Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Entailment Task for Visually-Grounded Language Learning
Paper and Code

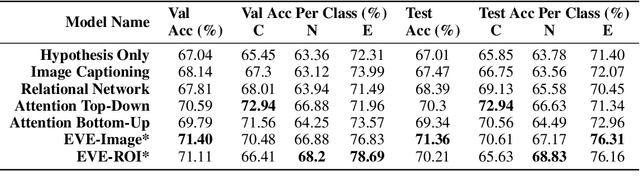
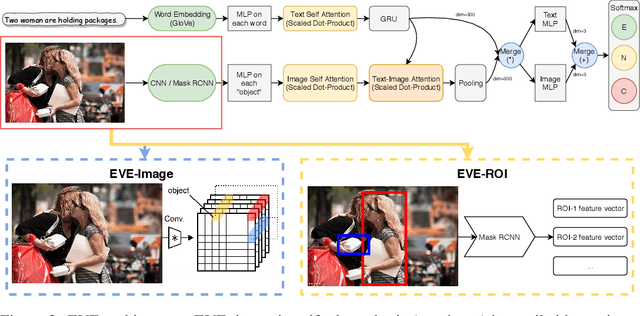
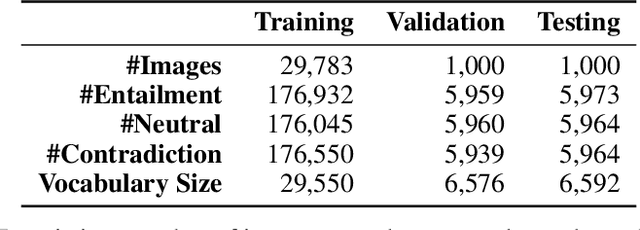
We introduce a new inference task - Visual Entailment (VE) - which differs from traditional Textual Entailment (TE) tasks whereby a premise is defined by an image, rather than a natural language sentence as in TE tasks. A novel dataset SNLI-VE is proposed for VE tasks based on the Stanford Natural Language Inference corpus and Flickr30K. We introduce a differentiable architecture called the Explainable Visual Entailment model (EVE) to tackle the VE problem. EVE and several other state-of-the-art visual question answering (VQA) based models are evaluated on the SNLI-VE dataset, facilitating grounded language understanding and providing insights on how modern VQA based models perform.
* 4 pages, accepted by NIPS 2018 Visually Grounded Interaction and
Language (ViGIL) workshop
View paper on