 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitBrain: Hybrid Data and Model Parallel Deep Learning
Paper and Code
Dec 31, 2021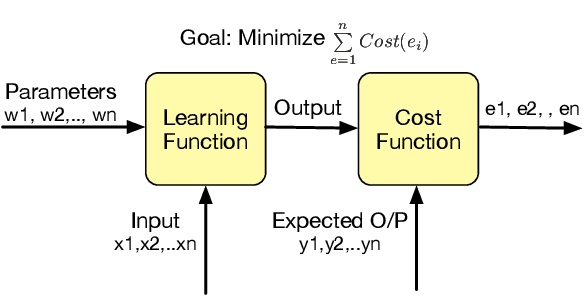
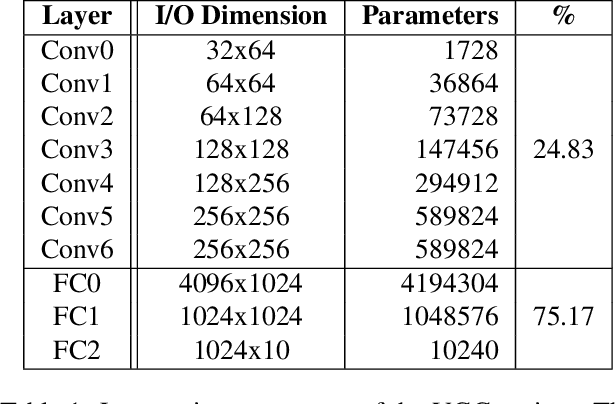
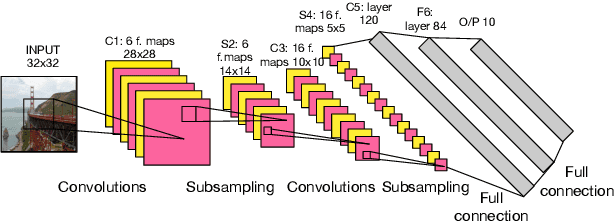
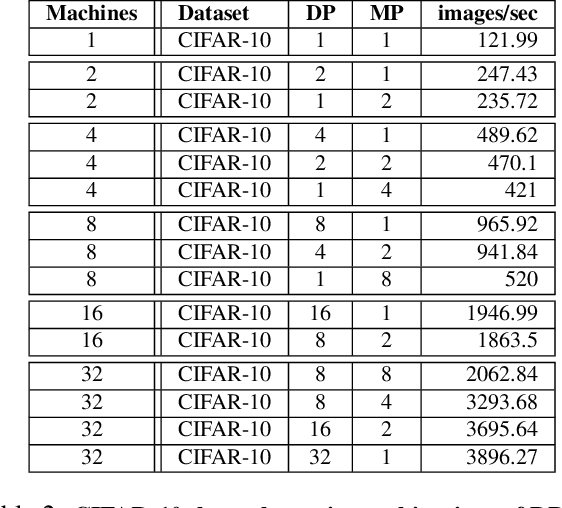
The recent success of deep learning applications has coincided with those widely available powerful computational resources for training sophisticated machine learning models with huge datasets. Nonetheless, training large models such as convolutional neural networks using model parallelism (as opposed to data parallelism) is challenging because the complex nature of communication between model shards makes it difficult to partition the computation efficiently across multiple machines with an acceptable trade-off. This paper presents SplitBrain, a high performance distributed deep learning framework supporting hybrid data and model parallelism. Specifically, SplitBrain provides layer-specific partitioning that co-locates compute intensive convolutional layers while sharding memory demanding layers. A novel scalable group communication is proposed to further improve the training throughput with reduced communication overhead. The results show that SplitBrain can achieve nearly linear speedup while saving up to 67\% of memory consumption for data and model parallel VGG over CIFAR-10.