 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding from an AI and Cognitive Science Lens
Feb 19, 2024Grounding is a challenging problem, requiring a formal definition and different levels of abstraction. This article explores grounding from both cognitive science and machine learning perspectives. It identifies the subtleties of grounding, its significance for collaborative agents, and similarities and differences in grounding approaches in both communities. The article examines the potential of neuro-symbolic approaches tailored for grounding tasks, showcasing how they can more comprehensively address grounding. Finally, we discuss areas for further exploration and development in grounding.
Improving Contextual Congruence Across Modalities for Effective Multimodal Marketing using Knowledge-infused Learning
Feb 06, 2024The prevalence of smart devices with the ability to capture moments in multiple modalities has enabled users to experience multimodal information online. However, large Language (LLMs) and Vision models (LVMs) are still limited in capturing holistic meaning with cross-modal semantic relationships. Without explicit, common sense knowledge (e.g., as a knowledge graph), Visual Language Models (VLMs) only learn implicit representations by capturing high-level patterns in vast corpora, missing essential contextual cross-modal cues. In this work, we design a framework to couple explicit commonsense knowledge in the form of knowledge graphs with large VLMs to improve the performance of a downstream task, predicting the effectiveness of multi-modal marketing campaigns. While the marketing application provides a compelling metric for assessing our methods, our approach enables the early detection of likely persuasive multi-modal campaigns and the assessment and augmentation of marketing theory.
Expanding the Set of Pragmatic Considerations in Conversational AI
Oct 27, 2023Despite considerable performance improvements, current conversational AI systems often fail to meet user expectations. We discuss several pragmatic limitations of current conversational AI systems. We illustrate pragmatic limitations with examples that are syntactically appropriate, but have clear pragmatic deficiencies. We label our complaints as "Turing Test Triggers" (TTTs) as they indicate where current conversational AI systems fall short compared to human behavior. We develop a taxonomy of pragmatic considerations intended to identify what pragmatic competencies a conversational AI system requires and discuss implications for the design and evaluation of conversational AI systems.
Evaluating the Deductive Competence of Large Language Models
Sep 11, 2023
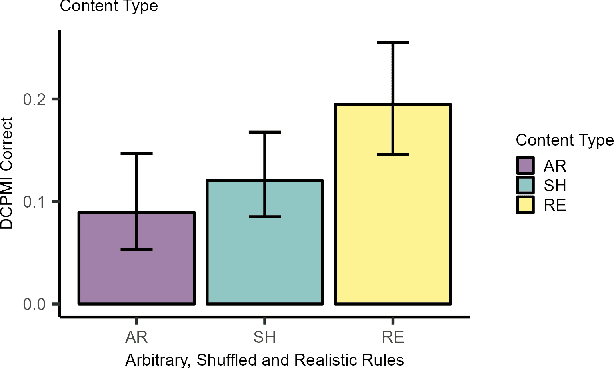
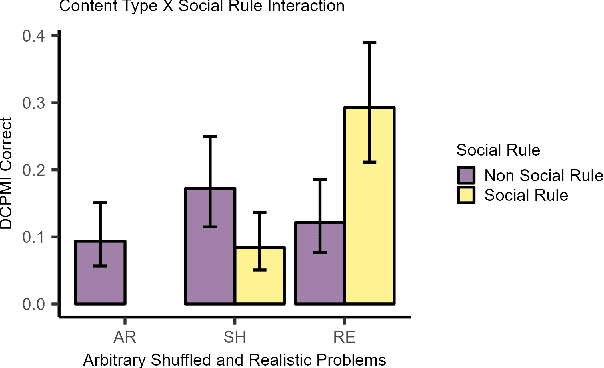
The development of highly fluent large language models (LLMs) has prompted increased interest in assessing their reasoning and problem-solving capabilities. We investigate whether several LLMs can solve a classic type of deductive reasoning problem from the cognitive science literature. The tested LLMs have limited abilities to solve these problems in their conventional form. We performed follow up experiments to investigate if changes to the presentation format and content improve model performance. We do find performance differences between conditions; however, they do not improve overall performance. Moreover, we find that performance interacts with presentation format and content in unexpected ways that differ from human performance. Overall, our results suggest that LLMs have unique reasoning biases that are only partially predicted from human reasoning performance.
Why Do We Need Neuro-symbolic AI to Model Pragmatic Analogies?
