 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Value of Labeled Data and Symbolic Methods for Hidden Neuron Activation Analysis
Apr 21, 2024A major challenge in Explainable AI is in correctly interpreting activations of hidden neurons: accurate interpretations would help answer the question of what a deep learning system internally detects as relevant in the input, demystifying the otherwise black-box nature of deep learning systems. The state of the art indicates that hidden node activations can, in some cases, be interpretable in a way that makes sense to humans, but systematic automated methods that would be able to hypothesize and verify interpretations of hidden neuron activations are underexplored. This is particularly the case for approaches that can both draw explanations from substantial background knowledge, and that are based on inherently explainable (symbolic) methods. In this paper, we introduce a novel model-agnostic post-hoc Explainable AI method demonstrating that it provides meaningful interpretations. Our approach is based on using a Wikipedia-derived concept hierarchy with approximately 2 million classes as background knowledge, and utilizes OWL-reasoning-based Concept Induction for explanation generation. Additionally, we explore and compare the capabilities of off-the-shelf pre-trained multimodal-based explainable methods. Our results indicate that our approach can automatically attach meaningful class expressions as explanations to individual neurons in the dense layer of a Convolutional Neural Network. Evaluation through statistical analysis and degree of concept activation in the hidden layer show that our method provides a competitive edge in both quantitative and qualitative aspects compared to prior work.
Advancements in Generative AI: A Comprehensive Review of GANs, GPT, Autoencoders, Diffusion Model, and Transformers
Nov 21, 2023The launch of ChatGPT has garnered global attention, marking a significant milestone in the field of Generative Artificial Intelligence. While Generative AI has been in effect for the past decade, the introduction of ChatGPT has ignited a new wave of research and innovation in the AI domain. This surge in interest has led to the development and release of numerous cutting-edge tools, such as Bard, Stable Diffusion, DALL-E, Make-A-Video, Runway ML, and Jukebox, among others. These tools exhibit remarkable capabilities, encompassing tasks ranging from text generation and music composition, image creation, video production, code generation, and even scientific work. They are built upon various state-of-the-art models, including Stable Diffusion, transformer models like GPT-3 (recent GPT-4), variational autoencoders, and generative adversarial networks. This advancement in Generative AI presents a wealth of exciting opportunities and, simultaneously, unprecedented challenges. Throughout this paper, we have explored these state-of-the-art models, the diverse array of tasks they can accomplish, the challenges they pose, and the promising future of Generative Artificial Intelligence.
Understanding CNN Hidden Neuron Activations Using Structured Background Knowledge and Deductive Reasoning
Aug 09, 2023A major challenge in Explainable AI is in correctly interpreting activations of hidden neurons: accurate interpretations would provide insights into the question of what a deep learning system has internally detected as relevant on the input, demystifying the otherwise black-box character of deep learning systems. The state of the art indicates that hidden node activations can, in some cases, be interpretable in a way that makes sense to humans, but systematic automated methods that would be able to hypothesize and verify interpretations of hidden neuron activations are underexplored. In this paper, we provide such a method and demonstrate that it provides meaningful interpretations. Our approach is based on using large-scale background knowledge approximately 2 million classes curated from the Wikipedia concept hierarchy together with a symbolic reasoning approach called Concept Induction based on description logics, originally developed for applications in the Semantic Web field. Our results show that we can automatically attach meaningful labels from the background knowledge to individual neurons in the dense layer of a Convolutional Neural Network through a hypothesis and verification process.
Explaining Deep Learning Hidden Neuron Activations using Concept Induction
Jan 23, 2023One of the current key challenges in Explainable AI is in correctly interpreting activations of hidden neurons. It seems evident that accurate interpretations thereof would provide insights into the question what a deep learning system has internally \emph{detected} as relevant on the input, thus lifting some of the black box character of deep learning systems. The state of the art on this front indicates that hidden node activations appear to be interpretable in a way that makes sense to humans, at least in some cases. Yet, systematic automated methods that would be able to first hypothesize an interpretation of hidden neuron activations, and then verify it, are mostly missing. In this paper, we provide such a method and demonstrate that it provides meaningful interpretations. It is based on using large-scale background knowledge -- a class hierarchy of approx. 2 million classes curated from the Wikipedia Concept Hierarchy -- together with a symbolic reasoning approach called \emph{concept induction} based on description logics that was originally developed for applications in the Semantic Web field. Our results show that we can automatically attach meaningful labels from the background knowledge to individual neurons in the dense layer of a Convolutional Neural Network through a hypothesis and verification process.
