 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Higher-order Object Interactions for Keypoint-based Video Understanding
May 16, 2023
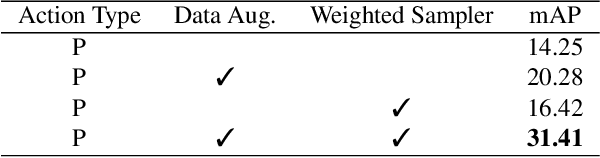
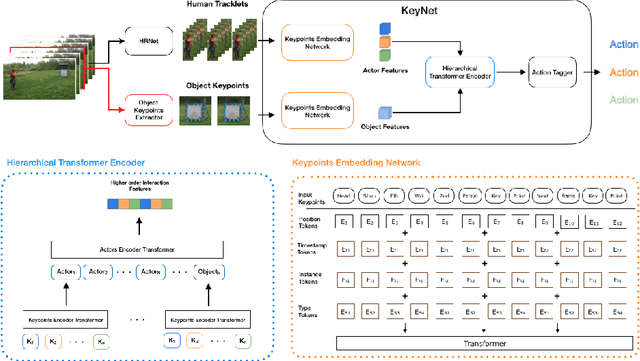

Action recognition is an important problem that requires identifying actions in video by learning complex interactions across scene actors and objects. However, modern deep-learning based networks often require significant computation, and may capture scene context using various modalities that further increases compute costs. Efficient methods such as those used for AR/VR often only use human-keypoint information but suffer from a loss of scene context that hurts accuracy. In this paper, we describe an action-localization method, KeyNet, that uses only the keypoint data for tracking and action recognition. Specifically, KeyNet introduces the use of object based keypoint information to capture context in the scene. Our method illustrates how to build a structured intermediate representation that allows modeling higher-order interactions in the scene from object and human keypoints without using any RGB information. We find that KeyNet is able to track and classify human actions at just 5 FPS. More importantly, we demonstrate that object keypoints can be modeled to recover any loss in context from using keypoint information over AVA action and Kinetics datasets.
Self-supervised Video Representation Learning with Cascade Positive Retrieval
Jan 21, 2022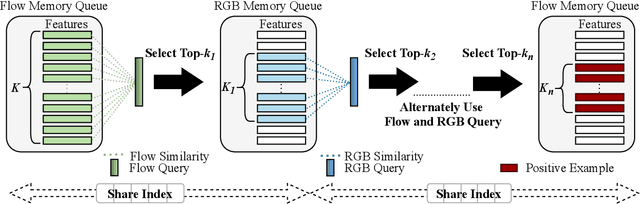
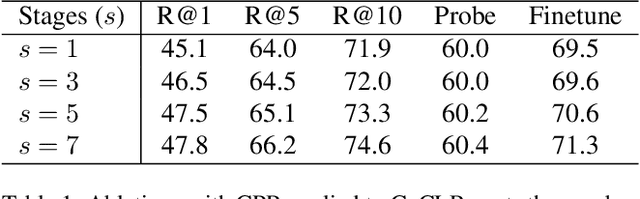

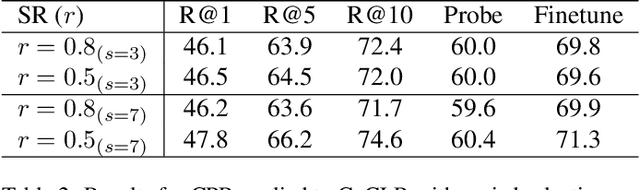
Self-supervised video representation learning has been shown to effectively improve downstream tasks such as video retrieval and action recognition. In this paper, we present the Cascade Positive Retrieval (CPR) that successively mines positive examples w.r.t. the query for contrastive learning in a cascade of stages. Specifically, CPR exploits multiple views of a query example in different modalities, where an alternative view may help find another positive example dissimilar in the query view. We explore the effects of possible CPR configurations in ablations including the number of mining stages, the top similar example selection ratio in each stage, and progressive training with an incremental number of the final Top-k selection. The overall mining quality is measured to reflect the recall across training set classes. CPR reaches a median class mining recall of 83.3%, outperforming previous work by 5.5%. Implementation-wise, CPR is complementary to pretext tasks and can be easily applied to previous work. In the evaluation of pretraining on UCF101, CPR consistently improves existing work and even achieves state-of-the-art R@1 of 56.7% and 24.4% in video retrieval as well as 83.8% and 54.8% in action recognition on UCF101 and HMDB51. For transfer from large video dataset Kinetics400 to UCF101 and HDMB, CPR benefits existing work, showing competitive Top-1 accuracies of 85.1% and 57.4% despite pretraining at a lower resolution and frame sampling rate. The code will be released soon for reproducing the results. The code is available at https://github.com/necla-ml/CPR.
