 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Few-shot Debugging for NLU Test Suites
Apr 13, 2022
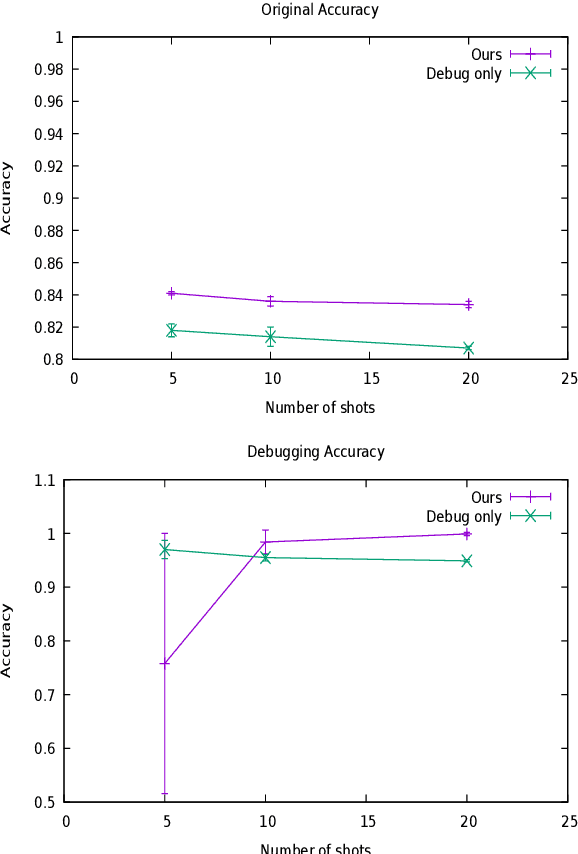
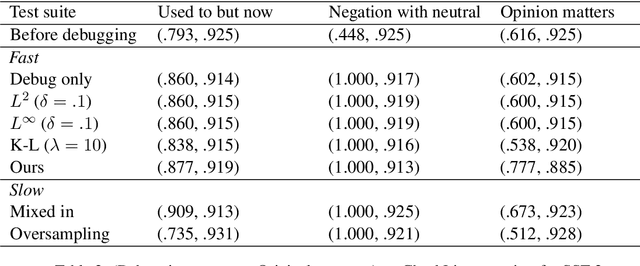
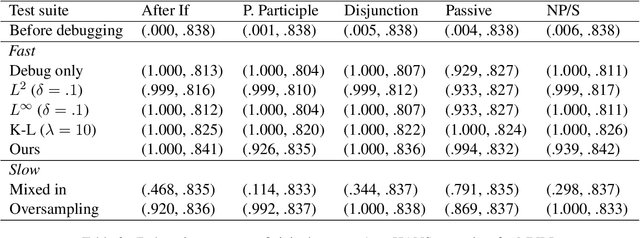
We study few-shot debugging of transformer based natural language understanding models, using recently popularized test suites to not just diagnose but correct a problem. Given a few debugging examples of a certain phenomenon, and a held-out test set of the same phenomenon, we aim to maximize accuracy on the phenomenon at a minimal cost of accuracy on the original test set. We examine several methods that are faster than full epoch retraining. We introduce a new fast method, which samples a few in-danger examples from the original training set. Compared to fast methods using parameter distance constraints or Kullback-Leibler divergence, we achieve superior original accuracy for comparable debugging accuracy.
