 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Human-Compatible XAI: Explaining Data Differentials with Concept Induction over Background Knowledge
Sep 27, 2022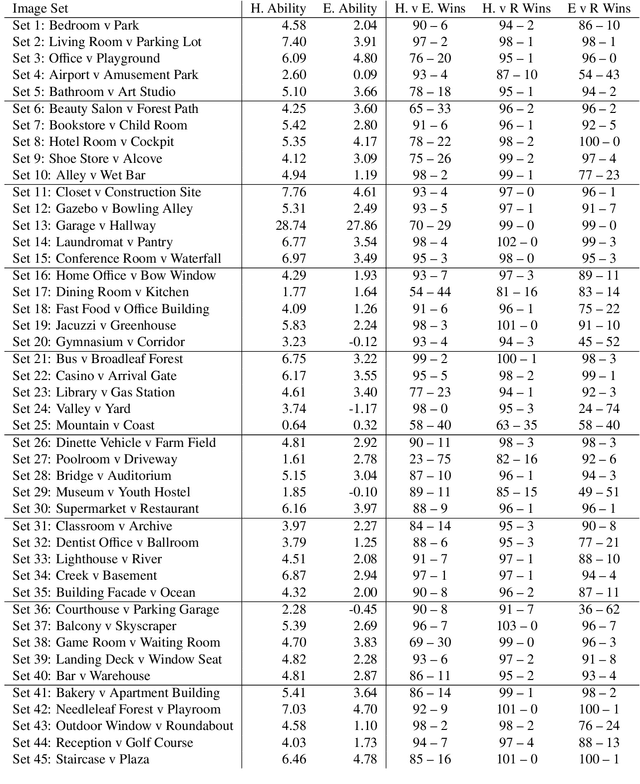

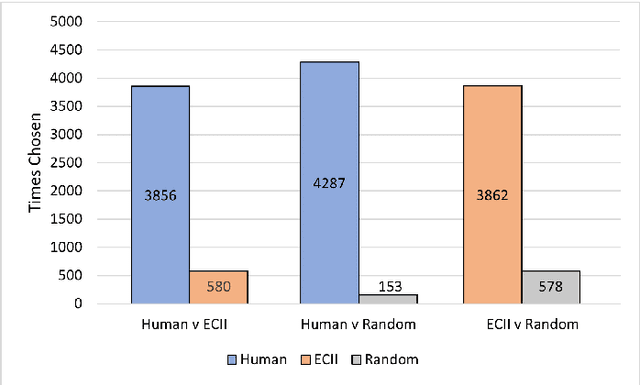
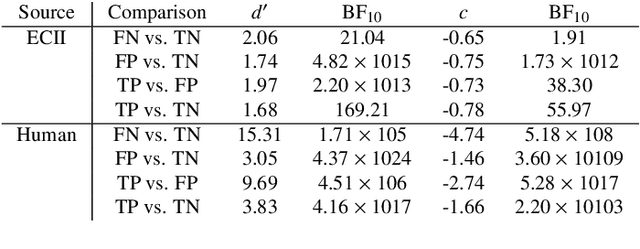
Concept induction, which is based on formal logical reasoning over description logics, has been used in ontology engineering in order to create ontology (TBox) axioms from the base data (ABox) graph. In this paper, we show that it can also be used to explain data differentials, for example in the context of Explainable AI (XAI), and we show that it can in fact be done in a way that is meaningful to a human observer. Our approach utilizes a large class hierarchy, curated from the Wikipedia category hierarchy, as background knowledge.
Entity-driven Fact-aware Abstractive Summarization of Biomedical Literature
Mar 30, 2022



As part of the large number of scientific articles being published every year, the publication rate of biomedical literature has been increasing. Consequently, there has been considerable effort to harness and summarize the massive amount of biomedical research articles. While transformer-based encoder-decoder models in a vanilla source document-to-summary setting have been extensively studied for abstractive summarization in different domains, their major limitations continue to be entity hallucination (a phenomenon where generated summaries constitute entities not related to or present in source article(s)) and factual inconsistency. This problem is exacerbated in a biomedical setting where named entities and their semantics (which can be captured through a knowledge base) constitute the essence of an article. The use of named entities and facts mined from background knowledge bases pertaining to the named entities to guide abstractive summarization has not been studied in biomedical article summarization literature. In this paper, we propose an entity-driven fact-aware framework for training end-to-end transformer-based encoder-decoder models for abstractive summarization of biomedical articles. We call the proposed approach, whose building block is a transformer-based model, EFAS, Entity-driven Fact-aware Abstractive Summarization. We conduct experiments using five state-of-the-art transformer-based models (two of which are specifically designed for long document summarization) and demonstrate that injecting knowledge into the training/inference phase of these models enables the models to achieve significantly better performance than the standard source document-to-summary setting in terms of entity-level factual accuracy, N-gram novelty, and semantic equivalence while performing comparably on ROUGE metrics. The proposed approach is evaluated on ICD-11-Summ-1000, and PubMed-50k.
Topic-Centric Unsupervised Multi-Document Summarization of Scientific and News Articles
Nov 03, 2020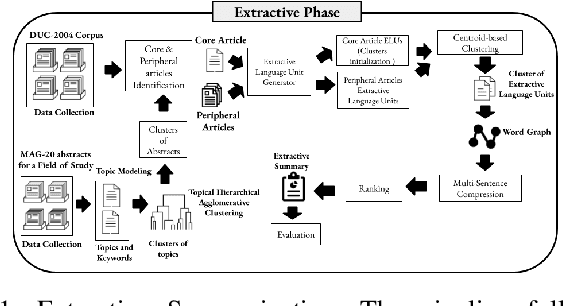