Aug 02, 2023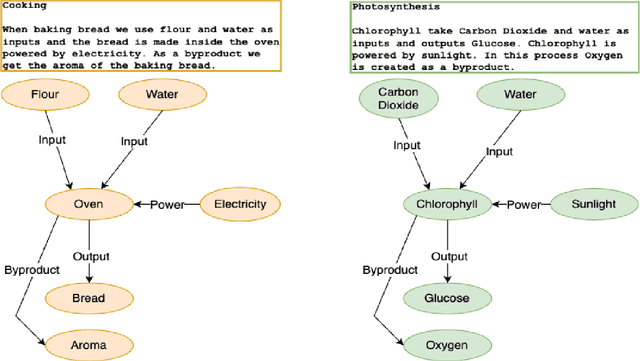
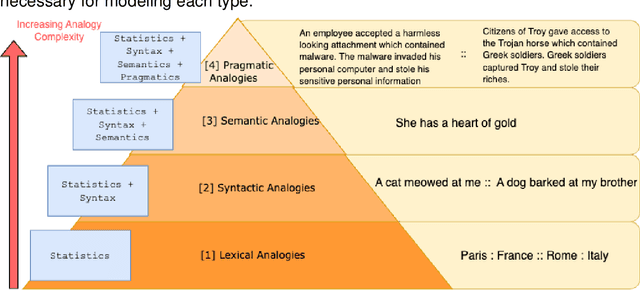
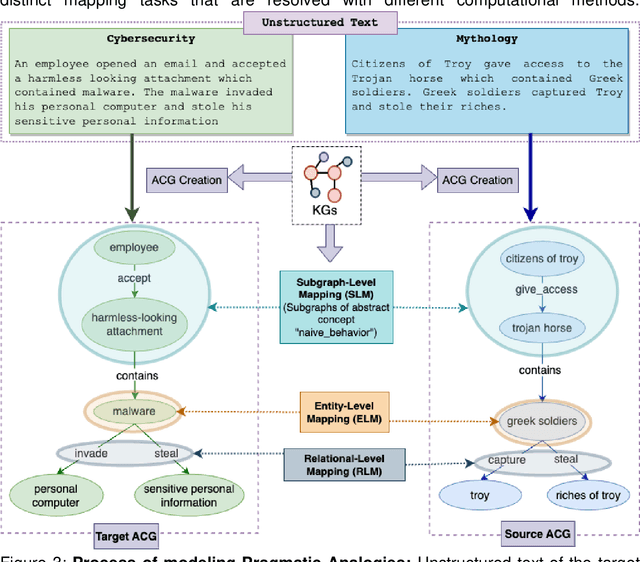
A hallmark of intelligence is the ability to use a familiar domain to make inferences about a less familiar domain, known as analogical reasoning. In this article, we delve into the performance of Large Language Models (LLMs) in dealing with progressively complex analogies expressed in unstructured text. We discuss analogies at four distinct levels of complexity: lexical analogies, syntactic analogies, semantic analogies, and pragmatic analogies. As the analogies become more complex, they require increasingly extensive, diverse knowledge beyond the textual content, unlikely to be found in the lexical co-occurrence statistics that power LLMs. To address this, we discuss the necessity of employing Neuro-symbolic AI techniques that combine statistical and symbolic AI, informing the representation of unstructured text to highlight and augment relevant content, provide abstraction and guide the mapping process. Our knowledge-informed approach maintains the efficiency of LLMs while preserving the ability to explain analogies for pedagogical applications.
Long-form analogies generated by chatGPT lack human-like psycholinguistic properties
Jun 07, 2023Psycholinguistic analyses provide a means of evaluating large language model (LLM) output and making systematic comparisons to human-generated text. These methods can be used to characterize the psycholinguistic properties of LLM output and illustrate areas where LLMs fall short in comparison to human-generated text. In this work, we apply psycholinguistic methods to evaluate individual sentences from long-form analogies about biochemical concepts. We compare analogies generated by human subjects enrolled in introductory biochemistry courses to analogies generated by chatGPT. We perform a supervised classification analysis using 78 features extracted from Coh-metrix that analyze text cohesion, language, and readability (Graesser et. al., 2004). Results illustrate high performance for classifying student-generated and chatGPT-generated analogies. To evaluate which features contribute most to model performance, we use a hierarchical clustering approach. Results from this analysis illustrate several linguistic differences between the two sources.
