 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Themes in Clinical Notes to Identify Phenotypes and to Predict Length of Stay in Patients admitted with Heart Failure
May 30, 2023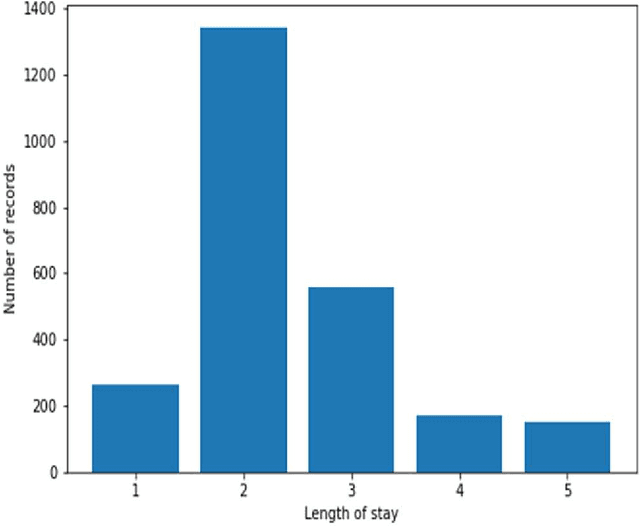
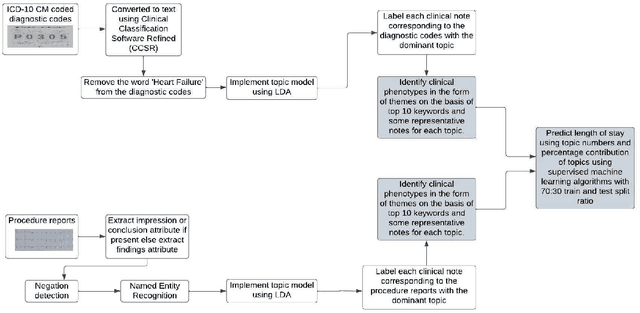
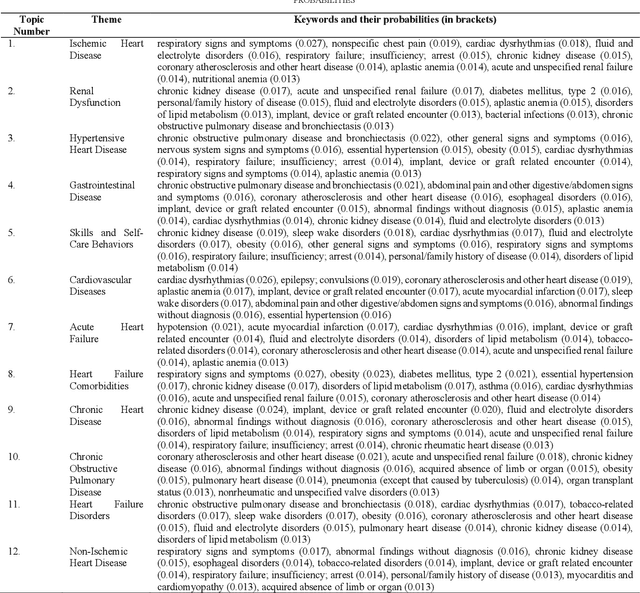
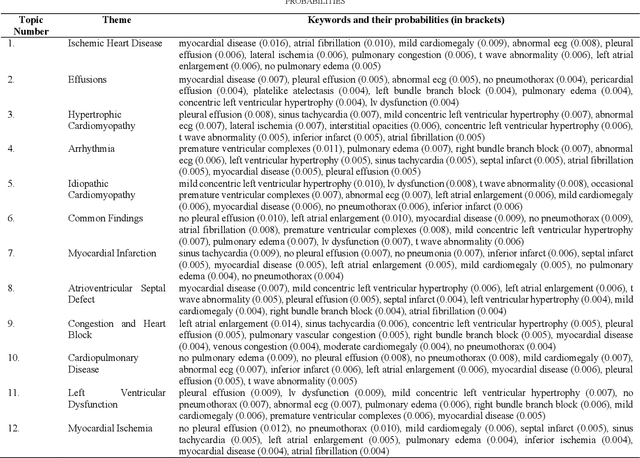
Heart failure is a syndrome which occurs when the heart is not able to pump blood and oxygen to support other organs in the body. Identifying the underlying themes in the diagnostic codes and procedure reports of patients admitted for heart failure could reveal the clinical phenotypes associated with heart failure and to group patients based on their similar characteristics which could also help in predicting patient outcomes like length of stay. These clinical phenotypes usually have a probabilistic latent structure and hence, as there has been no previous work on identifying phenotypes in clinical notes of heart failure patients using a probabilistic framework and to predict length of stay of these patients using data-driven artificial intelligence-based methods, we apply natural language processing technique, topic modeling, to identify the themes present in diagnostic codes and in procedure reports of 1,200 patients admitted for heart failure at the University of Illinois Hospital and Health Sciences System (UI Health). Topic modeling identified twelve themes each in diagnostic codes and procedure reports which revealed information about different phenotypes related to various perspectives about heart failure, to study patients' profiles and to discover new relationships among medical concepts. Each theme had a set of keywords and each clinical note was labeled with two themes - one corresponding to its diagnostic code and the other corresponding to its procedure reports along with their percentage contribution. We used these themes and their percentage contribution to predict length of stay. We found that the themes discovered in diagnostic codes and procedure reports using topic modeling together were able to predict length of stay of the patients with an accuracy of 61.1% and an Area under the Receiver Operating Characteristic Curve (ROC AUC) value of 0.828.
Leveraging Natural Learning Processing to Uncover Themes in Clinical Notes of Patients Admitted for Heart Failure
Apr 14, 2022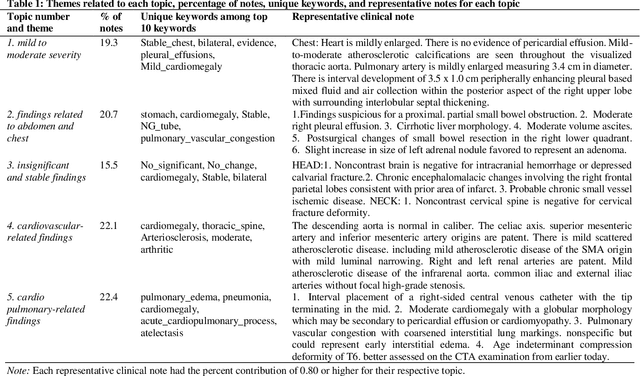
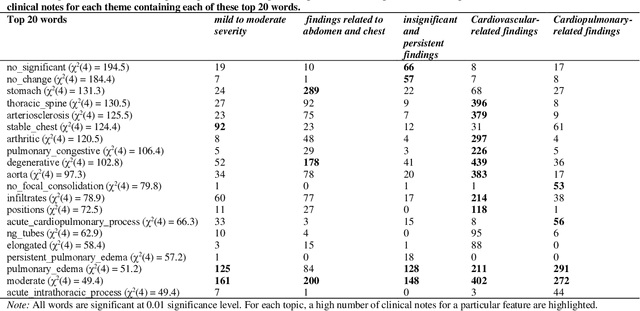