SplitBrain: Hybrid Data and Model Parallel Deep Learning
Dec 31, 2021
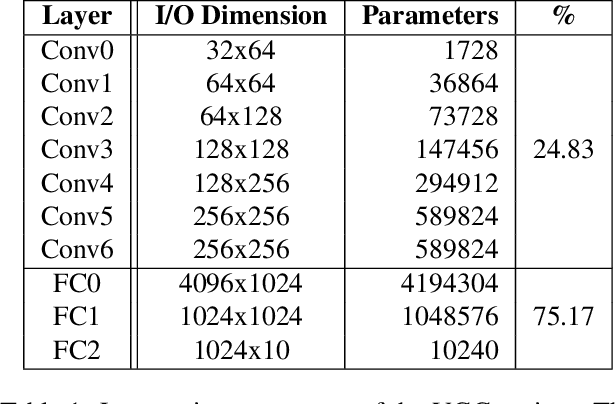
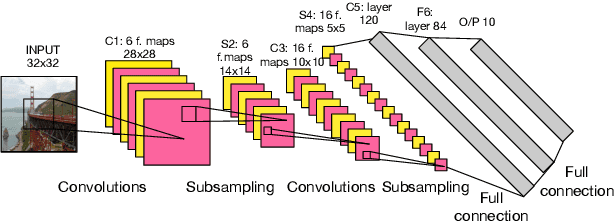
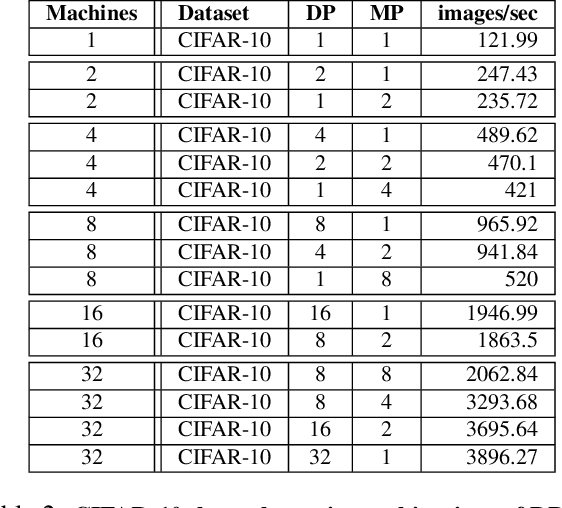
The recent success of deep learning applications has coincided with those widely available powerful computational resources for training sophisticated machine learning models with huge datasets. Nonetheless, training large models such as convolutional neural networks using model parallelism (as opposed to data parallelism) is challenging because the complex nature of communication between model shards makes it difficult to partition the computation efficiently across multiple machines with an acceptable trade-off. This paper presents SplitBrain, a high performance distributed deep learning framework supporting hybrid data and model parallelism. Specifically, SplitBrain provides layer-specific partitioning that co-locates compute intensive convolutional layers while sharding memory demanding layers. A novel scalable group communication is proposed to further improve the training throughput with reduced communication overhead. The results show that SplitBrain can achieve nearly linear speedup while saving up to 67\% of memory consumption for data and model parallel VGG over CIFAR-10.
