 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Embedding Guided Negative Sample Generation for Knowledge Graph Link Prediction
Apr 04, 2025Knowledge graph embedding (KGE) models encode the structural information of knowledge graphs to predicting new links. Effective training of these models requires distinguishing between positive and negative samples with high precision. Although prior research has shown that improving the quality of negative samples can significantly enhance model accuracy, identifying high-quality negative samples remains a challenging problem. This paper theoretically investigates the condition under which negative samples lead to optimal KG embedding and identifies a sufficient condition for an effective negative sample distribution. Based on this theoretical foundation, we propose \textbf{E}mbedding \textbf{MU}tation (\textsc{EMU}), a novel framework that \emph{generates} negative samples satisfying this condition, in contrast to conventional methods that focus on \emph{identifying} challenging negative samples within the training data. Importantly, the simplicity of \textsc{EMU} ensures seamless integration with existing KGE models and negative sampling methods. To evaluate its efficacy, we conducted comprehensive experiments across multiple datasets. The results consistently demonstrate significant improvements in link prediction performance across various KGE models and negative sampling methods. Notably, \textsc{EMU} enables performance improvements comparable to those achieved by models with embedding dimension five times larger. An implementation of the method and experiments are available at https://github.com/nec-research/EMU-KG.
Walking a Tightrope -- Evaluating Large Language Models in High-Risk Domains
Nov 25, 2023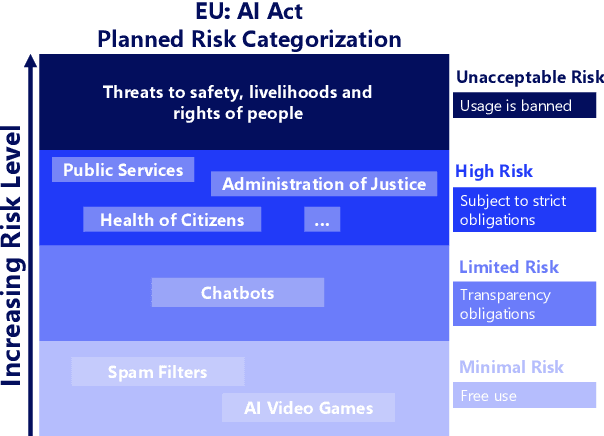

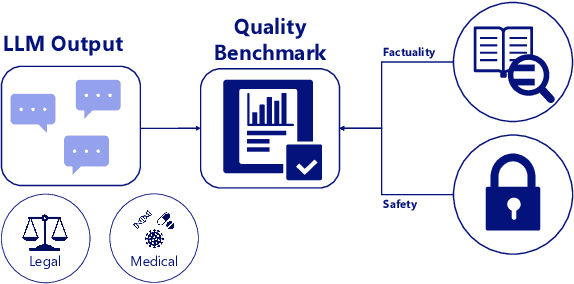
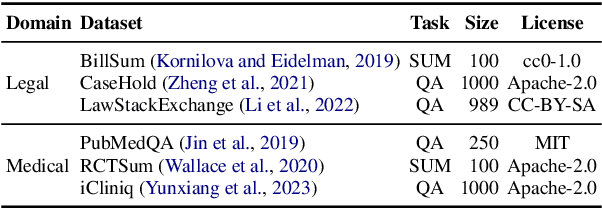
High-risk domains pose unique challenges that require language models to provide accurate and safe responses. Despite the great success of large language models (LLMs), such as ChatGPT and its variants, their performance in high-risk domains remains unclear. Our study delves into an in-depth analysis of the performance of instruction-tuned LLMs, focusing on factual accuracy and safety adherence. To comprehensively assess the capabilities of LLMs, we conduct experiments on six NLP datasets including question answering and summarization tasks within two high-risk domains: legal and medical. Further qualitative analysis highlights the existing limitations inherent in current LLMs when evaluating in high-risk domains. This underscores the essential nature of not only improving LLM capabilities but also prioritizing the refinement of domain-specific metrics, and embracing a more human-centric approach to enhance safety and factual reliability. Our findings advance the field toward the concerns of properly evaluating LLMs in high-risk domains, aiming to steer the adaptability of LLMs in fulfilling societal obligations and aligning with forthcoming regulations, such as the EU AI Act.
KGxBoard: Explainable and Interactive Leaderboard for Evaluation of Knowledge Graph Completion Models
Aug 23, 2022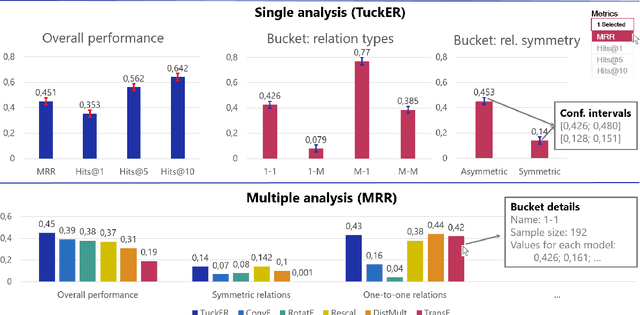
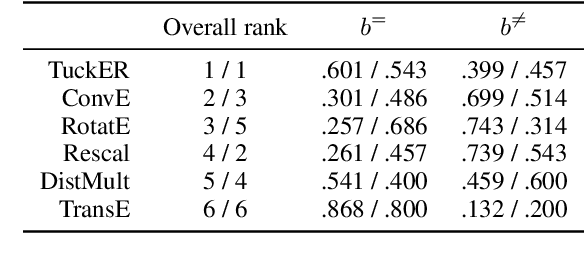

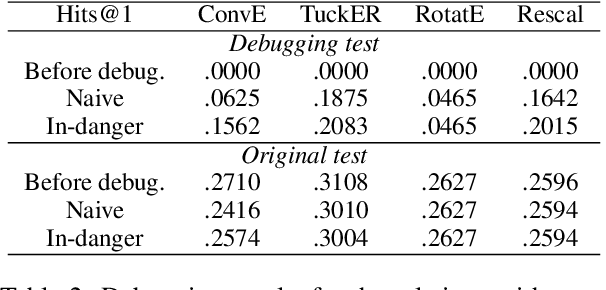
Knowledge Graphs (KGs) store information in the form of (head, predicate, tail)-triples. To augment KGs with new knowledge, researchers proposed models for KG Completion (KGC) tasks such as link prediction; i.e., answering (h; p; ?) or (?; p; t) queries. Such models are usually evaluated with averaged metrics on a held-out test set. While useful for tracking progress, averaged single-score metrics cannot reveal what exactly a model has learned -- or failed to learn. To address this issue, we propose KGxBoard: an interactive framework for performing fine-grained evaluation on meaningful subsets of the data, each of which tests individual and interpretable capabilities of a KGC model. In our experiments, we highlight the findings that we discovered with the use of KGxBoard, which would have been impossible to detect with standard averaged single-score metrics.