Towards Human-Compatible XAI: Explaining Data Differentials with Concept Induction over Background Knowledge
Sep 27, 2022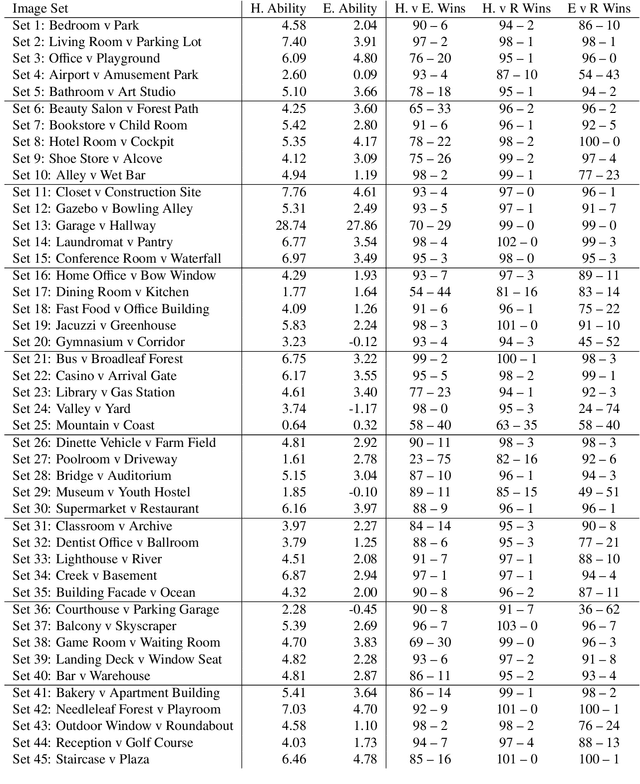

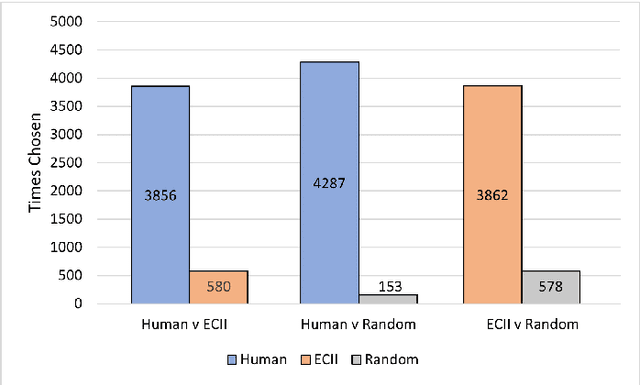
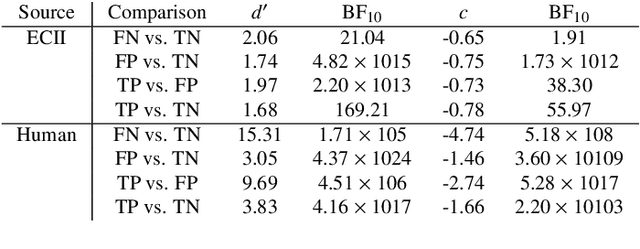
Concept induction, which is based on formal logical reasoning over description logics, has been used in ontology engineering in order to create ontology (TBox) axioms from the base data (ABox) graph. In this paper, we show that it can also be used to explain data differentials, for example in the context of Explainable AI (XAI), and we show that it can in fact be done in a way that is meaningful to a human observer. Our approach utilizes a large class hierarchy, curated from the Wikipedia category hierarchy, as background knowledge.
