 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
Randomly Removing 50% of Dimensions in Text Embeddings has Minimal Impact on Retrieval and Classification Tasks
Aug 25, 2025In this paper, we study the surprising impact that truncating text embeddings has on downstream performance. We consistently observe across 6 state-of-the-art text encoders and 26 downstream tasks, that randomly removing up to 50% of embedding dimensions results in only a minor drop in performance, less than 10%, in retrieval and classification tasks. Given the benefits of using smaller-sized embeddings, as well as the potential insights about text encoding, we study this phenomenon and find that, contrary to what is suggested in prior work, this is not the result of an ineffective use of representation space. Instead, we find that a large number of uniformly distributed dimensions actually cause an increase in performance when removed. This would explain why, on average, removing a large number of embedding dimensions results in a marginal drop in performance. We make similar observations when truncating the embeddings used by large language models to make next-token predictions on generative tasks, suggesting that this phenomenon is not isolated to classification or retrieval tasks.
Enriching Social Science Research via Survey Item Linking
Dec 20, 2024Questions within surveys, called survey items, are used in the social sciences to study latent concepts, such as the factors influencing life satisfaction. Instead of using explicit citations, researchers paraphrase the content of the survey items they use in-text. However, this makes it challenging to find survey items of interest when comparing related work. Automatically parsing and linking these implicit mentions to survey items in a knowledge base can provide more fine-grained references. We model this task, called Survey Item Linking (SIL), in two stages: mention detection and entity disambiguation. Due to an imprecise definition of the task, existing datasets used for evaluating the performance for SIL are too small and of low-quality. We argue that latent concepts and survey item mentions should be differentiated. To this end, we create a high-quality and richly annotated dataset consisting of 20,454 English and German sentences. By benchmarking deep learning systems for each of the two stages independently and sequentially, we demonstrate that the task is feasible, but observe that errors propagate from the first stage, leading to a lower overall task performance. Moreover, mentions that require the context of multiple sentences are more challenging to identify for models in the first stage. Modeling the entire context of a document and combining the two stages into an end-to-end system could mitigate these problems in future work, and errors could additionally be reduced by collecting more diverse data and by improving the quality of the knowledge base. The data and code are available at https://github.com/e-tornike/SIL .
KGxBoard: Explainable and Interactive Leaderboard for Evaluation of Knowledge Graph Completion Models
Aug 23, 2022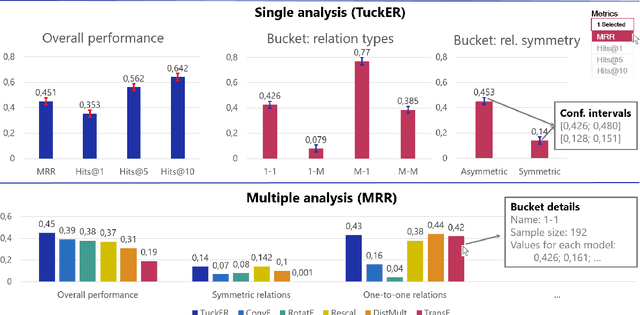

Knowledge Graphs (KGs) store information in the form of (head, predicate, tail)-triples. To augment KGs with new knowledge, researchers proposed models for KG Completion (KGC) tasks such as link prediction; i.e., answering (h; p; ?) or (?; p; t) queries. Such models are usually evaluated with averaged metrics on a held-out test set. While useful for tracking progress, averaged single-score metrics cannot reveal what exactly a model has learned -- or failed to learn. To address this issue, we propose KGxBoard: an interactive framework for performing fine-grained evaluation on meaningful subsets of the data, each of which tests individual and interpretable capabilities of a KGC model. In our experiments, we highlight the findings that we discovered with the use of KGxBoard, which would have been impossible to detect with standard averaged single-score metrics.
Do Embedding Models Perform Well for Knowledge Base Completion?