Heart failure occurs when the heart is not able to pump blood and oxygen to support other organs in the body as it should. Treatments include medications and sometimes hospitalization. Patients with heart failure can have both cardiovascular as well as non-cardiovascular comorbidities. Clinical notes of patients with heart failure can be analyzed to gain insight into the topics discussed in these notes and the major comorbidities in these patients. In this regard, we apply machine learning techniques, such as topic modeling, to identify the major themes found in the clinical notes specific to the procedures performed on 1,200 patients admitted for heart failure at the University of Illinois Hospital and Health Sciences System (UI Health). Topic modeling revealed five hidden themes in these clinical notes, including one related to heart disease comorbidities.
Predicting Early Indicators of Cognitive Decline from Verbal Utterances
Nov 19, 2020



Dementia is a group of irreversible, chronic, and progressive neurodegenerative disorders resulting in impaired memory, communication, and thought processes. In recent years, clinical research advances in brain aging have focused on the earliest clinically detectable stage of incipient dementia, commonly known as mild cognitive impairment (MCI). Currently, these disorders are diagnosed using a manual analysis of neuropsychological examinations. We measure the feasibility of using the linguistic characteristics of verbal utterances elicited during neuropsychological exams of elderly subjects to distinguish between elderly control groups, people with MCI, people diagnosed with possible Alzheimer's disease (AD), and probable AD. We investigated the performance of both theory-driven psycholinguistic features and data-driven contextual language embeddings in identifying different clinically diagnosed groups. Our experiments show that a combination of contextual and psycholinguistic features extracted by a Support Vector Machine improved distinguishing the verbal utterances of elderly controls, people with MCI, possible AD, and probable AD. This is the first work to identify four clinical diagnosis groups of dementia in a highly imbalanced dataset. Our work shows that machine learning algorithms built on contextual and psycholinguistic features can learn the linguistic biomarkers from verbal utterances and assist clinical diagnosis of different stages and types of dementia, even with limited data.