Neuro-Symbolic Artificial Intelligence: Current Trends
May 14, 2021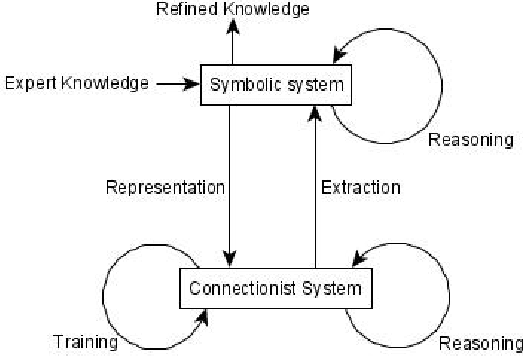

Neuro-Symbolic Artificial Intelligence -- the combination of symbolic methods with methods that are based on artificial neural networks -- has a long-standing history. In this article, we provide a structured overview of current trends, by means of categorizing recent publications from key conferences. The article is meant to serve as a convenient starting point for research on the general topic.
Neural Fuzzy Extractors: A Secure Way to Use Artificial Neural Networks for Biometric User Authentication
Mar 18, 2020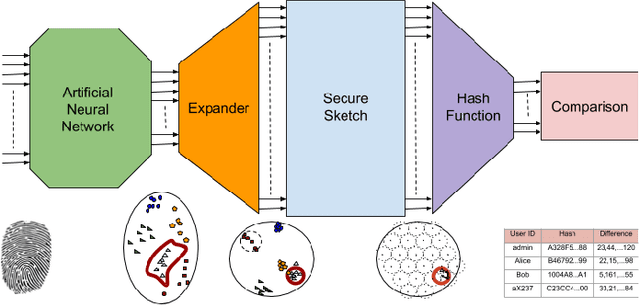
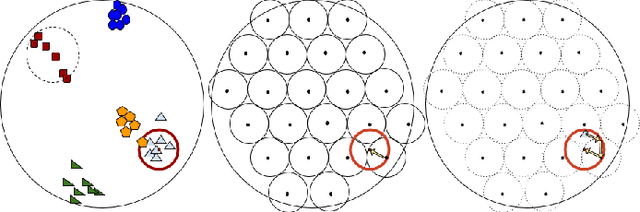
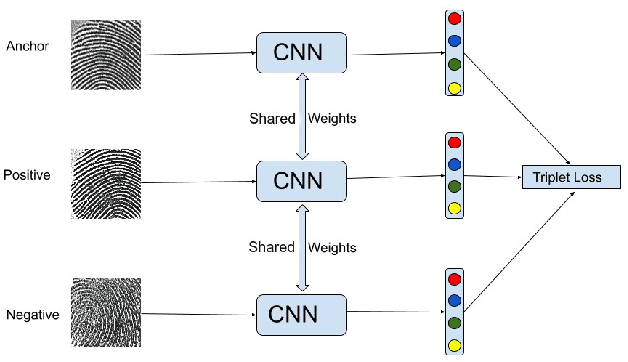
Powered by new advances in sensor development and artificial intelligence, the decreasing cost of computation, and the pervasiveness of handheld computation devices, biometric user authentication (and identification) is rapidly becoming ubiquitous. Modern approaches to biometric authentication, based on sophisticated machine learning techniques, cannot avoid storing either trained-classifier details or explicit user biometric data, thus exposing users' credentials to falsification. In this paper, we introduce a secure way to handle user-specific information involved with the use of vector-space classifiers or artificial neural networks for biometric authentication. Our proposed architecture, called a Neural Fuzzy Extractor (NFE), allows the coupling of pre-existing classifiers with fuzzy extractors, through a artificial-neural-network-based buffer called an expander, with minimal or no performance degradation. The NFE thus offers all the performance advantages of modern deep-learning-based classifiers, and all the security of standard fuzzy extractors. We demonstrate the NFE retrofit to a classic artificial neural network for a simple scenario of fingerprint-based user authentication.