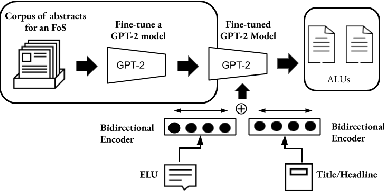
Recent advances in natural language processing have enabled automation of a wide range of tasks, including machine translation, named entity recognition, and sentiment analysis. Automated summarization of documents, or groups of documents, however, has remained elusive, with many efforts limited to extraction of keywords, key phrases, or key sentences. Accurate abstractive summarization has yet to be achieved due to the inherent difficulty of the problem, and limited availability of training data. In this paper, we propose a topic-centric unsupervised multi-document summarization framework to generate extractive and abstractive summaries for groups of scientific articles across 20 Fields of Study (FoS) in Microsoft Academic Graph (MAG) and news articles from DUC-2004 Task 2. The proposed algorithm generates an abstractive summary by developing salient language unit selection and text generation techniques. Our approach matches the state-of-the-art when evaluated on automated extractive evaluation metrics and performs better for abstractive summarization on five human evaluation metrics (entailment, coherence, conciseness, readability, and grammar). We achieve a kappa score of 0.68 between two co-author linguists who evaluated our results. We plan to publicly share MAG-20, a human-validated gold standard dataset of topic-clustered research articles and their summaries to promote research in abstractive summarization.
Relating Input Concepts to Convolutional Neural Network Decisions
Nov 21, 2017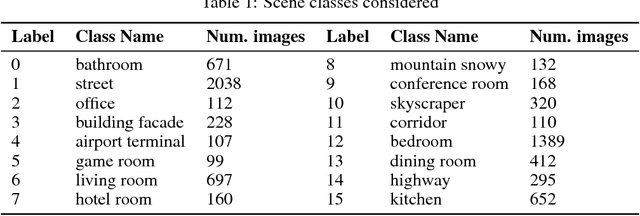


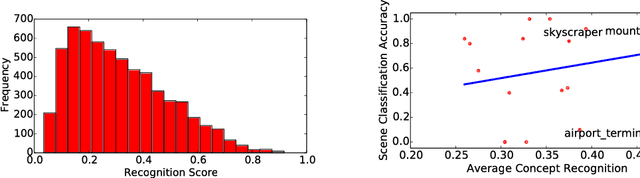
Many current methods to interpret convolutional neural networks (CNNs) use visualization techniques and words to highlight concepts of the input seemingly relevant to a CNN's decision. The methods hypothesize that the recognition of these concepts are instrumental in the decision a CNN reaches, but the nature of this relationship has not been well explored. To address this gap, this paper examines the quality of a concept's recognition by a CNN and the degree to which the recognitions are associated with CNN decisions. The study considers a CNN trained for scene recognition over the ADE20k dataset. It uses a novel approach to find and score the strength of minimally distributed representations of input concepts (defined by objects in scene images) across late stage feature maps. Subsequent analysis finds evidence that concept recognition impacts decision making. Strong recognition of concepts frequently-occurring in few scenes are indicative of correct decisions, but recognizing concepts common to many scenes may mislead the network.
Explaining Trained Neural Networks with Semantic Web Technologies: First Steps
Oct 11, 2017


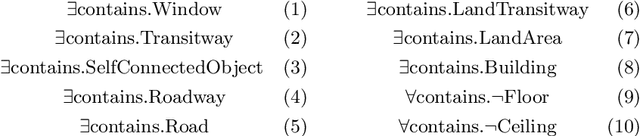
The ever increasing prevalence of publicly available structured data on the World Wide Web enables new applications in a variety of domains. In this paper, we provide a conceptual approach that leverages such data in order to explain the input-output behavior of trained artificial neural networks. We apply existing Semantic Web technologies in order to provide an experimental proof of concept.