Leveraging Natural Language Processing to Mine Issues on Twitter During the COVID-19 Pandemic
Nov 03, 2020
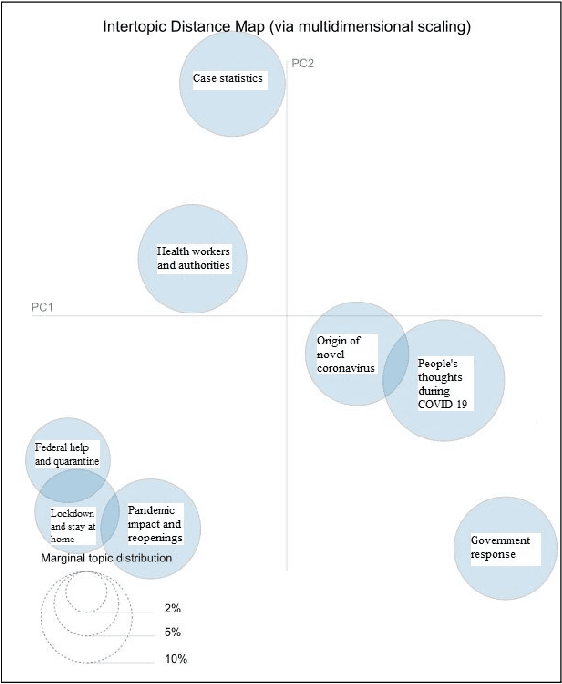
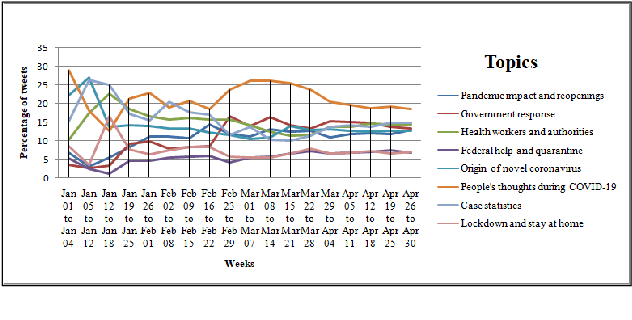
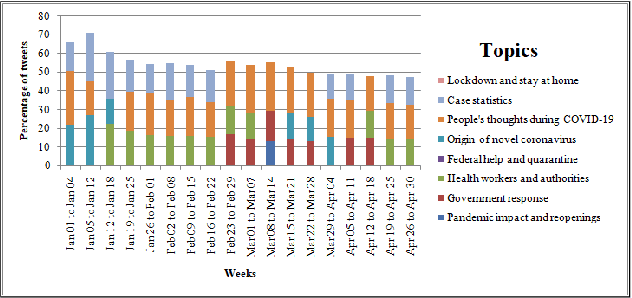
The recent global outbreak of the coronavirus disease (COVID-19) has spread to all corners of the globe. The international travel ban, panic buying, and the need for self-quarantine are among the many other social challenges brought about in this new era. Twitter platforms have been used in various public health studies to identify public opinion about an event at the local and global scale. To understand the public concerns and responses to the pandemic, a system that can leverage machine learning techniques to filter out irrelevant tweets and identify the important topics of discussion on social media platforms like Twitter is needed. In this study, we constructed a system to identify the relevant tweets related to the COVID-19 pandemic throughout January 1st, 2020 to April 30th, 2020, and explored topic modeling to identify the most discussed topics and themes during this period in our data set. Additionally, we analyzed the temporal changes in the topics with respect to the events that occurred during this pandemic. We found out that eight topics were sufficient to identify the themes in our corpus. These topics depicted a temporal trend. The dominant topics vary over time and align with the events related to the COVID-19 pandemic.