 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePain Forecasting using Self-supervised Learning and Patient Phenotyping: An attempt to prevent Opioid Addiction
Oct 09, 2023



Sickle Cell Disease (SCD) is a chronic genetic disorder characterized by recurrent acute painful episodes. Opioids are often used to manage these painful episodes; the extent of their use in managing pain in this disorder is an issue of debate. The risk of addiction and side effects of these opioid treatments can often lead to more pain episodes in the future. Hence, it is crucial to forecast future patient pain trajectories to help patients manage their SCD to improve their quality of life without compromising their treatment. It is challenging to obtain many pain records to design forecasting models since it is mainly recorded by patients' self-report. Therefore, it is expensive and painful (due to the need for patient compliance) to solve pain forecasting problems in a purely supervised manner. In light of this challenge, we propose to solve the pain forecasting problem using self-supervised learning methods. Also, clustering such time-series data is crucial for patient phenotyping, anticipating patients' prognoses by identifying "similar" patients, and designing treatment guidelines tailored to homogeneous patient subgroups. Hence, we propose a self-supervised learning approach for clustering time-series data, where each cluster comprises patients who share similar future pain profiles. Experiments on five years of real-world datasets show that our models achieve superior performance over state-of-the-art benchmarks and identify meaningful clusters that can be translated into actionable information for clinical decision-making.
Exploring Language Patterns in a Medical Licensure Exam Item Bank
Nov 20, 2021


This study examines the use of natural language processing (NLP) models to evaluate whether language patterns used by item writers in a medical licensure exam might contain evidence of biased or stereotypical language. This type of bias in item language choices can be particularly impactful for items in a medical licensure assessment, as it could pose a threat to content validity and defensibility of test score validity evidence. To