 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Grounding of Natural Language Entities in Images
Paper and Code

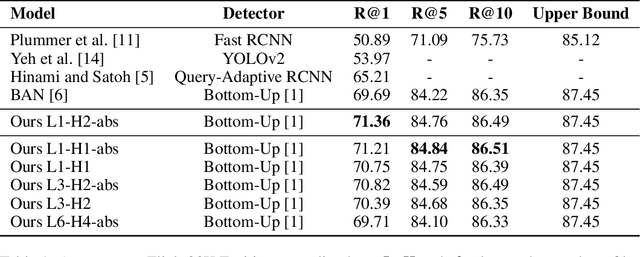

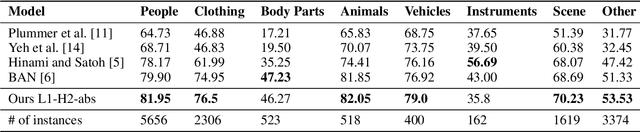
In this paper, we introduce a contextual grounding approach that captures the context in corresponding text entities and image regions to improve the grounding accuracy. Specifically, the proposed architecture accepts pre-trained text token embeddings and image object features from an off-the-shelf object detector as input. Additional encoding to capture the positional and spatial information can be added to enhance the feature quality. There are separate text and image branches facilitating respective architectural refinements for different modalities. The text branch is pre-trained on a large-scale masked language modeling task while the image branch is trained from scratch. Next, the model learns the contextual representations of the text tokens and image objects through layers of high-order interaction respectively. The final grounding head ranks the correspondence between the textual and visual representations through cross-modal interaction. In the evaluation, we show that our model achieves the state-of-the-art grounding accuracy of 71.36% over the Flickr30K Entities dataset. No additional pre-training is necessary to deliver competitive results compared with related work that often requires task-agnostic and task-specific pre-training on cross-modal dadasets. The implementation is publicly available at https://gitlab.com/necla-ml/grounding.