 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Deep Learning: A Field Guide for the Uninitiated
Apr 30, 2020

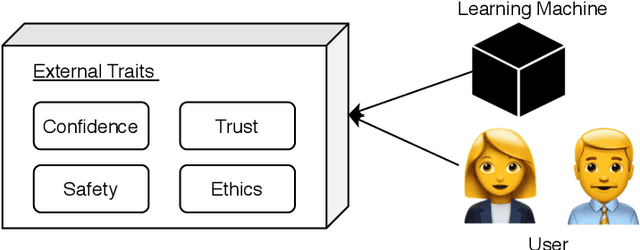

Deep neural network (DNN) is an indispensable machine learning tool for achieving human-level performance on many learning tasks. Yet, due to its black-box nature, it is inherently difficult to understand which aspects of the input data drive the decisions of the network. There are various real-world scenarios in which humans need to make actionable decisions based on the output DNNs. Such decision support systems can be found in critical domains, such as legislation, law enforcement, etc. It is important that the humans making high-level decisions can be sure that the DNN decisions are driven by combinations of data features that are appropriate in the context of the deployment of the decision support system and that the decisions made are legally or ethically defensible. Due to the incredible pace at which DNN technology is being developed, the development of new methods and studies on explaining the decision-making process of DNNs has blossomed into an active research field. A practitioner beginning to study explainable deep learning may be intimidated by the plethora of orthogonal directions the field is taking. This complexity is further exacerbated by the general confusion that exists in defining what it means to be able to explain the actions of a deep learning system and to evaluate a system's "ability to explain". To alleviate this problem, this article offers a "field guide" to deep learning explainability for those uninitiated in the field. The field guide: i) Discusses the traits of a deep learning system that researchers enhance in explainability research, ii) places explainability in the context of other related deep learning research areas, and iii) introduces three simple dimensions defining the space of foundational methods that contribute to explainable deep learning. The guide is designed as an easy-to-digest starting point for those just embarking in the field.
Contextual Grounding of Natural Language Entities in Images
Nov 05, 2019
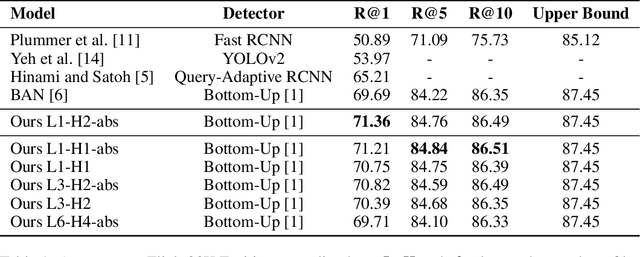

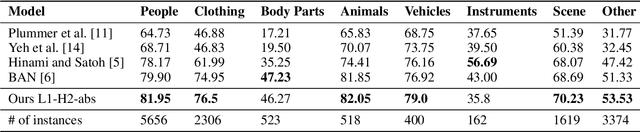
In this paper, we introduce a contextual grounding approach that captures the context in corresponding text entities and image regions to improve the grounding accuracy. Specifically, the proposed architecture accepts pre-trained text token embeddings and image object features from an off-the-shelf object detector as input. Additional encoding to capture the positional and spatial information can be added to enhance the feature quality. There are separate text and image branches facilitating respective architectural refinements for different modalities. The text branch is pre-trained on a large-scale masked language modeling task while the image branch is trained from scratch. Next, the model learns the contextual representations of the text tokens and image objects through layers of high-order interaction respectively. The final grounding head ranks the correspondence between the textual and visual representations through cross-modal interaction. In the evaluation, we show that our model achieves the state-of-the-art grounding accuracy of 71.36% over the Flickr30K Entities dataset. No additional pre-training is necessary to deliver competitive results compared with related work that often requires task-agnostic and task-specific pre-training on cross-modal dadasets. The implementation is publicly available at https://gitlab.com/necla-ml/grounding.