Efficient Concept Induction for Description Logics
Dec 08, 2018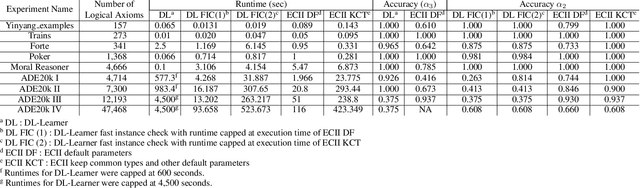
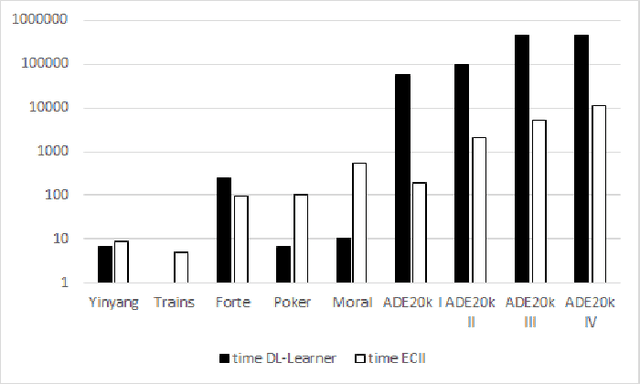
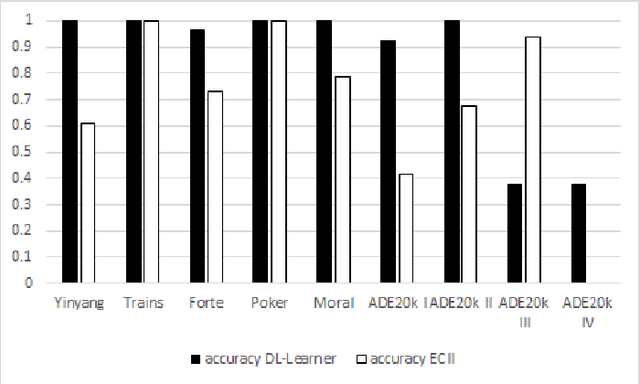
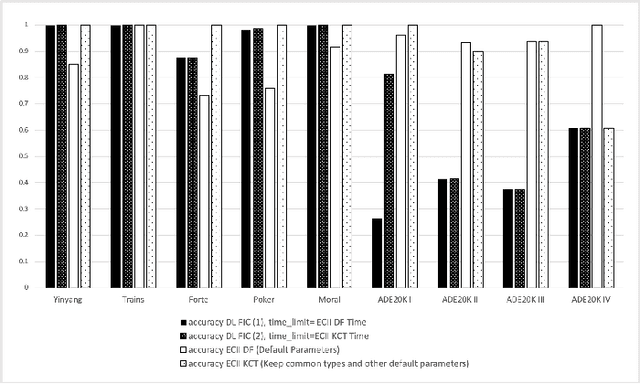
Concept Induction refers to the problem of creating complex Description Logic class descriptions (i.e., TBox axioms) from instance examples (i.e., ABox data). In this paper we look particularly at the case where both a set of positive and a set of negative instances are given, and complex class expressions are sought under which the positive but not the negative examples fall. Concept induction has found applications in ontology engineering, but existing algorithms have fundamental performance issues in some scenarios, mainly because a high number of invokations of an external Description Logic reasoner is usually required. In this paper we present a new algorithm for this problem which drastically reduces the number of reasoner invokations needed. While this comes at the expense of a more limited traversal of the search space, we show that our approach improves execution times by up to several orders of magnitude, while output correctness, measured in the amount of correct coverage of the input instances, remains reasonably high in many cases. Our approach thus should provide a strong alternative to existing systems, in particular in settings where other systems are prohibitively slow.