Nov 06, 2018
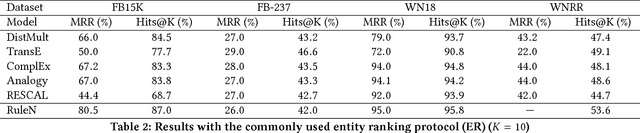
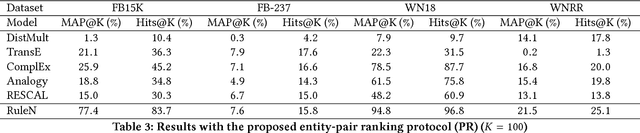
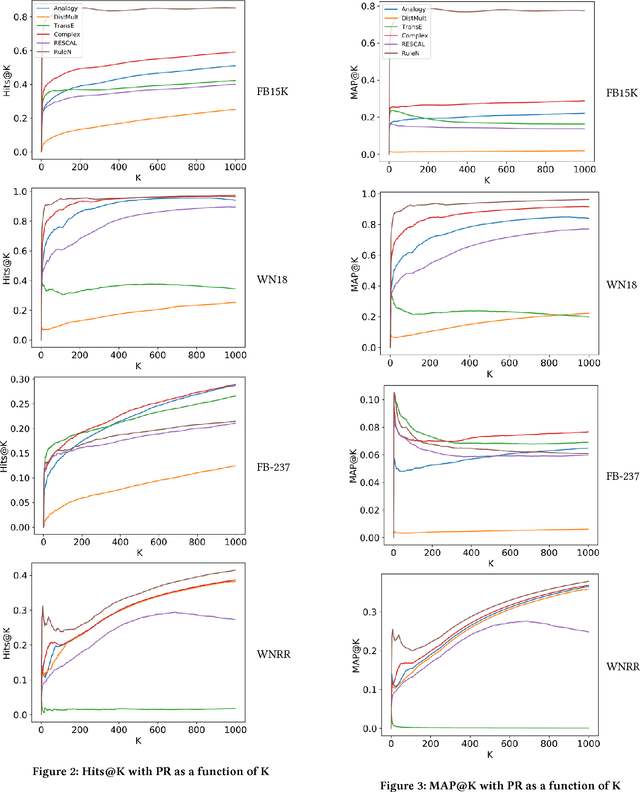
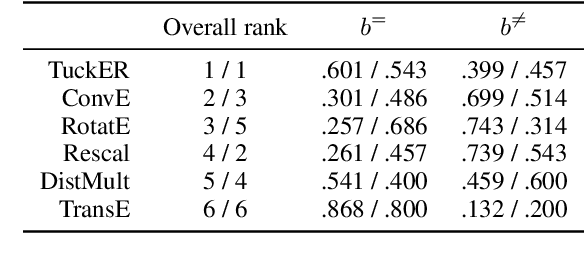
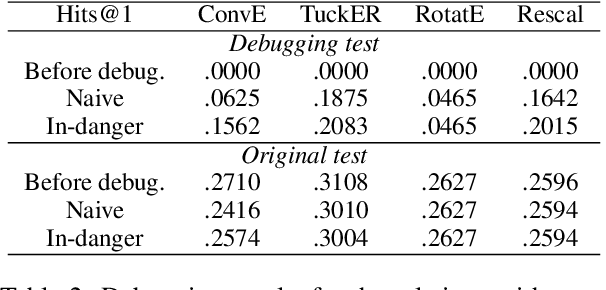
In this work, we put into question the effectiveness of the evaluation methods currently used to measure the performance of latent factor models for the task of knowledge base completion. We argue that by focusing on a small subset of possible facts in the knowledge base, current evaluation practices are better suited for question answering tasks, rather than knowledge base completion, where it is also important to avoid the addition of incorrect facts into the knowledge base. We illustrate our point by showing how models with limited expressiveness achieve state-of-the-art performance, even while adding many incorrect (even nonsensical) facts to a knowledge base. Finally, we show that when using a simple evaluation procedure designed to also penalize the addition of incorrect facts, the general and relative performance of all models looks very different than previously seen. This indicates the need for more powerful latent factor models for the task of knowledge base completion.