 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Early Indicators of Cognitive Decline from Verbal Utterances
Nov 19, 2020



Dementia is a group of irreversible, chronic, and progressive neurodegenerative disorders resulting in impaired memory, communication, and thought processes. In recent years, clinical research advances in brain aging have focused on the earliest clinically detectable stage of incipient dementia, commonly known as mild cognitive impairment (MCI). Currently, these disorders are diagnosed using a manual analysis of neuropsychological examinations. We measure the feasibility of using the linguistic characteristics of verbal utterances elicited during neuropsychological exams of elderly subjects to distinguish between elderly control groups, people with MCI, people diagnosed with possible Alzheimer's disease (AD), and probable AD. We investigated the performance of both theory-driven psycholinguistic features and data-driven contextual language embeddings in identifying different clinically diagnosed groups. Our experiments show that a combination of contextual and psycholinguistic features extracted by a Support Vector Machine improved distinguishing the verbal utterances of elderly controls, people with MCI, possible AD, and probable AD. This is the first work to identify four clinical diagnosis groups of dementia in a highly imbalanced dataset. Our work shows that machine learning algorithms built on contextual and psycholinguistic features can learn the linguistic biomarkers from verbal utterances and assist clinical diagnosis of different stages and types of dementia, even with limited data.
Multimodal Emotion Classification
Mar 13, 2019
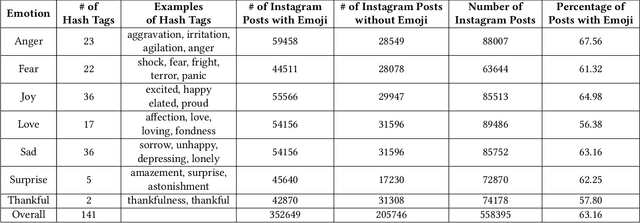


Most NLP and Computer Vision tasks are limited to scarcity of labelled data. In social media emotion classification and other related tasks, hashtags have been used as indicators to label data. With the rapid increase in emoji usage of social media, emojis are used as an additional feature for major social NLP tasks. However, this is less explored in case of multimedia posts on social media where posts are composed of both image and text. At the same time, w.e have seen a surge in the interest to incorporate domain knowledge to improve machine understanding of text. In this paper, we investigate whether domain knowledge for emoji can improve the accuracy of emotion classification task. We exploit the importance of different modalities from social media post for emotion classification task using state-of-the-art deep learning architectures. Our experiments demonstrate that the three modalities (text, emoji and images) encode different information to express emotion and therefore can complement each other. Our results also demonstrate that emoji sense depends on the textual context, and emoji combined with text encodes better information than considered separately. The highest accuracy of 71.98\% is achieved with a training data of 550k posts.
* Accepted at the 2nd Emoji Workshop co-located with The Web Conference 2019
Which Emoji Talks Best for My Picture?
Aug 27, 2018


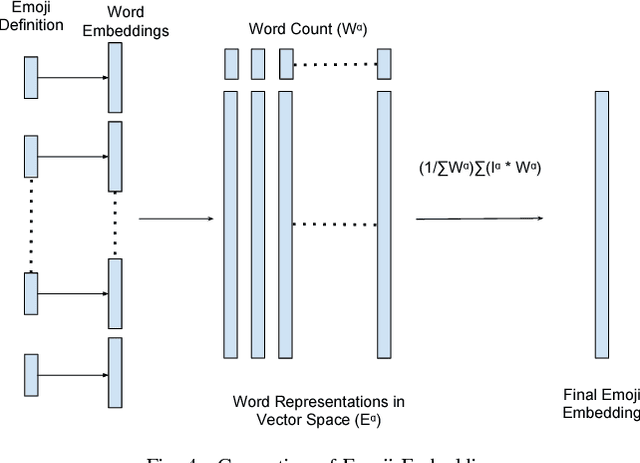
Emojis have evolved as complementary sources for expressing emotion in social-media platforms where posts are mostly composed of texts and images. In order to increase the expressiveness of the social media posts, users associate relevant emojis with their posts. Incorporating domain knowledge has improved machine understanding of text. In this paper, we investigate whether domain knowledge for emoji can improve the accuracy of emoji recommendation task in case of multimedia posts composed of image and text. Our emoji recommendation can suggest accurate emojis by exploiting both visual and textual content from social media posts as well as domain knowledge from Emojinet. Experimental results using pre-trained image classifiers and pre-trained word embedding models on Twitter dataset show that our results outperform the current state-of-the-art by 9.6\%. We also present a user study evaluation of our recommendation system on a set of images chosen from MSCOCO dataset.