the best of our knowledge, this is the first attempt using machine learning (ML) and NLP to explore language bias on a large item bank. Using a prediction algorithm trained on clusters of similar item stems, we demonstrate that our approach can be used to review large item banks for potential biased language or stereotypical patient characteristics in clinical science vignettes. The findings may guide the development of methods to address stereotypical language patterns found in test items and enable an efficient updating of those items, if needed, to reflect contemporary norms, thereby improving the evidence to support the validity of the test scores.
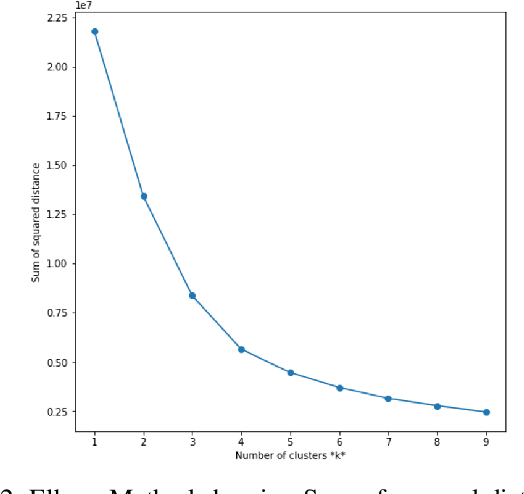
Clustering of Pain Dynamics in Sickle Cell Disease from Sparse, Uneven Samples
Aug 31, 2021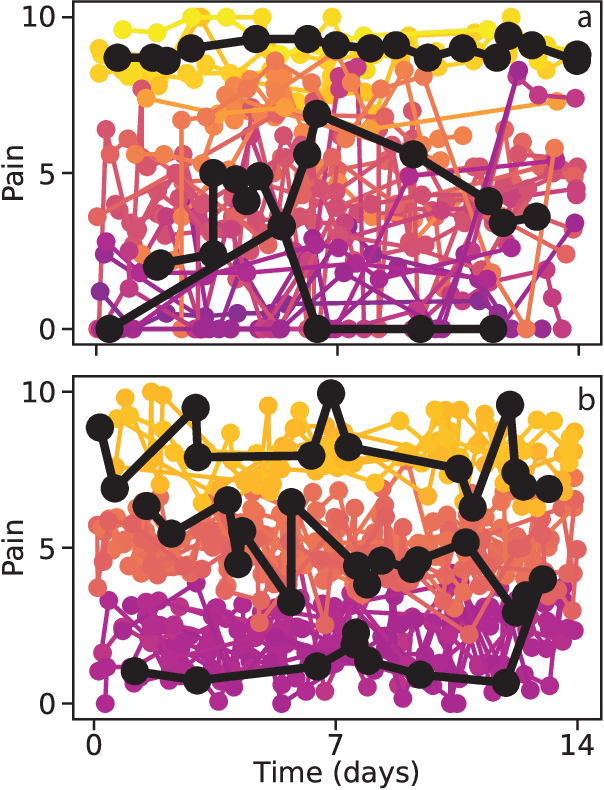

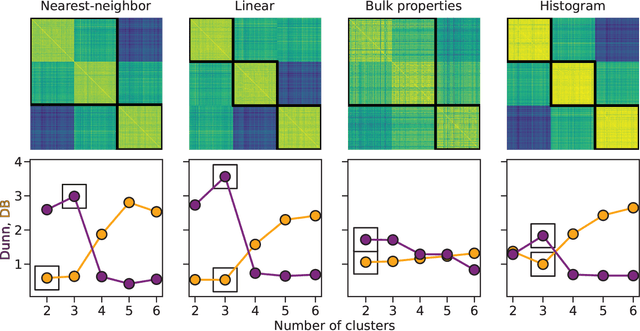
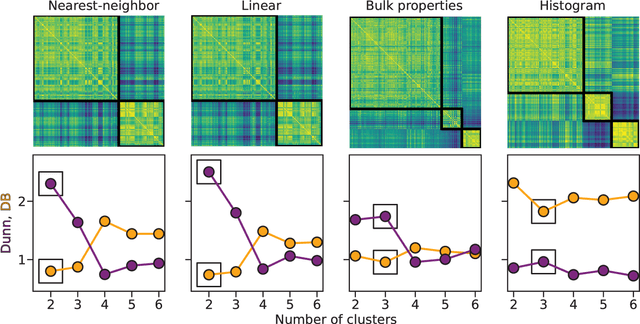
Irregularly sampled time series data are common in a variety of fields. Many typical methods for drawing insight from data fail in this case. Here we attempt to generalize methods for clustering trajectories to irregularly and sparsely sampled data. We first construct synthetic data sets, then propose and assess four methods of data alignment to allow for application of spectral clustering. We also repeat the same process for real data drawn from medical records of patients with sickle cell disease -- patients whose subjective experiences of pain were tracked for several months via a mobile app. We find that different methods for aligning irregularly sampled sparse data sets can lead to different optimal numbers of clusters, even for synthetic data with known properties. For the case of sickle cell disease, we find that three clusters is a reasonable choice, and these appear to correspond to (1) a low pain group with occasionally acute pain, (2) a group which experiences moderate mean pain that fluctuates often from low to high, and (3) a group that experiences persistent high levels of pain. Our results may help physicians and patients better understand and manage patients' pain levels over time, and we expect that the methods we develop will apply to a wide range of other data sources in medicine and beyond.