Discourse over Discourse: The Need for an Expanded Pragmatic Focus in Conversational AI
Apr 27, 2023The summarization of conversation, that is, discourse over discourse, elevates pragmatic considerations as a pervasive limitation of both summarization and other applications of contemporary conversational AI. Building on impressive progress in both semantics and syntax, pragmatics concerns meaning in the practical sense. In this paper, we discuss several challenges in both summarization of conversations and other conversational AI applications, drawing on relevant theoretical work. We illustrate the importance of pragmatics with so-called star sentences, syntactically acceptable propositions that are pragmatically inappropriate in conversation or its summary. Because the baseline for quality of AI is indistinguishability from human behavior, we draw heavily on the psycho-linguistics literature, and label our complaints as "Turing Test Triggers" (TTTs). We discuss implications for the design and evaluation of conversation summarization methods and conversational AI applications like voice assistants and chatbots
Predicting Early Indicators of Cognitive Decline from Verbal Utterances
Nov 19, 2020



Dementia is a group of irreversible, chronic, and progressive neurodegenerative disorders resulting in impaired memory, communication, and thought processes. In recent years, clinical research advances in brain aging have focused on the earliest clinically detectable stage of incipient dementia, commonly known as mild cognitive impairment (MCI). Currently, these disorders are diagnosed using a manual analysis of neuropsychological examinations. We measure the feasibility of using the linguistic characteristics of verbal utterances elicited during neuropsychological exams of elderly subjects to distinguish between elderly control groups, people with MCI, people diagnosed with possible Alzheimer's disease (AD), and probable AD. We investigated the performance of both theory-driven psycholinguistic features and data-driven contextual language embeddings in identifying different clinically diagnosed groups. Our experiments show that a combination of contextual and psycholinguistic features extracted by a Support Vector Machine improved distinguishing the verbal utterances of elderly controls, people with MCI, possible AD, and probable AD. This is the first work to identify four clinical diagnosis groups of dementia in a highly imbalanced dataset. Our work shows that machine learning algorithms built on contextual and psycholinguistic features can learn the linguistic biomarkers from verbal utterances and assist clinical diagnosis of different stages and types of dementia, even with limited data.
Towards Geocoding Spatial Expressions
Jun 12, 2019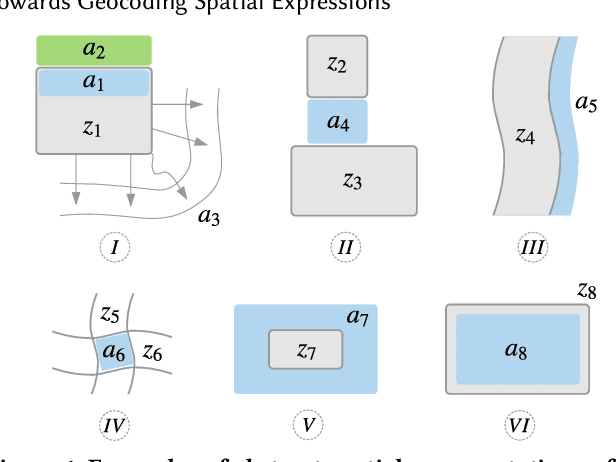
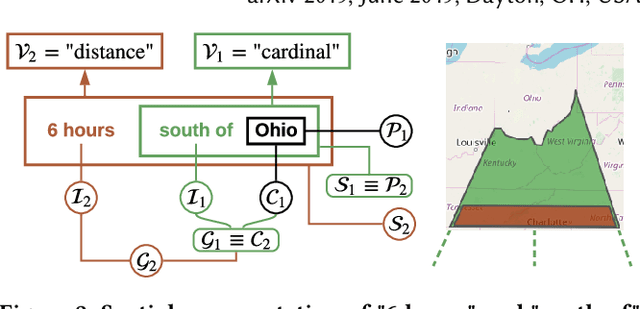
Imprecise composite location references formed using ad hoc spatial expressions in English text makes the geocoding task challenging for both inference and evaluation. Typically such spatial expressions fill in unestablished areas with new toponyms for finer spatial referents. For example, the spatial extent of the ad hoc spatial expression "north of" or "50 minutes away from" in relation to the toponym "Dayton, OH" refers to an ambiguous, imprecise area, requiring translation from this qualitative representation to a quantitative one with precise semantics using systems such as WGS84. Here we highlight the challenges of geocoding such referents and propose a formal representation that employs background knowledge, semantic approximations and rules, and fuzzy linguistic variables. We also discuss an appropriate evaluation technique for the task that is based on human contextualized and subjective judgment.