Reasoning over RDF Knowledge Bases using Deep Learning
Nov 09, 2018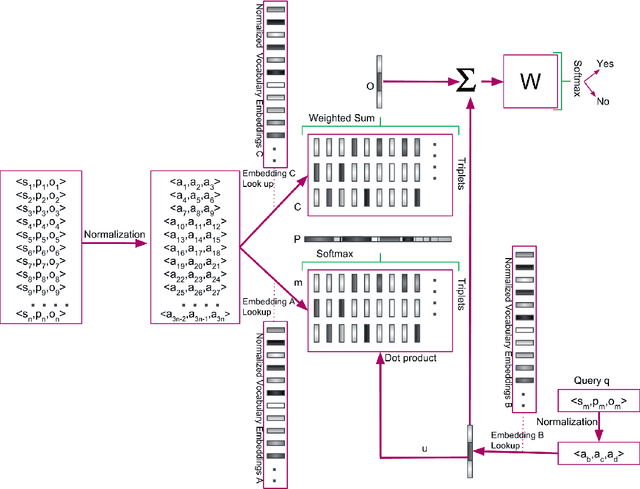


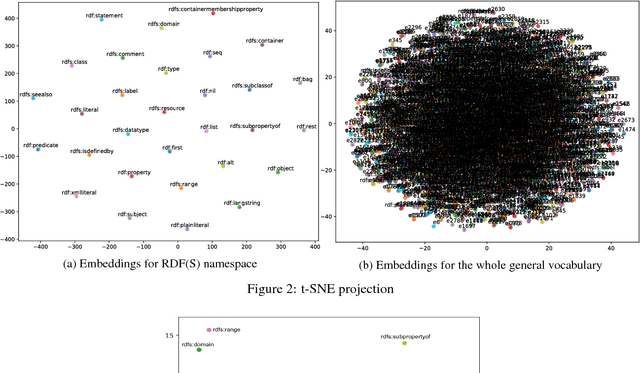
Semantic Web knowledge representation standards, and in particular RDF and OWL, often come endowed with a formal semantics which is considered to be of fundamental importance for the field. Reasoning, i.e., the drawing of logical inferences from knowledge expressed in such standards, is traditionally based on logical deductive methods and algorithms which can be proven to be sound and complete and terminating, i.e. correct in a very strong sense. For various reasons, though, in particular, the scalability issues arising from the ever-increasing amounts of Semantic Web data available and the inability of deductive algorithms to deal with noise in the data, it has been argued that alternative means of reasoning should be investigated which bear high promise for high scalability and better robustness. From this perspective, deductive algorithms can be considered the gold standard regarding correctness against which alternative methods need to be tested. In this paper, we show that it is possible to train a Deep Learning system on RDF knowledge graphs, such that it is able to perform reasoning over new RDF knowledge graphs, with high precision and recall compared to the deductive gold standard.
Relating Input Concepts to Convolutional Neural Network Decisions
Nov 21, 2017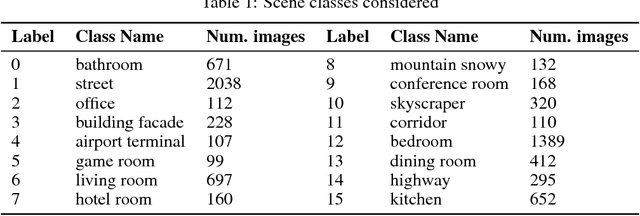


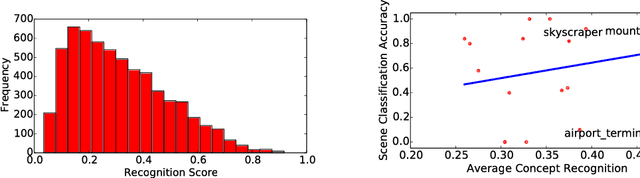
Many current methods to interpret convolutional neural networks (CNNs) use visualization techniques and words to highlight concepts of the input seemingly relevant to a CNN's decision. The methods hypothesize that the recognition of these concepts are instrumental in the decision a CNN reaches, but the nature of this relationship has not been well explored. To address this gap, this paper examines the quality of a concept's recognition by a CNN and the degree to which the recognitions are associated with CNN decisions. The study considers a CNN trained for scene recognition over the ADE20k dataset. It uses a novel approach to find and score the strength of minimally distributed representations of input concepts (defined by objects in scene images) across late stage feature maps. Subsequent analysis finds evidence that concept recognition impacts decision making. Strong recognition of concepts frequently-occurring in few scenes are indicative of correct decisions, but recognizing concepts common to many scenes may mislead the network.