Fuzzy Rough Set Feature Selection to Enhance Phishing Attack Detection
Mar 13, 2019

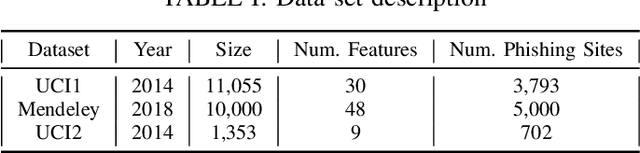

Phishing as one of the most well-known cybercrime activities is a deception of online users to steal their personal or confidential information by impersonating a legitimate website. Several machine learning-based strategies have been proposed to detect phishing websites. These techniques are dependent on the features extracted from the website samples. However, few studies have actually considered efficient feature selection for detecting phishing attacks. In this work, we investigate an agreement on the definitive features which should be used in phishing detection. We apply Fuzzy Rough Set (FRS) theory as a tool to select most effective features from three benchmarked data sets. The selected features are fed into three often used classifiers for phishing detection. To evaluate the FRS feature selection in developing a generalizable phishing detection, the classifiers are trained by a separate out-of-sample data set of 14,000 website samples. The maximum F-measure gained by FRS feature selection is 95% using Random Forest classification. Also, there are 9 universal features selected by FRS over all the three data sets. The F-measure value using this universal feature set is approximately 93% which is a comparable result in contrast to the FRS performance. Since the universal feature set contains no features from third-part services, this finding implies that with no inquiry from external sources, we can gain a faster phishing detection which is also robust toward zero-day attacks.
Visual Entailment: A Novel Task for Fine-Grained Image Understanding
Jan 20, 2019
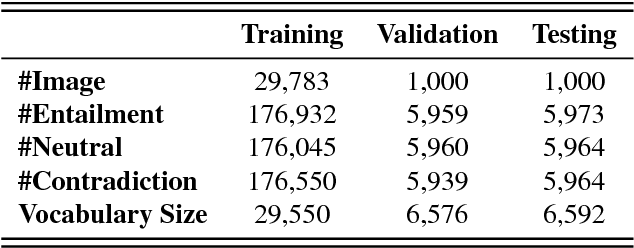

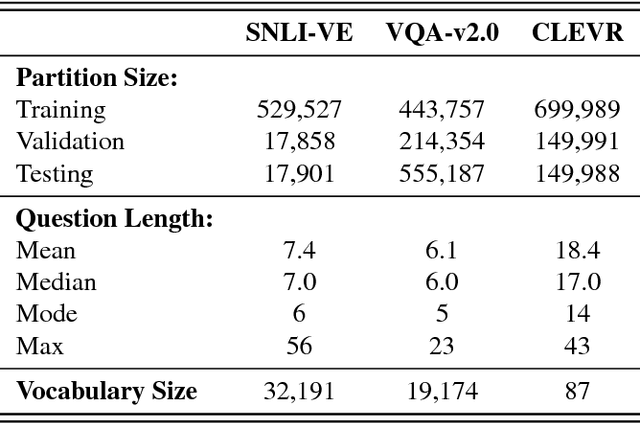
Existing visual reasoning datasets such as Visual Question Answering (VQA), often suffer from biases conditioned on the question, image or answer distributions. The recently proposed CLEVR dataset addresses these limitations and requires fine-grained reasoning but the dataset is synthetic and consists of similar objects and sentence structures across the dataset. In this paper, we introduce a new inference task, Visual Entailment (VE) - consisting of image-sentence pairs whereby a premise is defined by an image, rather than a natural language sentence as in traditional Textual Entailment tasks. The goal of a trained VE model is to predict whether the image semantically entails the text. To realize this task, we build a dataset SNLI-VE based on the Stanford Natural Language Inference corpus and Flickr30k dataset. We evaluate various existing VQA baselines and build a model called Explainable Visual Entailment (EVE) system to address the VE task. EVE achieves up to 71% accuracy and outperforms several other state-of-the-art VQA based models. Finally, we demonstrate the explainability of EVE through cross-modal attention visualizations. The SNLI-VE dataset is publicly available at https://github.com/ necla-ml/SNLI-VE.