COMPOSER: Compositional Learning of Group Activity in Videos
Dec 11, 2021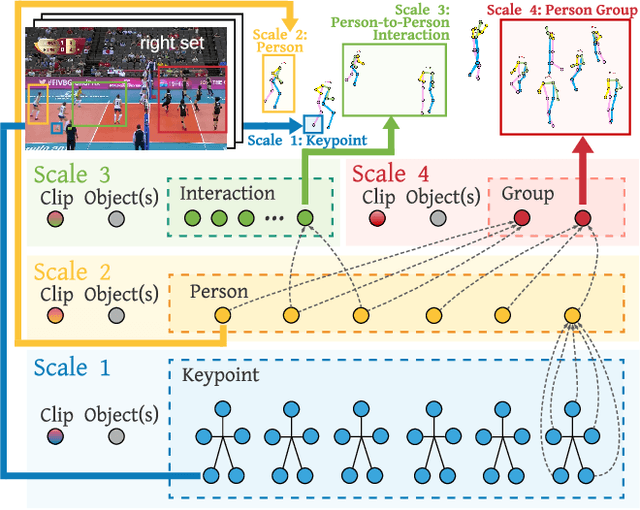
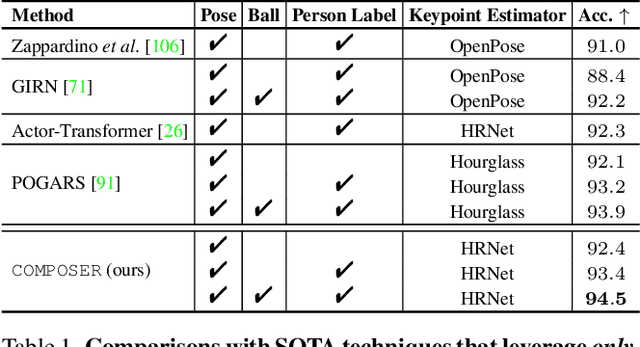
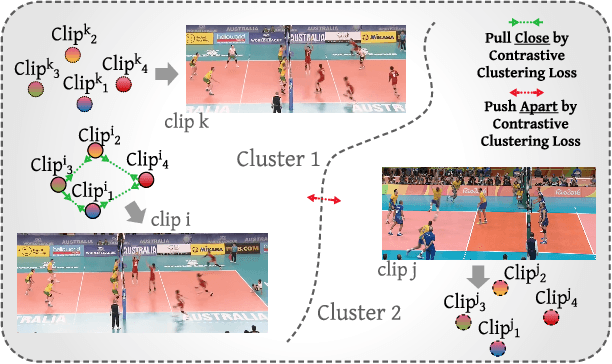
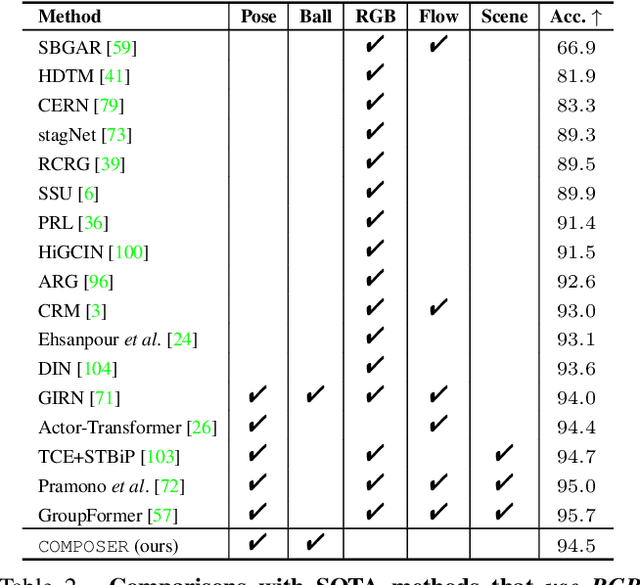
Group Activity Recognition (GAR) detects the activity performed by a group of actors in a short video clip. The task requires the compositional understanding of scene entities and relational reasoning between them. We approach GAR by modeling the video as a series of tokens that represent the multi-scale semantic concepts in the video. We propose COMPOSER, a Multiscale Transformer based architecture that performs attention-based reasoning over tokens at each scale and learns group activity compositionally. In addition, we only use the keypoint modality which reduces scene biases and improves the generalization ability of the model. We improve the multi-scale representations in COMPOSER by clustering the intermediate scale representations, while maintaining consistent cluster assignments between scales. Finally, we use techniques such as auxiliary prediction and novel data augmentations (e.g., Actor Dropout) to aid model training. We demonstrate the model's strength and interpretability on the challenging Volleyball dataset. COMPOSER achieves a new state-of-the-art 94.5% accuracy with the keypoint-only modality. COMPOSER outperforms the latest GAR methods that rely on RGB signals, and performs favorably compared against methods that exploit multiple modalities. Our code will be available.
