 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscussLLM: Teaching Large Language Models When to Speak
Aug 25, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in understanding and generating human-like text, yet they largely operate as reactive agents, responding only when directly prompted. This passivity creates an "awareness gap," limiting their potential as truly collaborative partners in dynamic human discussions. We introduce $\textit{DiscussLLM}$, a framework designed to bridge this gap by training models to proactively decide not just $\textit{what}$ to say, but critically, $\textit{when}$ to speak. Our primary contribution is a scalable two-stage data generation pipeline that synthesizes a large-scale dataset of realistic multi-turn human discussions. Each discussion is annotated with one of five intervention types (e.g., Factual Correction, Concept Definition) and contains an explicit conversational trigger where an AI intervention adds value. By training models to predict a special silent token when no intervention is needed, they learn to remain quiet until a helpful contribution can be made. We explore two architectural baselines: an integrated end-to-end model and a decoupled classifier-generator system optimized for low-latency inference. We evaluate these models on their ability to accurately time interventions and generate helpful responses, paving the way for more situationally aware and proactive conversational AI.
Reducing Hallucinations of Medical Multimodal Large Language Models with Visual Retrieval-Augmented Generation
Feb 20, 2025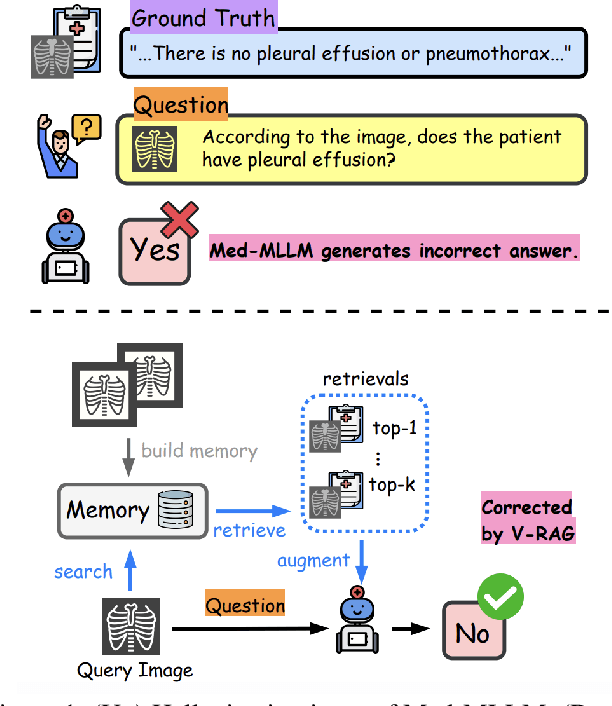
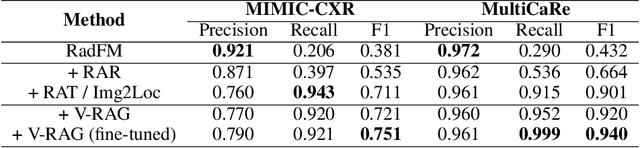
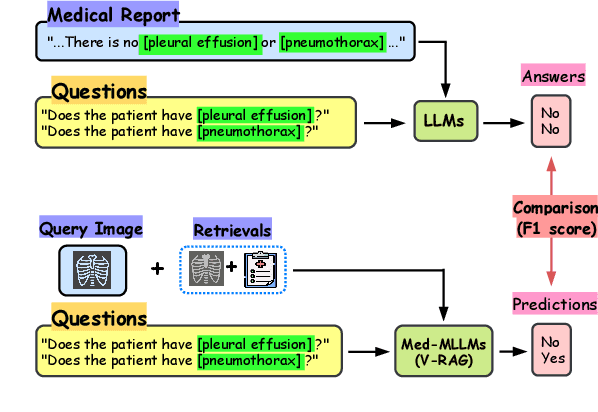
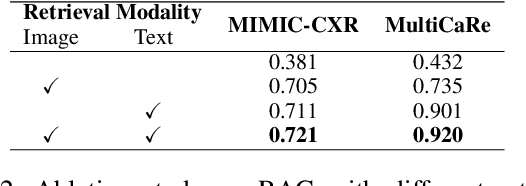
Multimodal Large Language Models (MLLMs) have shown impressive performance in vision and text tasks. However, hallucination remains a major challenge, especially in fields like healthcare where details are critical. In this work, we show how MLLMs may be enhanced to support Visual RAG (V-RAG), a retrieval-augmented generation framework that incorporates both text and visual data from retrieved images. On the MIMIC-CXR chest X-ray report generation and Multicare medical image caption generation datasets, we show that Visual RAG improves the accuracy of entity probing, which asks whether a medical entities is grounded by an image. We show that the improvements extend both to frequent and rare entities, the latter of which may have less positive training data. Downstream, we apply V-RAG with entity probing to correct hallucinations and generate more clinically accurate X-ray reports, obtaining a higher RadGraph-F1 score.