HELOC Applicant Risk Performance Evaluation by Topological Hierarchical Decomposition
Nov 26, 2018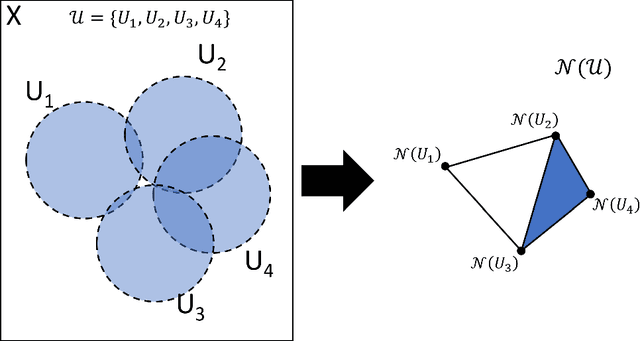

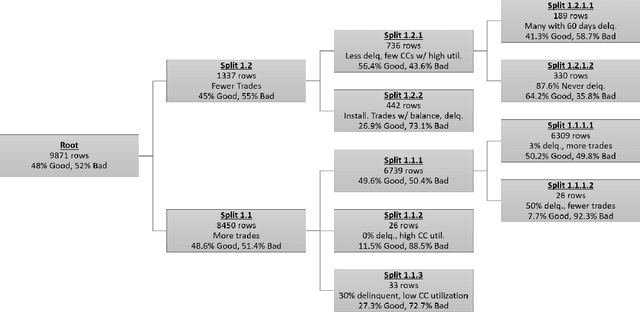

Strong regulations in the financial industry mean that any decisions based on machine learning need to be explained. This precludes the use of powerful supervised techniques such as neural networks. In this study we propose a new unsupervised and semi-supervised technique known as the topological hierarchical decomposition (THD). This process breaks a dataset down into ever smaller groups, where groups are associated with a simplicial complex that approximate the underlying topology of a dataset. We apply THD to the FICO machine learning challenge dataset, consisting of anonymized home equity loan applications using the MAPPER algorithm to build simplicial complexes. We identify different groups of individuals unable to pay back loans, and illustrate how the distribution of feature values in a simplicial complex can be used to explain the decision to grant or deny a loan by extracting illustrative explanations from two THDs on the dataset.
Visual Entailment Task for Visually-Grounded Language Learning
Nov 26, 2018
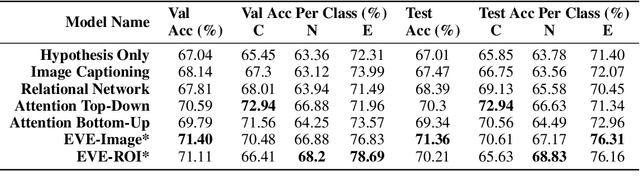
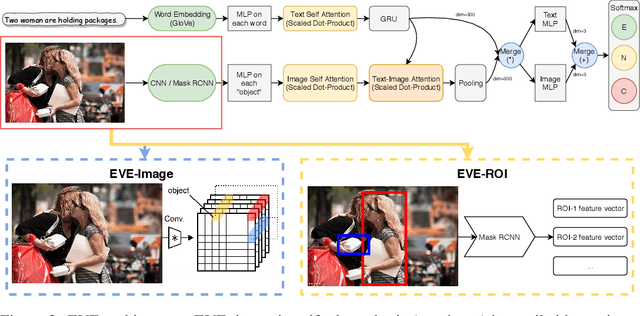
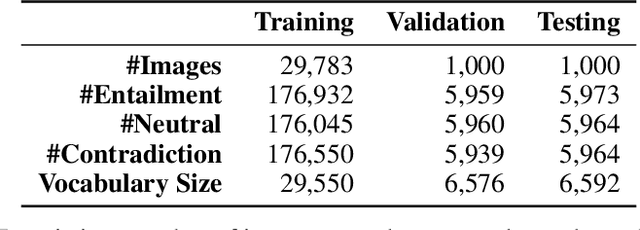
We introduce a new inference task - Visual Entailment (VE) - which differs from traditional Textual Entailment (TE) tasks whereby a premise is defined by an image, rather than a natural language sentence as in TE tasks. A novel dataset SNLI-VE is proposed for VE tasks based on the Stanford Natural Language Inference corpus and Flickr30K. We introduce a differentiable architecture called the Explainable Visual Entailment model (EVE) to tackle the VE problem. EVE and several other state-of-the-art visual question answering (VQA) based models are evaluated on the SNLI-VE dataset, facilitating grounded language understanding and providing insights on how modern VQA based models perform.