Analyzing and learning the language for different types of harassment
Nov 01, 2018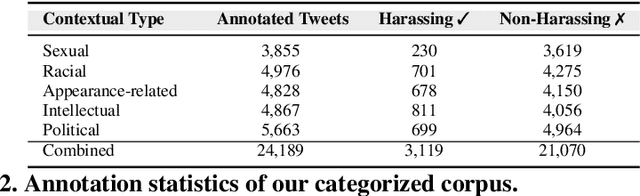
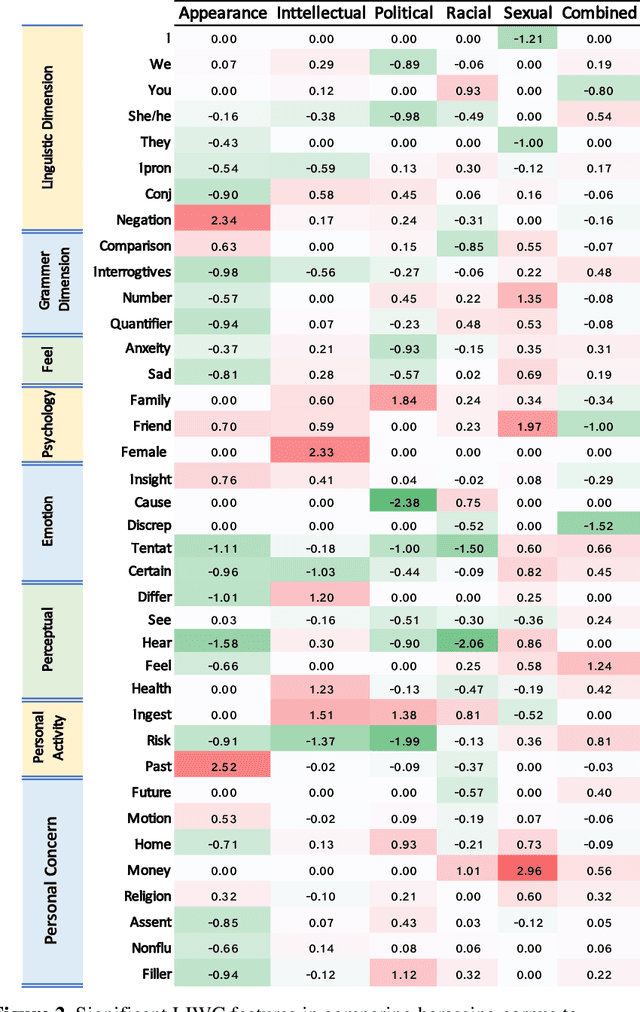
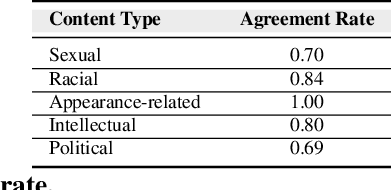
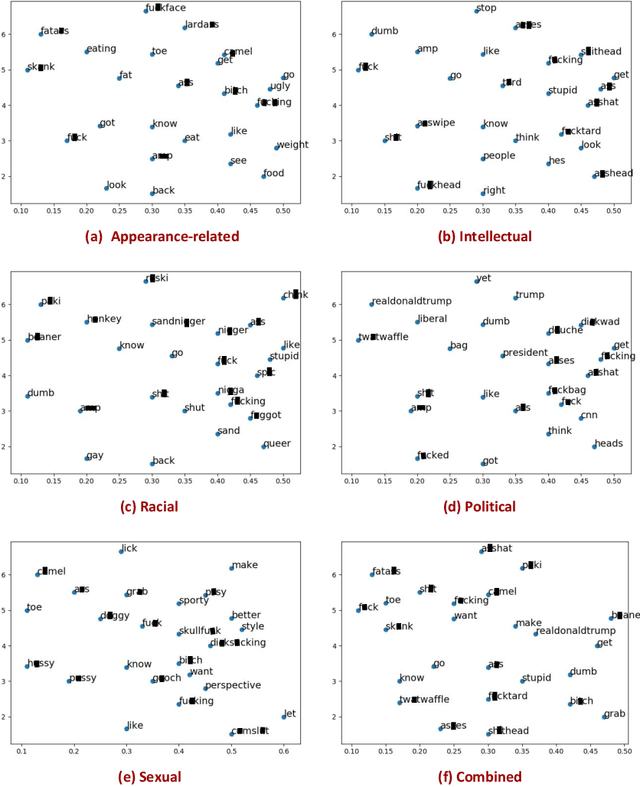
The presence of a significant amount of harassment in user-generated content and its negative impact calls for robust automatic detection approaches. This requires that we can identify different forms or types of harassment. Earlier work has classified harassing language in terms of hurtfulness, abusiveness, sentiment, and profanity. However, to identify and understand harassment more accurately, it is essential to determine the context that represents the interrelated conditions in which they occur. In this paper, we introduce the notion of contextual type to harassment involving five categories: (i) sexual, (ii) racial, (iii) appearance-related, (iv) intellectual and (v) political. We utilize an annotated corpus from Twitter distinguishing these types of harassment. To study the context for each type that sheds light on the linguistic meaning, interpretation, and distribution, we conduct two lines of investigation: an extensive linguistic analysis, and a statistical distribution of unigrams. We then build type-ware classifiers to automate the identification of type-specific harassment. Our experiments demonstrate that these classifiers provide competitive accuracy for identifying and analyzing harassment on social media. We present extensive discussion and major observations about the effectiveness of type-aware classifiers using a detailed comparison setup providing insight into the role of type-dependent features.