Multi-hop Evidence Pursuit Meets the Web: Team Papelo at FEVER 2024
Nov 08, 2024Separating disinformation from fact on the web has long challenged both the search and the reasoning powers of humans. We show that the reasoning power of large language models (LLMs) and the retrieval power of modern search engines can be combined to automate this process and explainably verify claims. We integrate LLMs and search under a multi-hop evidence pursuit strategy. This strategy generates an initial question based on an input claim using a sequence to sequence model, searches and formulates an answer to the question, and iteratively generates follow-up questions to pursue the evidence that is missing using an LLM. We demonstrate our system on the FEVER 2024 (AVeriTeC) shared task. Compared to a strategy of generating all the questions at once, our method obtains .045 higher label accuracy and .155 higher AVeriTeC score (evaluating the adequacy of the evidence). Through ablations, we show the importance of various design choices, such as the question generation method, medium-sized context, reasoning with one document at a time, adding metadata, paraphrasing, reducing the problem to two classes, and reconsidering the final verdict. Our submitted system achieves .510 AVeriTeC score on the dev set and .477 AVeriTeC score on the test set.
Exploring the Role of Reasoning Structures for Constructing Proofs in Multi-Step Natural Language Reasoning with Large Language Models
Oct 11, 2024



When performing complex multi-step reasoning tasks, the ability of Large Language Models (LLMs) to derive structured intermediate proof steps is important for ensuring that the models truly perform the desired reasoning and for improving models' explainability. This paper is centred around a focused study: whether the current state-of-the-art generalist LLMs can leverage the structures in a few examples to better construct the proof structures with \textit{in-context learning}. Our study specifically focuses on structure-aware demonstration and structure-aware pruning. We demonstrate that they both help improve performance. A detailed analysis is provided to help understand the results.
Self-Consistent Decoding for More Factual Open Responses
Mar 01, 2024Self-consistency has emerged as a powerful method for improving the accuracy of short answers generated by large language models. As previously defined, it only concerns the accuracy of a final answer parsed from generated text. In this work, we extend the idea to open response generation, by integrating voting into the decoding method. Each output sentence is selected from among multiple samples, conditioning on the previous selections, based on a simple token overlap score. We compare this "Sample & Select" method to greedy decoding, beam search, nucleus sampling, and the recently introduced hallucination avoiding decoders of DoLA, P-CRR, and S-CRR. We show that Sample & Select improves factuality by a 30% relative margin against these decoders in NLI-based evaluation on the subsets of CNN/DM and XSum used in the FRANK benchmark, while maintaining comparable ROUGE-1 F1 scores against reference summaries. We collect human verifications of the generated summaries, confirming the factual superiority of our method.