Reasoning over RDF Knowledge Bases using Deep Learning
Nov 09, 2018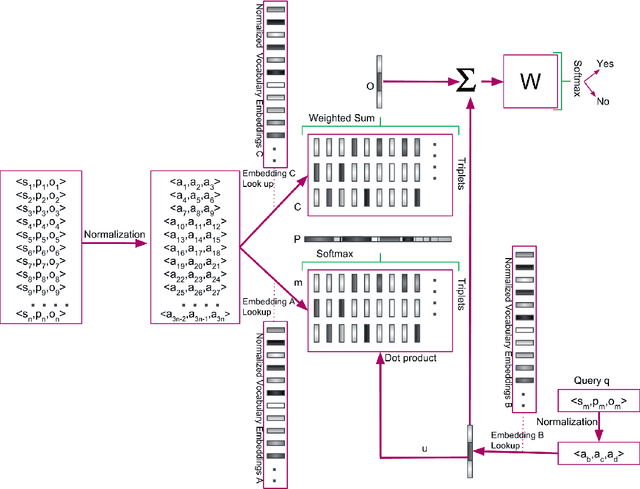


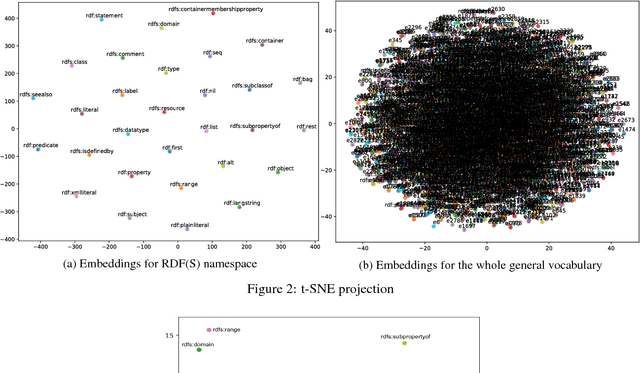
Semantic Web knowledge representation standards, and in particular RDF and OWL, often come endowed with a formal semantics which is considered to be of fundamental importance for the field. Reasoning, i.e., the drawing of logical inferences from knowledge expressed in such standards, is traditionally based on logical deductive methods and algorithms which can be proven to be sound and complete and terminating, i.e. correct in a very strong sense. For various reasons, though, in particular, the scalability issues arising from the ever-increasing amounts of Semantic Web data available and the inability of deductive algorithms to deal with noise in the data, it has been argued that alternative means of reasoning should be investigated which bear high promise for high scalability and better robustness. From this perspective, deductive algorithms can be considered the gold standard regarding correctness against which alternative methods need to be tested. In this paper, we show that it is possible to train a Deep Learning system on RDF knowledge graphs, such that it is able to perform reasoning over new RDF knowledge graphs, with high precision and recall compared to the deductive gold standard.