Pain Intensity Assessment in Sickle Cell Disease patients using Vital Signs during Hospital Visits
Nov 24, 2020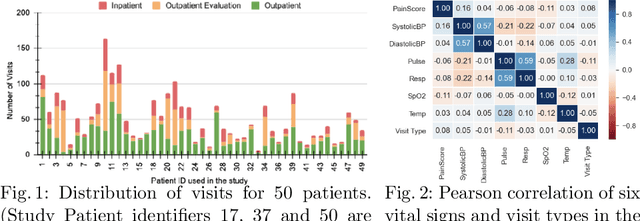
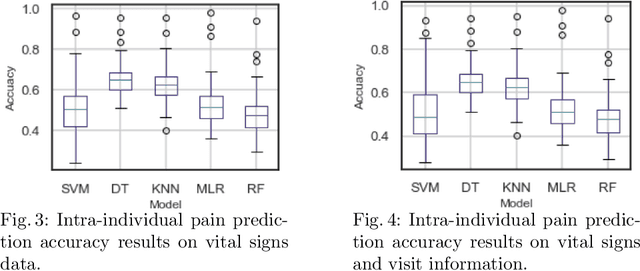
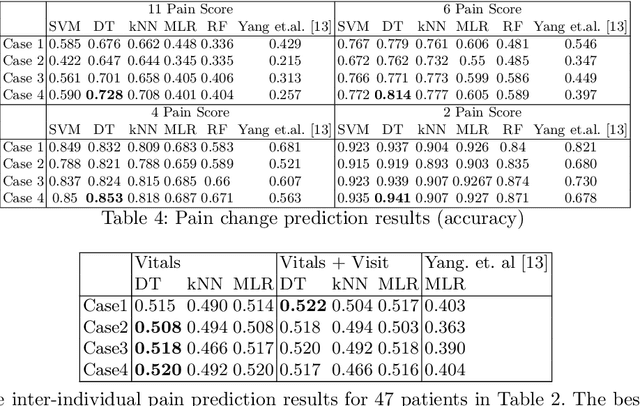
Pain in sickle cell disease (SCD) is often associated with increased morbidity, mortality, and high healthcare costs. The standard method for predicting the absence, presence, and intensity of pain has long been self-report. However, medical providers struggle to manage patients based on subjective pain reports correctly and pain medications often lead to further difficulties in patient communication as they may cause sedation and sleepiness. Recent studies have shown that objective physiological measures can predict subjective self-reported pain scores for inpatient visits using machine learning (ML) techniques. In this study, we evaluate the generalizability of ML techniques to data collected from 50 patients over an extended period across three types of hospital visits (i.e., inpatient, outpatient and outpatient evaluation). We compare five classification algorithms for various pain intensity levels at both intra-individual (within each patient) and inter-individual (between patients) level. While all the tested classifiers perform much better than chance, a Decision Tree (DT) model performs best at predicting pain on an 11-point severity scale (from 0-10) with an accuracy of 0.728 at an inter-individual level and 0.653 at an intra-individual level. The accuracy of DT significantly improves to 0.941 on a 2-point rating scale (i.e., no/mild pain: 0-5, severe pain: 6-10) at an intra-individual level. Our experimental results demonstrate that ML techniques can provide an objective and quantitative evaluation of pain intensity levels for all three types of hospital visits.
COVID-19 and Mental Health/Substance Use Disorders on Reddit: A Longitudinal Study
Nov 20, 2020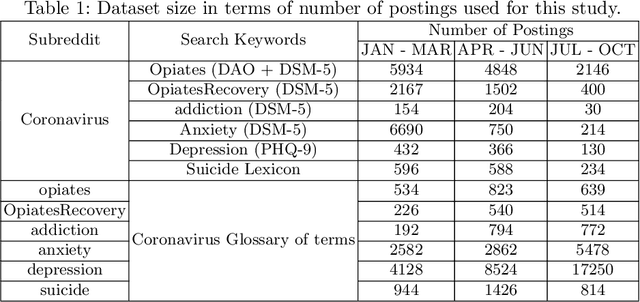
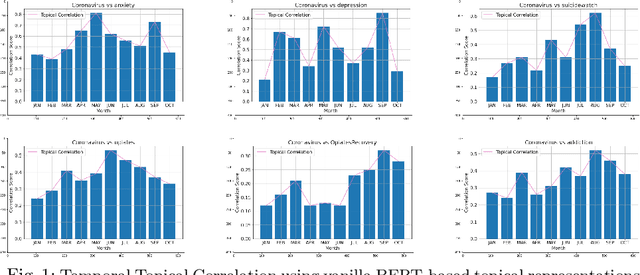
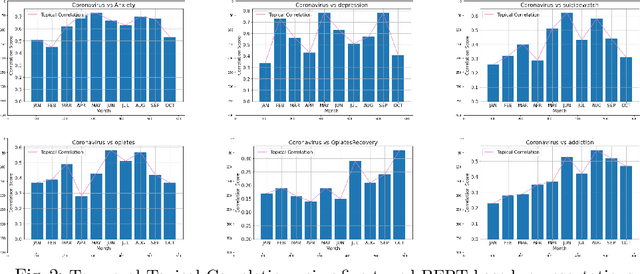

COVID-19 pandemic has adversely and disproportionately impacted people suffering from mental health issues and substance use problems. This has been exacerbated by social isolation during the pandemic and the social stigma associated with mental health and substance use disorders, making people reluctant to share their struggles and seek help. Due to the anonymity and privacy they provide, social media emerged as a convenient medium for people to share their experiences about their day to day struggles. Reddit is a well-recognized social media platform that provides focused and structured forums called subreddits, that users subscribe to and discuss their experiences with others. Temporal assessment of the topical correlation between social media postings about mental health/substance use and postings about Coronavirus is crucial to better understand public sentiment on the pandemic and its evolving impact, especially related to vulnerable populations. In this study, we conduct a longitudinal topical analysis of postings between subreddits r/depression, r/Anxiety, r/SuicideWatch, and r/Coronavirus, and postings between subreddits r/opiates, r/OpiatesRecovery, r/addiction, and r/Coronavirus from January 2020 - October 2020. Our results show a high topical correlation between postings in r/depression and r/Coronavirus in September 2020. Further, the topical correlation between postings on substance use disorders and Coronavirus fluctuates, showing the highest correlation in August 2020. By monitoring these trends from platforms such as Reddit, epidemiologists, and mental health professionals can gain insights into the challenges faced by communities for targeted interventions.