Hopper: Multi-hop Transformer for Spatiotemporal Reasoning
Mar 22, 2021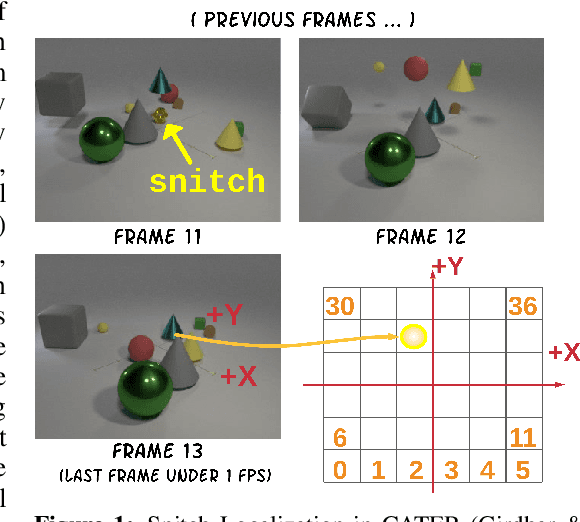
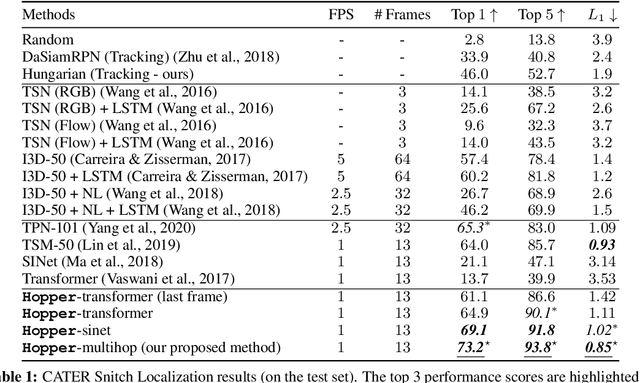
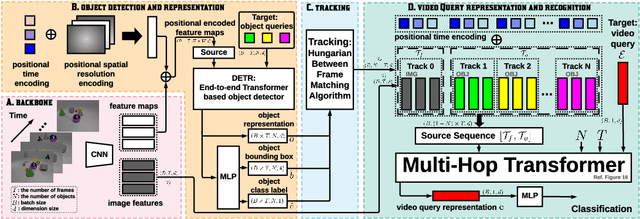
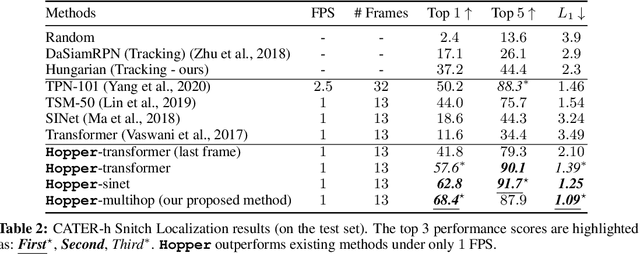
This paper considers the problem of spatiotemporal object-centric reasoning in videos. Central to our approach is the notion of object permanence, i.e., the ability to reason about the location of objects as they move through the video while being occluded, contained or carried by other objects. Existing deep learning based approaches often suffer from spatiotemporal biases when applied to video reasoning problems. We propose Hopper, which uses a Multi-hop Transformer for reasoning object permanence in videos. Given a video and a localization query, Hopper reasons over image and object tracks to automatically hop over critical frames in an iterative fashion to predict the final position of the object of interest. We demonstrate the effectiveness of using a contrastive loss to reduce spatiotemporal biases. We evaluate over CATER dataset and find that Hopper achieves 73.2% Top-1 accuracy using just 1 FPS by hopping through just a few critical frames. We also demonstrate Hopper can perform long-term reasoning by building a CATER-h dataset that requires multi-step reasoning to localize objects of interest correctly.