Deep Neural Ranking for Crowdsourced Geopolitical Event Forecasting
Oct 23, 2018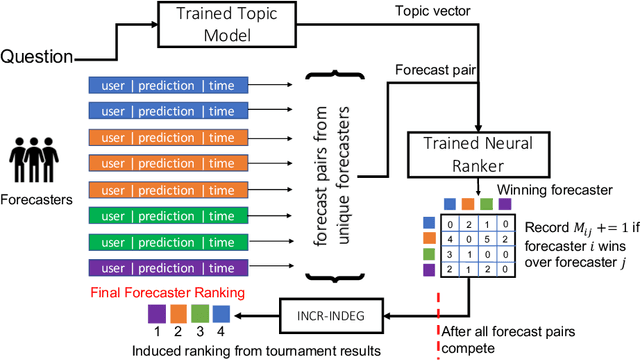
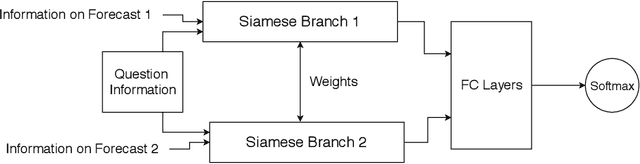
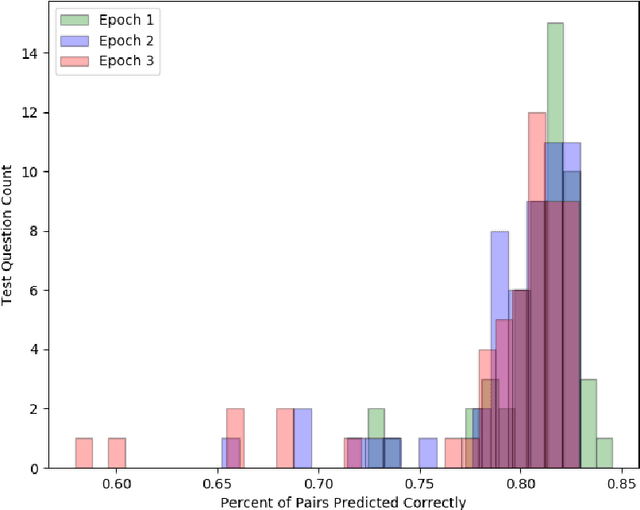

There are many examples of 'wisdom of the crowd' effects in which the large number of participants imparts confidence in the collective judgment of the crowd. But how do we form an aggregated judgment when the size of the crowd is limited? Whose judgments do we include, and whose do we accord the most weight? This paper considers this problem in the context of geopolitical event forecasting, where volunteer analysts are queried to give their expertise, confidence, and predictions about the outcome of an event. We develop a forecast aggregation model that integrates topical information about a question, meta-data about a pair of forecasters, and their predictions in a deep siamese neural network that decides which forecasters' predictions are more likely to be close to the correct response. A ranking of the forecasters is induced from a tournament of pair-wise forecaster comparisons, with the ranking used to create an aggregate forecast. Preliminary results find the aggregate prediction of the best forecasters ranked by our deep siamese network model consistently beats typical aggregation techniques by Brier score.
Realistic Traffic Generation for Web Robots
Dec 15, 2017
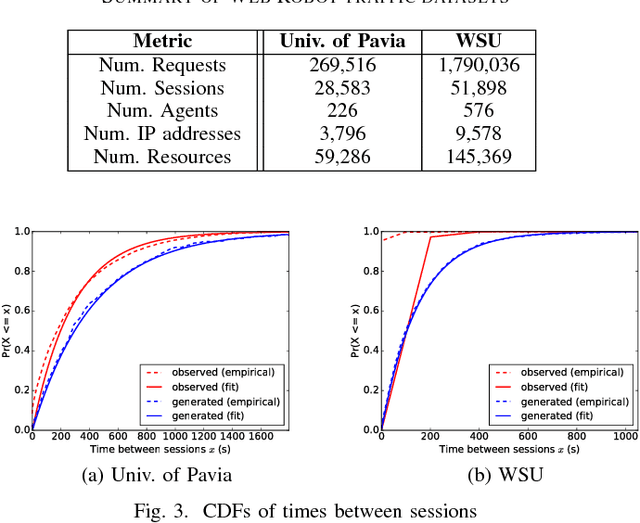
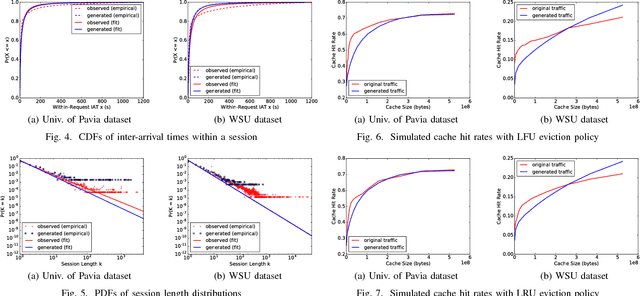
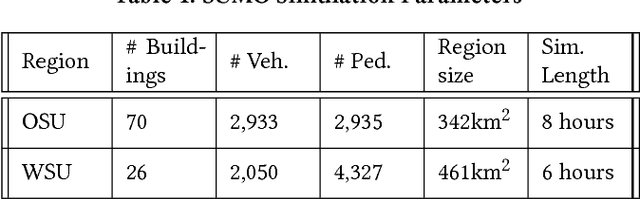
Critical to evaluating the capacity, scalability, and availability of web systems are realistic web traffic generators. Web traffic generation is a classic research problem, no generator accounts for the characteristics of web robots or crawlers that are now the dominant source of traffic to a web server. Administrators are thus unable to test, stress, and evaluate how their systems perform in the face of ever increasing levels of web robot traffic. To resolve this problem, this paper introduces a novel approach to generate synthetic