Predicting Early Indicators of Cognitive Decline from Verbal Utterances
Nov 19, 2020



Dementia is a group of irreversible, chronic, and progressive neurodegenerative disorders resulting in impaired memory, communication, and thought processes. In recent years, clinical research advances in brain aging have focused on the earliest clinically detectable stage of incipient dementia, commonly known as mild cognitive impairment (MCI). Currently, these disorders are diagnosed using a manual analysis of neuropsychological examinations. We measure the feasibility of using the linguistic characteristics of verbal utterances elicited during neuropsychological exams of elderly subjects to distinguish between elderly control groups, people with MCI, people diagnosed with possible Alzheimer's disease (AD), and probable AD. We investigated the performance of both theory-driven psycholinguistic features and data-driven contextual language embeddings in identifying different clinically diagnosed groups. Our experiments show that a combination of contextual and psycholinguistic features extracted by a Support Vector Machine improved distinguishing the verbal utterances of elderly controls, people with MCI, possible AD, and probable AD. This is the first work to identify four clinical diagnosis groups of dementia in a highly imbalanced dataset. Our work shows that machine learning algorithms built on contextual and psycholinguistic features can learn the linguistic biomarkers from verbal utterances and assist clinical diagnosis of different stages and types of dementia, even with limited data.
Topic-Centric Unsupervised Multi-Document Summarization of Scientific and News Articles
Nov 03, 2020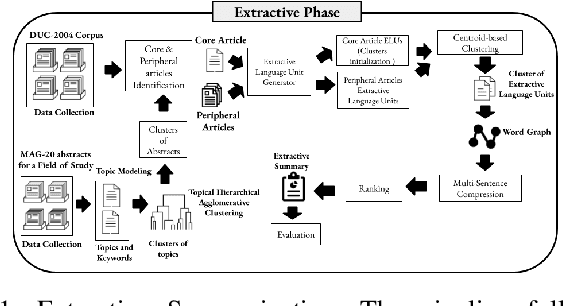


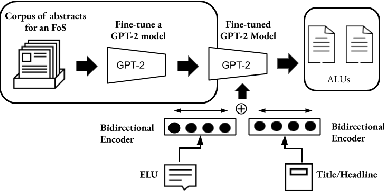
Recent advances in natural language processing have enabled automation of a wide range of tasks, including machine translation, named entity recognition, and sentiment analysis. Automated summarization of documents, or groups of documents, however, has remained elusive, with many efforts limited to extraction of keywords, key phrases, or key sentences. Accurate abstractive summarization has yet to be achieved due to the inherent difficulty of the problem, and limited availability of training data. In this paper, we propose a topic-centric unsupervised multi-document summarization framework to generate extractive and abstractive summaries for groups of scientific articles across 20 Fields of Study (FoS) in Microsoft Academic Graph (MAG) and news articles from DUC-2004 Task 2. The proposed algorithm generates an abstractive summary by developing salient language unit selection and text generation techniques. Our approach matches the state-of-the-art when evaluated on automated extractive evaluation metrics and performs better for abstractive summarization on five human evaluation metrics (entailment, coherence, conciseness, readability, and grammar). We achieve a kappa score of 0.68 between two co-author linguists who evaluated our results. We plan to publicly share MAG-20, a human-validated gold standard dataset of topic-clustered research articles and their summaries to promote research in abstractive summarization.