Automatically Evaluating Opinion Prevalence in Opinion Summarization
Jul 26, 2023When faced with a large number of product reviews, it is not clear that a human can remember all of them and weight opinions representatively to write a good reference summary. We propose an automatic metric to test the prevalence of the opinions that a summary expresses, based on counting the number of reviews that are consistent with each statement in the summary, while discrediting trivial or redundant statements. To formulate this opinion prevalence metric, we consider several existing methods to score the factual consistency of a summary statement with respect to each individual source review. On a corpus of Amazon product reviews, we gather multiple human judgments of the opinion consistency, to determine which automatic metric best expresses consistency in product reviews. Using the resulting opinion prevalence metric, we show that a human authored summary has only slightly better opinion prevalence than randomly selected extracts from the source reviews, and previous extractive and abstractive unsupervised opinion summarization methods perform worse than humans. We demonstrate room for improvement with a greedy construction of extractive summaries with twice the opinion prevalence achieved by humans. Finally, we show that preprocessing source reviews by simplification can raise the opinion prevalence achieved by existing abstractive opinion summarization systems to the level of human performance.
KGxBoard: Explainable and Interactive Leaderboard for Evaluation of Knowledge Graph Completion Models
Aug 23, 2022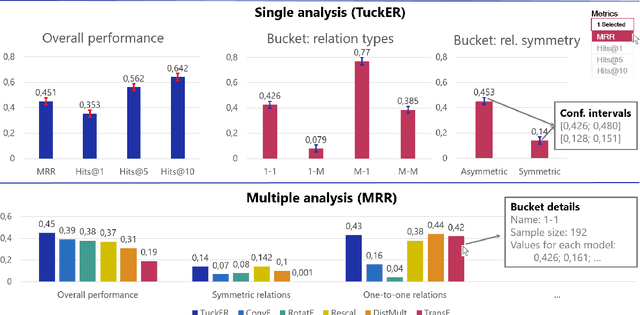
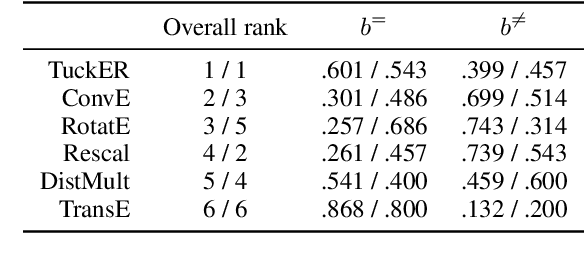

Knowledge Graphs (KGs) store information in the form of (head, predicate, tail)-triples. To augment KGs with new knowledge, researchers proposed models for KG Completion (KGC) tasks such as link prediction; i.e., answering (h; p; ?) or (?; p; t) queries. Such models are usually evaluated with averaged metrics on a held-out test set. While useful for tracking progress, averaged single-score metrics cannot reveal what exactly a model has learned -- or failed to learn. To address this issue, we propose KGxBoard: an interactive framework for performing fine-grained evaluation on meaningful subsets of the data, each of which tests individual and interpretable capabilities of a KGC model. In our experiments, we highlight the findings that we discovered with the use of KGxBoard, which would have been impossible to detect with standard averaged single-score metrics.
