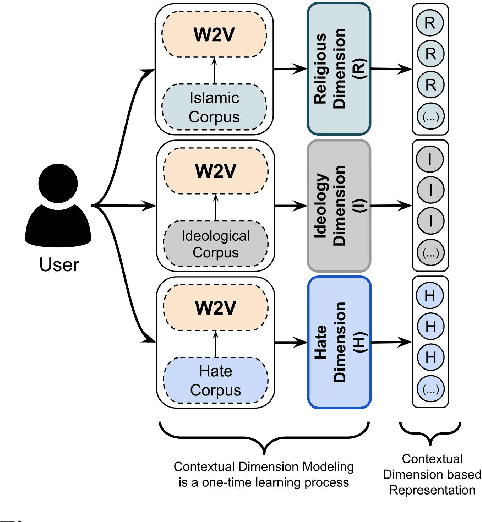
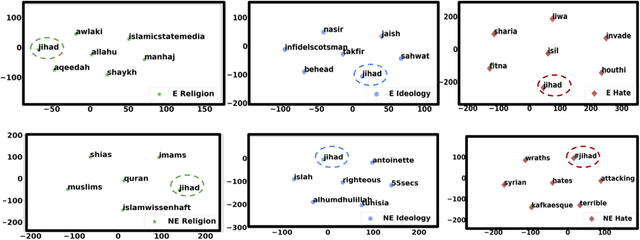
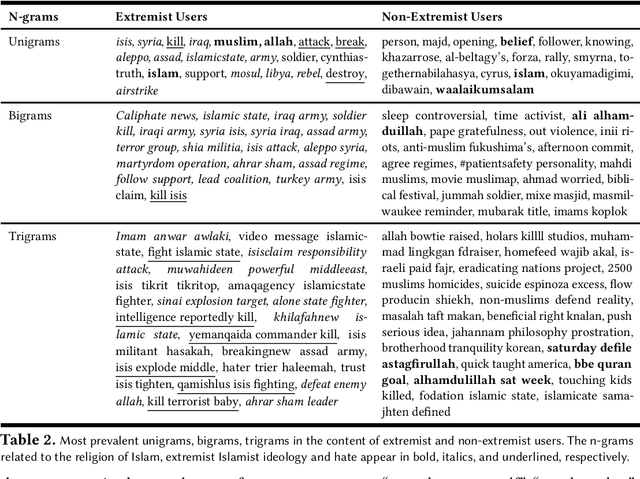
Terror attacks have been linked in part to online extremist content. Although tens of thousands of Islamist extremism supporters consume such content, they are a small fraction relative to peaceful Muslims. The efforts to contain the ever-evolving extremism on social media platforms have remained inadequate and mostly ineffective. Divergent extremist and mainstream contexts challenge machine interpretation, with a particular threat to the precision of classification algorithms. Our context-aware computational approach to the analysis of extremist content on Twitter breaks down this persuasion process into building blocks that acknowledge inherent ambiguity and sparsity that likely challenge both manual and automated classification. We model this process using a combination of three contextual dimensions -- religion, ideology, and hate -- each elucidating a degree of radicalization and highlighting independent features to render them computationally accessible. We utilize domain-specific knowledge resources for each of these contextual dimensions such as Qur'an for religion, the books of extremist ideologues and preachers for political ideology and a social media hate speech corpus for hate. Our study makes three contributions to reliable analysis: (i) Development of a computational approach rooted in the contextual dimensions of religion, ideology, and hate that reflects strategies employed by online Islamist extremist groups, (ii) An in-depth analysis of relevant tweet datasets with respect to these dimensions to exclude likely mislabeled users, and (iii) A framework for understanding online radicalization as a process to assist counter-programming. Given the potentially significant social impact, we evaluate the performance of our algorithms to minimize mislabeling, where our approach outperforms a competitive baseline by 10.2% in precision.