Leveraging Natural Language Processing to Mine Issues on Twitter During the COVID-19 Pandemic
Nov 03, 2020
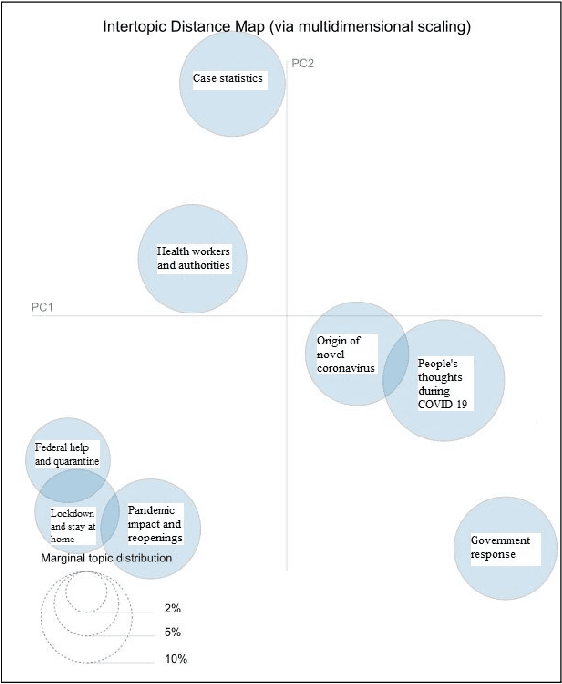
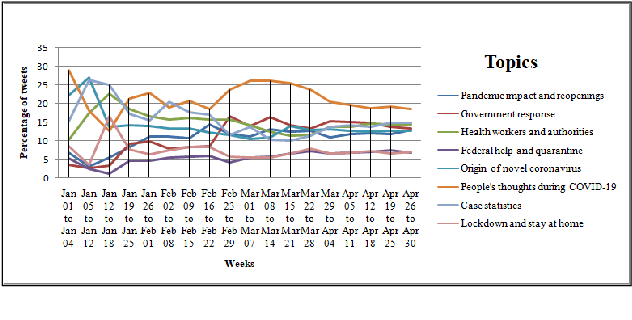
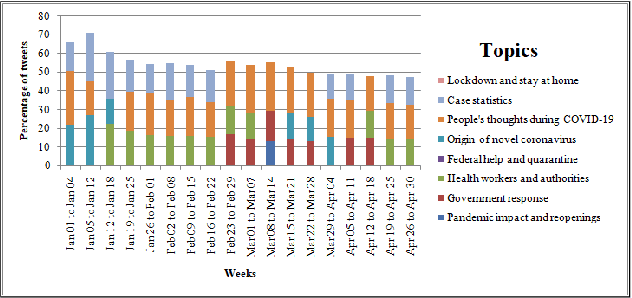
The recent global outbreak of the coronavirus disease (COVID-19) has spread to all corners of the globe. The international travel ban, panic buying, and the need for self-quarantine are among the many other social challenges brought about in this new era. Twitter platforms have been used in various public health studies to identify public opinion about an event at the local and global scale. To understand the public concerns and responses to the pandemic, a system that can leverage machine learning techniques to filter out irrelevant tweets and identify the important topics of discussion on social media platforms like Twitter is needed. In this study, we constructed a system to identify the relevant tweets related to the COVID-19 pandemic throughout January 1st, 2020 to April 30th, 2020, and explored topic modeling to identify the most discussed topics and themes during this period in our data set. Additionally, we analyzed the temporal changes in the topics with respect to the events that occurred during this pandemic. We found out that eight topics were sufficient to identify the themes in our corpus. These topics depicted a temporal trend. The dominant topics vary over time and align with the events related to the COVID-19 pandemic.