15 Keypoints Is All You Need
Dec 05, 2019
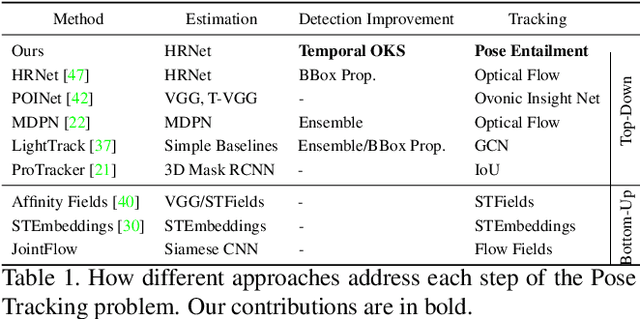

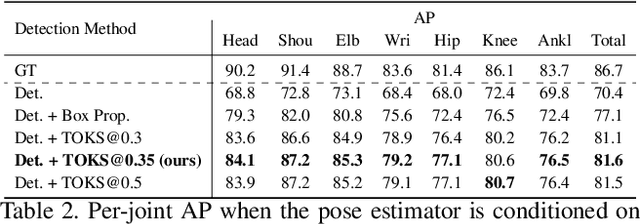
Pose tracking is an important problem that requires identifying unique human pose-instances and matching them temporally across different frames of a video. However, existing pose tracking methods are unable to accurately model temporal relationships and require significant computation, often computing the tracks offline. We present an efficient Multi-person Pose Tracking method, KeyTrack, that only relies on keypoint information without using any RGB or optical flow information to track human keypoints in real-time. Keypoints are tracked using our Pose Entailment method, in which, first, a pair of pose estimates is sampled from different frames in a video and tokenized. Then, a Transformer-based network makes a binary classification as to whether one pose temporally follows another. Furthermore, we improve our top-down pose estimation method with a novel, parameter-free, keypoint refinement technique that improves the keypoint estimates used during the Pose Entailment step. We achieve state-of-the-art results on the PoseTrack'17 and the PoseTrack'18 benchmarks while using only a fraction of the computation required by most other methods for computing the tracking information.
Contextual Grounding of Natural Language Entities in Images
Nov 05, 2019
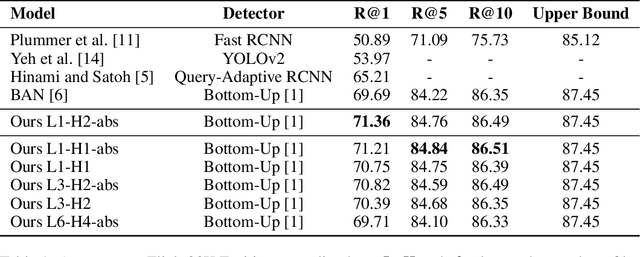

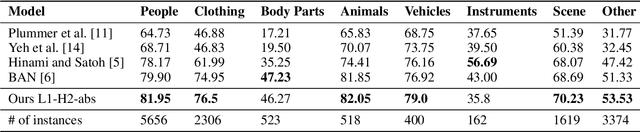
In this paper, we introduce a contextual grounding approach that captures the context in corresponding text entities and image regions to improve the grounding accuracy. Specifically, the proposed architecture accepts pre-trained text token embeddings and image object features from an off-the-shelf object detector as input. Additional encoding to capture the positional and spatial information can be added to enhance the feature quality. There are separate text and image branches facilitating respective architectural refinements for different modalities. The text branch is pre-trained on a large-scale masked language modeling task while the image branch is trained from scratch. Next, the model learns the contextual representations of the text tokens and image objects through layers of high-order interaction respectively. The final grounding head ranks the correspondence between the textual and visual representations through cross-modal interaction. In the evaluation, we show that our model achieves the state-of-the-art grounding accuracy of 71.36% over the Flickr30K Entities dataset. No additional pre-training is necessary to deliver competitive results compared with related work that often requires task-agnostic and task-specific pre-training on cross-modal dadasets. The implementation is publicly available at https://gitlab.com/necla-ml/grounding.
