 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Language Patterns in a Medical Licensure Exam Item Bank
Nov 20, 2021
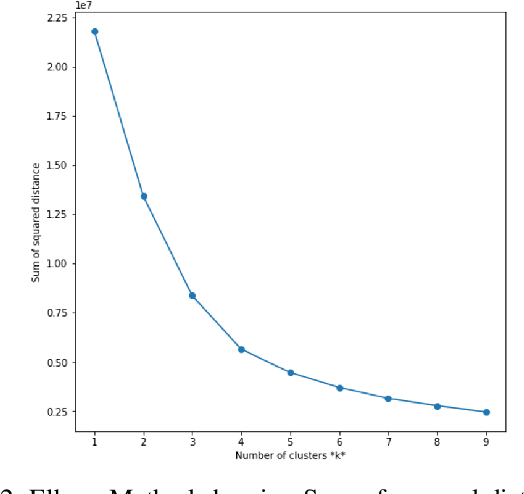


This study examines the use of natural language processing (NLP) models to evaluate whether language patterns used by item writers in a medical licensure exam might contain evidence of biased or stereotypical language. This type of bias in item language choices can be particularly impactful for items in a medical licensure assessment, as it could pose a threat to content validity and defensibility of test score validity evidence. To the best of our knowledge, this is the first attempt using machine learning (ML) and NLP to explore language bias on a large item bank. Using a prediction algorithm trained on clusters of similar item stems, we demonstrate that our approach can be used to review large item banks for potential biased language or stereotypical patient characteristics in clinical science vignettes. The findings may guide the development of methods to address stereotypical language patterns found in test items and enable an efficient updating of those items, if needed, to reflect contemporary norms, thereby improving the evidence to support the validity of the test scores.