SplitBrain: Hybrid Data and Model Parallel Deep Learning
Dec 31, 2021
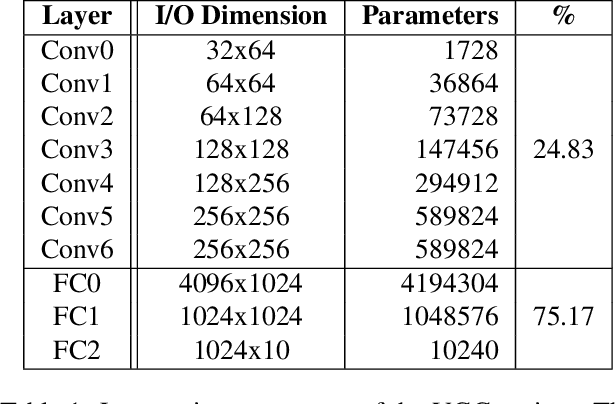
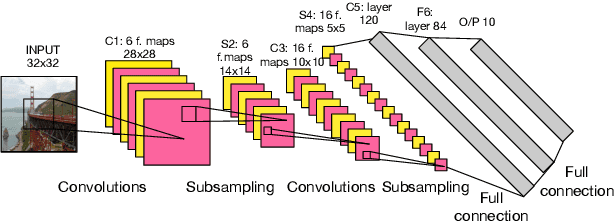
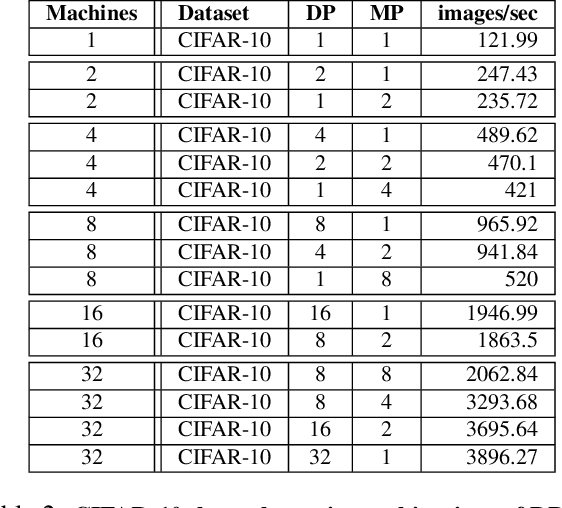
The recent success of deep learning applications has coincided with those widely available powerful computational resources for training sophisticated machine learning models with huge datasets. Nonetheless, training large models such as convolutional neural networks using model parallelism (as opposed to data parallelism) is challenging because the complex nature of communication between model shards makes it difficult to partition the computation efficiently across multiple machines with an acceptable trade-off. This paper presents SplitBrain, a high performance distributed deep learning framework supporting hybrid data and model parallelism. Specifically, SplitBrain provides layer-specific partitioning that co-locates compute intensive convolutional layers while sharding memory demanding layers. A novel scalable group communication is proposed to further improve the training throughput with reduced communication overhead. The results show that SplitBrain can achieve nearly linear speedup while saving up to 67\% of memory consumption for data and model parallel VGG over CIFAR-10.
Improving Neural Network Robustness through Neighborhood Preserving Layers
Jan 29, 2021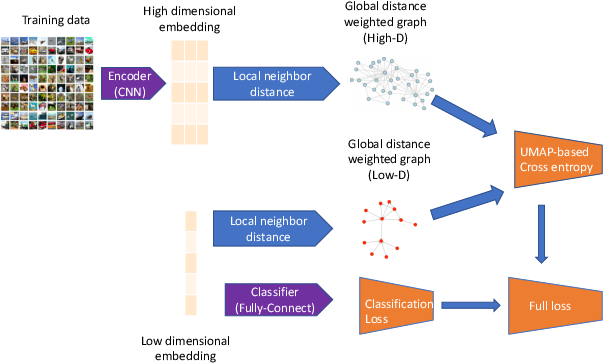
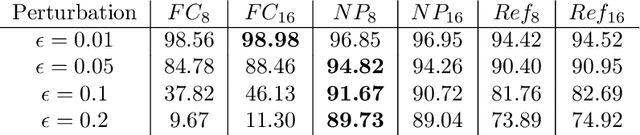
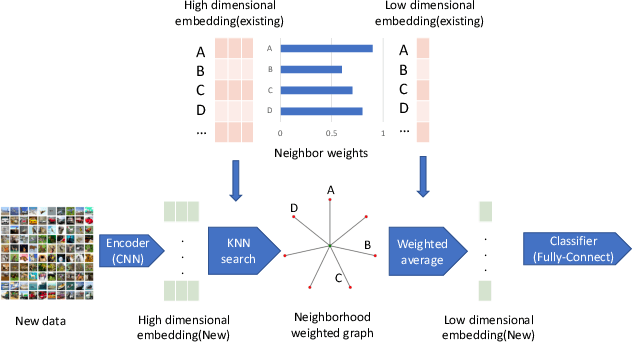
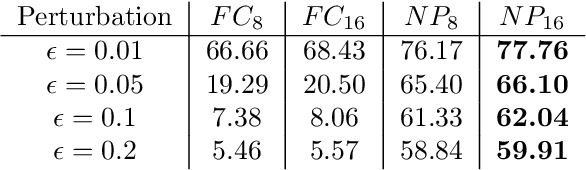