Visual Entailment: A Novel Task for Fine-Grained Image Understanding
Jan 20, 2019
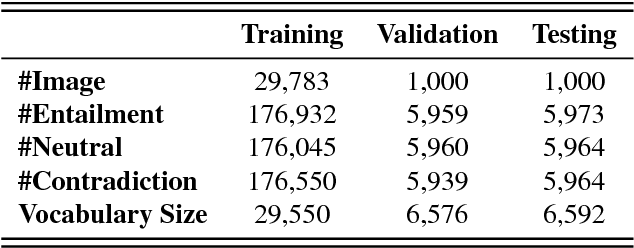

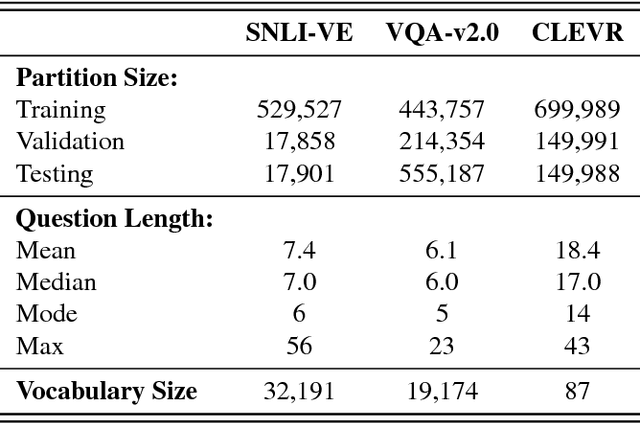
Existing visual reasoning datasets such as Visual Question Answering (VQA), often suffer from biases conditioned on the question, image or answer distributions. The recently proposed CLEVR dataset addresses these limitations and requires fine-grained reasoning but the dataset is synthetic and consists of similar objects and sentence structures across the dataset. In this paper, we introduce a new inference task, Visual Entailment (VE) - consisting of image-sentence pairs whereby a premise is defined by an image, rather than a natural language sentence as in traditional Textual Entailment tasks. The goal of a trained VE model is to predict whether the image semantically entails the text. To realize this task, we build a dataset SNLI-VE based on the Stanford Natural Language Inference corpus and Flickr30k dataset. We evaluate various existing VQA baselines and build a model called Explainable Visual Entailment (EVE) system to address the VE task. EVE achieves up to 71% accuracy and outperforms several other state-of-the-art VQA based models. Finally, we demonstrate the explainability of EVE through cross-modal attention visualizations. The SNLI-VE dataset is publicly available at https://github.com/ necla-ml/SNLI-VE.
Visual Entailment Task for Visually-Grounded Language Learning
Nov 26, 2018
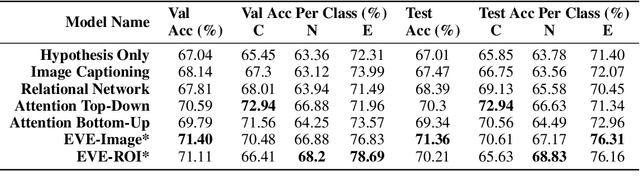
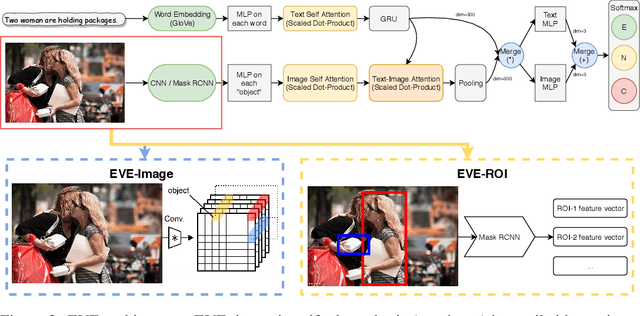
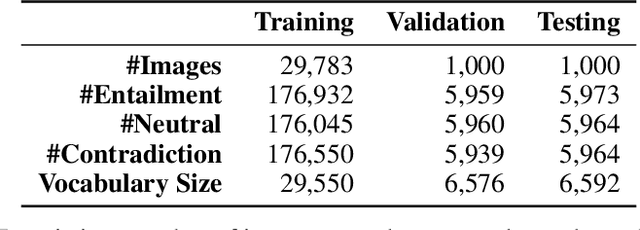
We introduce a new inference task - Visual Entailment (VE) - which differs from traditional Textual Entailment (TE) tasks whereby a premise is defined by an image, rather than a natural language sentence as in TE tasks. A novel dataset SNLI-VE is proposed for VE tasks based on the Stanford Natural Language Inference corpus and Flickr30K. We introduce a differentiable architecture called the Explainable Visual Entailment model (EVE) to tackle the VE problem. EVE and several other state-of-the-art visual question answering (VQA) based models are evaluated on the SNLI-VE dataset, facilitating grounded language understanding and providing insights on how modern VQA based models perform.