Fast Few-shot Debugging for NLU Test Suites
Apr 13, 2022
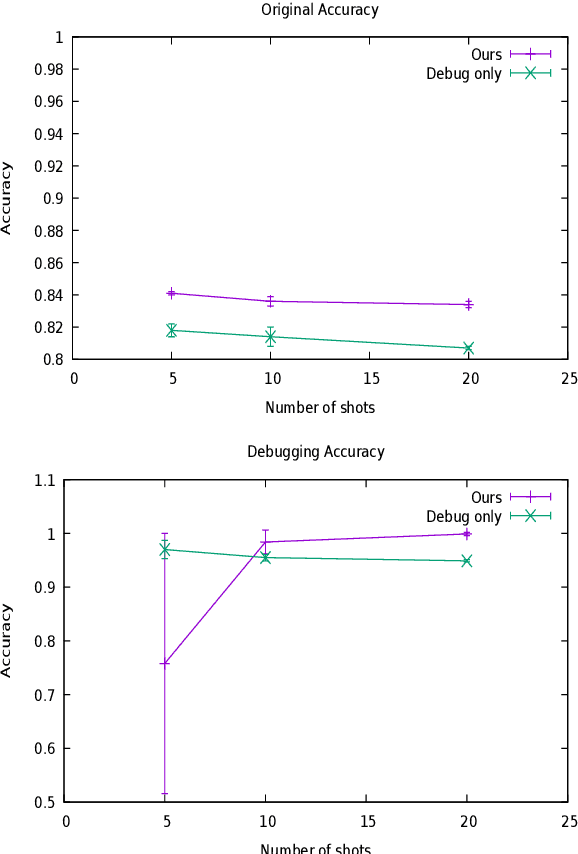
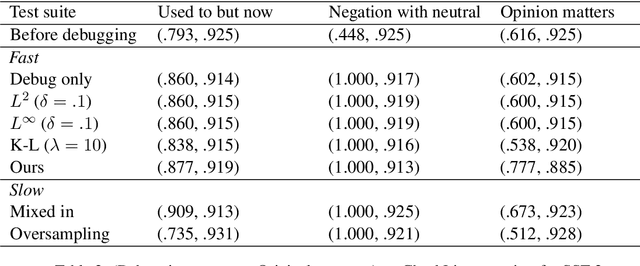
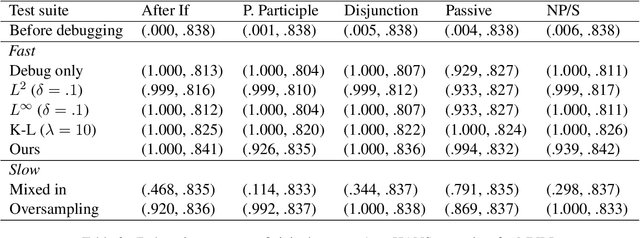
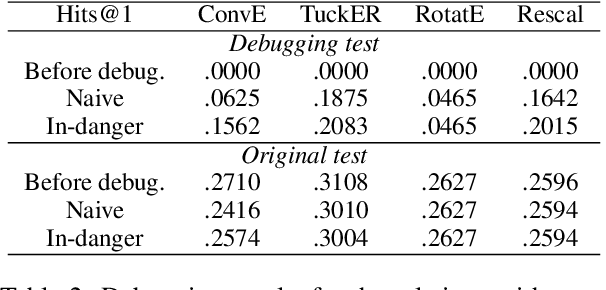
We study few-shot debugging of transformer based natural language understanding models, using recently popularized test suites to not just diagnose but correct a problem. Given a few debugging examples of a certain phenomenon, and a held-out test set of the same phenomenon, we aim to maximize accuracy on the phenomenon at a minimal cost of accuracy on the original test set. We examine several methods that are faster than full epoch retraining. We introduce a new fast method, which samples a few in-danger examples from the original training set. Compared to fast methods using parameter distance constraints or Kullback-Leibler divergence, we achieve superior original accuracy for comparable debugging accuracy.
Overcoming Poor Word Embeddings with Word Definitions
Mar 05, 2021

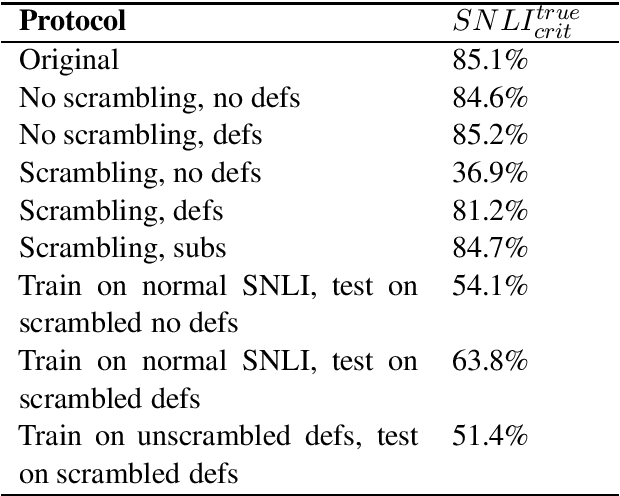
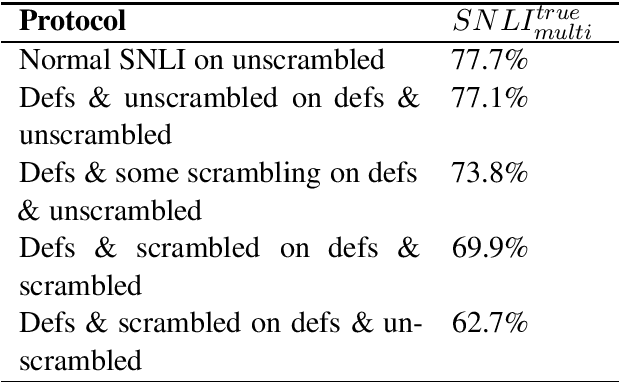
Modern natural language understanding models depend on pretrained subword embeddings, but applications may need to reason about words that were never or rarely seen during pretraining. We show that examples that depend critically on a rarer word are more challenging for natural language inference models. Then we explore how a model could learn to use definitions, provided in natural text, to overcome this handicap. Our model's understanding of a definition is usually weaker than a well-modeled word embedding, but it recovers most of the performance gap from using a completely untrained word.