Clustering of Social Media Messages for Humanitarian Aid Response during Crisis
Jul 23, 2020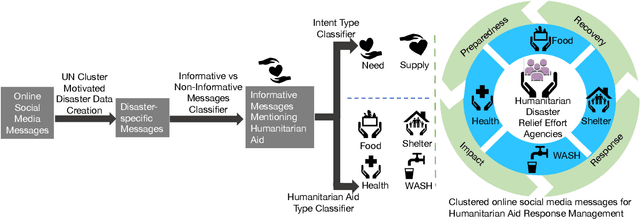
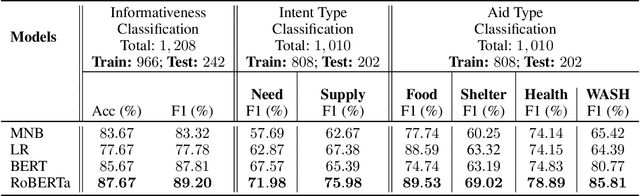


Social media has quickly grown into an essential tool for people to communicate and express their needs during crisis events. Prior work in analyzing social media data for crisis management has focused primarily on automatically identifying actionable (or, informative) crisis-related messages. In this work, we show that recent advances in Deep Learning and Natural Language Processing outperform prior approaches for the task of classifying informativeness and encourage the field to adopt them for their research or even deployment. We also extend these methods to two sub-tasks of informativeness and find that the Deep Learning methods are effective here as well.
Knowledge Graphs and Knowledge Networks: The Story in Brief
Mar 07, 2020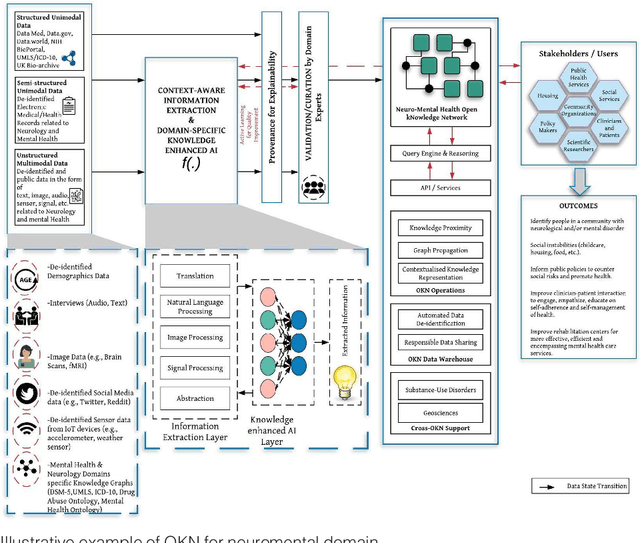
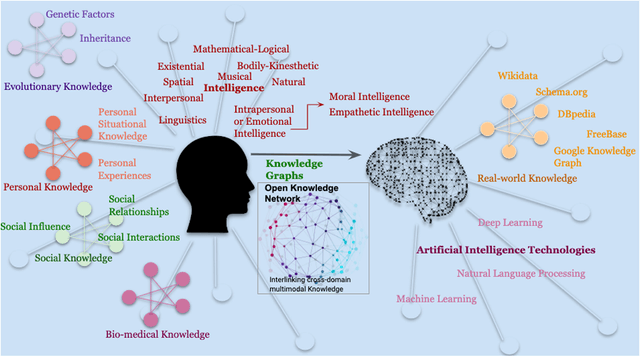
Knowledge Graphs (KGs) represent real-world noisy raw information in a structured form, capturing relationships between entities. However, for dynamic real-world applications such as social networks, recommender systems, computational biology, relational knowledge representation has emerged as a challenging research problem where there is a need to represent the changing nodes, attributes, and edges over time. The evolution of search engine responses to user queries in the last few years is partly because of the role of KGs such as Google KG. KGs are significantly contributing to various AI applications from link prediction, entity relations prediction, node classification to recommendation and question answering systems. This article is an attempt to summarize the journey of KG for AI.