Robustness against adversarial attack in neural networks is an important research topic in the machine learning community. We observe one major source of vulnerability of neural nets is from overparameterized fully-connected layers. In this paper, we propose a new neighborhood preserving layer which can replace these fully connected layers to improve the network robustness. We demonstrate a novel neural network architecture which can incorporate such layers and also can be trained efficiently. We theoretically prove that our models are more robust against distortion because they effectively control the magnitude of gradients. Finally, we empirically show that our designed network architecture is more robust against state-of-art gradient descent based attacks, such as a PGD attack on the benchmark datasets MNIST and CIFAR10.
Optimal Transport Classifier: Defending Against Adversarial Attacks by Regularized Deep Embedding
Dec 09, 2018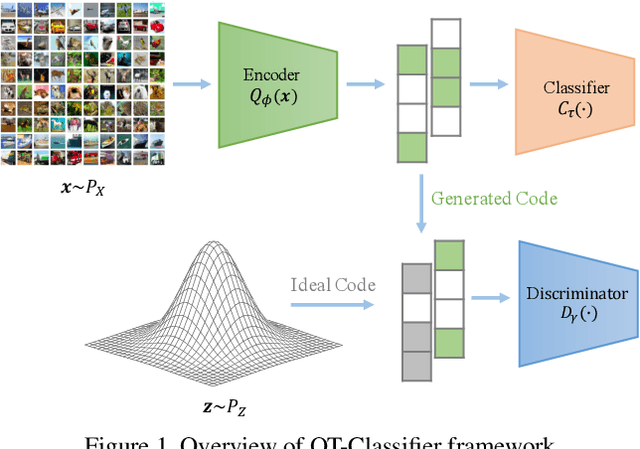
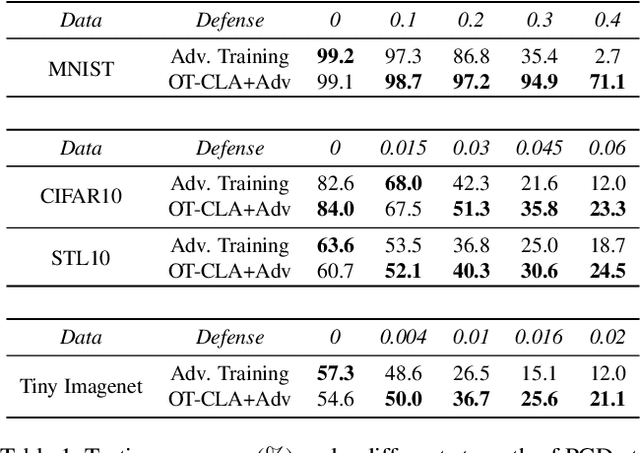
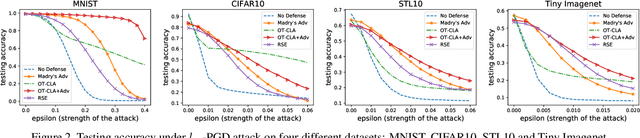

Recent studies have demonstrated the vulnerability of deep convolutional neural networks against adversarial examples. Inspired by the observation that the intrinsic dimension of image data is much smaller than its pixel space dimension and the vulnerability of neural networks grows with the input dimension, we propose to embed high-dimensional input images into a low-dimensional space to perform classification. However, arbitrarily projecting the input images to a low-dimensional space without regularization will not improve the robustness of deep neural networks. Leveraging optimal transport theory, we propose a new framework, Optimal Transport Classifier (OT-Classifier), and derive an objective that minimizes the discrepancy between the distribution of the true label and the distribution of the OT-Classifier output. Experimental results on several benchmark datasets show that, our proposed framework achieves state-of-the-art performance against strong adversarial attack methods.