web robot traffic with high fidelity. It generates traffic that accounts for both the temporal and behavioral qualities of robot traffic by statistical and Bayesian models that are fitted to the properties of robot traffic seen in web logs from North America and Europe. We evaluate our traffic generator by comparing the characteristics of generated traffic to those of the original data. We look at session arrival rates, inter-arrival times and session lengths, comparing and contrasting them between generated and real traffic. Finally, we show that our generated traffic affects cache performance similarly to actual traffic, using the common LRU and LFU eviction policies.
Intrinsic Point of Interest Discovery from Trajectory Data
Dec 14, 2017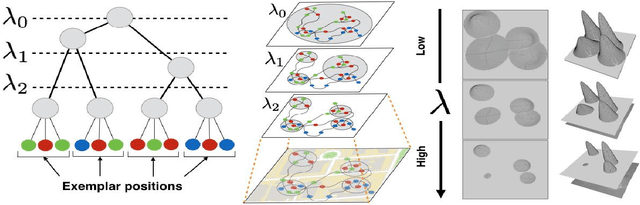
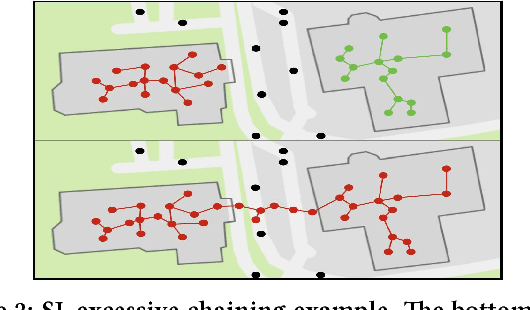
This paper presents a framework for intrinsic point of interest discovery from trajectory databases. Intrinsic points of interest are regions of a geospatial area innately defined by the spatial and temporal aspects of trajectory data, and can be of varying size, shape, and resolution. Any trajectory database exhibits such points of interest, and hence are intrinsic, as compared to most other point of interest definitions which are said to be extrinsic, as they require trajectory metadata, external knowledge about the region the trajectories are observed, or other application-specific information. Spatial and temporal aspects are qualities of any trajectory database, making the framework applicable to data from any domain and of any resolution. The framework is developed under recent developments on the consistency of nonparametric hierarchical density estimators and enables the possibility of formal statistical inference and evaluation over such intrinsic points of interest. Comparisons of the POIs uncovered by the framework in synthetic truth data to thousands of parameter settings for common POI discovery methods show a marked improvement in fidelity without the need to tune any parameters by hand.