Improving Neural Network Robustness through Neighborhood Preserving Layers
Jan 29, 2021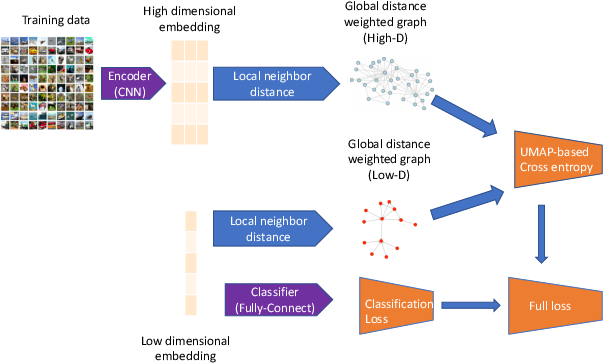
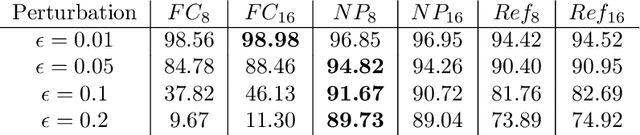
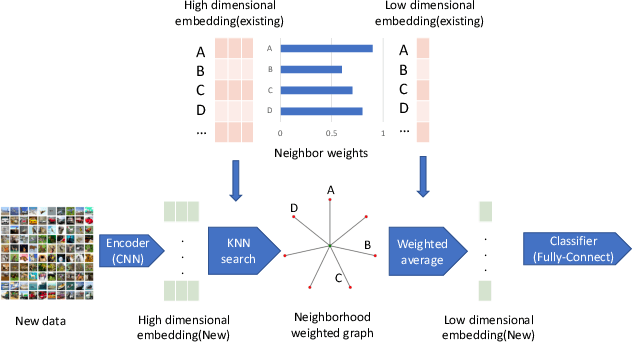
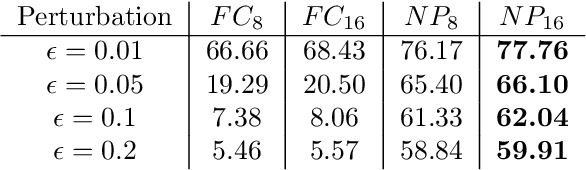
Robustness against adversarial attack in neural networks is an important research topic in the machine learning community. We observe one major source of vulnerability of neural nets is from overparameterized fully-connected layers. In this paper, we propose a new neighborhood preserving layer which can replace these fully connected layers to improve the network robustness. We demonstrate a novel neural network architecture which can incorporate such layers and also can be trained efficiently. We theoretically prove that our models are more robust against distortion because they effectively control the magnitude of gradients. Finally, we empirically show that our designed network architecture is more robust against state-of-art gradient descent based attacks, such as a PGD attack on the benchmark datasets MNIST and CIFAR10.