ASAP: Asynchronous Approximate Data-Parallel Computation
Dec 27, 2016
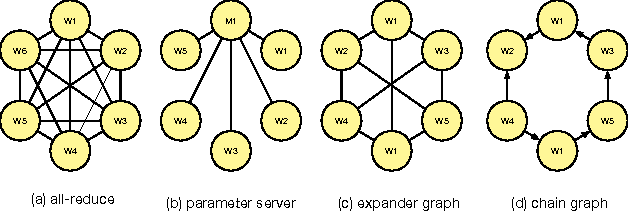
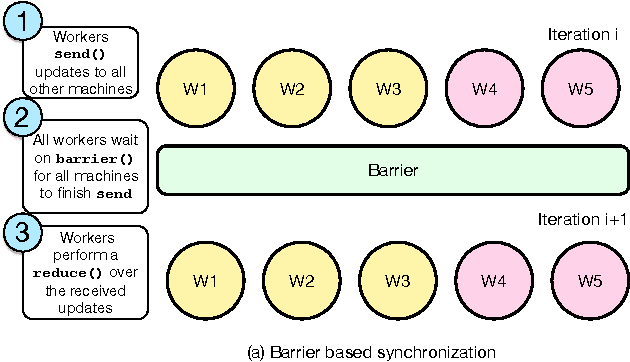
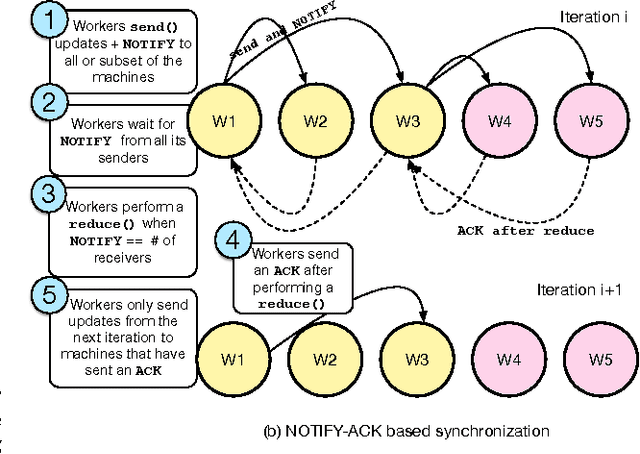
Emerging workloads, such as graph processing and machine learning are approximate because of the scale of data involved and the stochastic nature of the underlying algorithms. These algorithms are often distributed over multiple machines using bulk-synchronous processing (BSP) or other synchronous processing paradigms such as map-reduce. However, data parallel processing primitives such as repeated barrier and reduce operations introduce high synchronization overheads. Hence, many existing data-processing platforms use asynchrony and staleness to improve data-parallel job performance. Often, these systems simply change the synchronous communication to asynchronous between the worker nodes in the cluster. This improves the throughput of data processing but results in poor accuracy of the final output since different workers may progress at different speeds and process inconsistent intermediate outputs. In this paper, we present ASAP, a model that provides asynchronous and approximate processing semantics for data-parallel computation. ASAP provides fine-grained worker synchronization using NOTIFY-ACK semantics that allows independent workers to run asynchronously. ASAP also provides stochastic reduce that provides approximate but guaranteed convergence to the same result as an aggregated all-reduce. In our results, we show that ASAP can reduce synchronization costs and provides 2-10X speedups in convergence and up to 10X savings in network costs for distributed machine learning applications and provides strong convergence guarantees.