 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Semi-Inductive Link Prediction in Knowledge Graphs
Oct 18, 2023



Semi-inductive link prediction (LP) in knowledge graphs (KG) is the task of predicting facts for new, previously unseen entities based on context information. Although new entities can be integrated by retraining the model from scratch in principle, such an approach is infeasible for large-scale KGs, where retraining is expensive and new entities may arise frequently. In this paper, we propose and describe a large-scale benchmark to evaluate semi-inductive LP models. The benchmark is based on and extends Wikidata5M: It provides transductive, k-shot, and 0-shot LP tasks, each varying the available information from (i) only KG structure, to (ii) including textual mentions, and (iii) detailed descriptions of the entities. We report on a small study of recent approaches and found that semi-inductive LP performance is far from transductive performance on long-tail entities throughout all experiments. The benchmark provides a test bed for further research into integrating context and textual information in semi-inductive LP models.
Friendly Neighbors: Contextualized Sequence-to-Sequence Link Prediction
May 22, 2023



We propose KGT5-context, a simple sequence-to-sequence model for link prediction (LP) in knowledge graphs (KG). Our work expands on KGT5, a recent LP model that exploits textual features of the KG, has small model size, and is scalable. To reach good predictive performance, however, KGT5 relies on an ensemble with a knowledge graph embedding model, which itself is excessively large and costly to use. In this short paper, we show empirically that adding contextual information - i.e., information about the direct neighborhood of a query vertex - alleviates the need for a separate KGE model to obtain good performance. The resulting KGT5-context model obtains state-of-the-art performance in our experimental study, while at the same time reducing model size significantly.
Start Small, Think Big: On Hyperparameter Optimization for Large-Scale Knowledge Graph Embeddings
Jul 11, 2022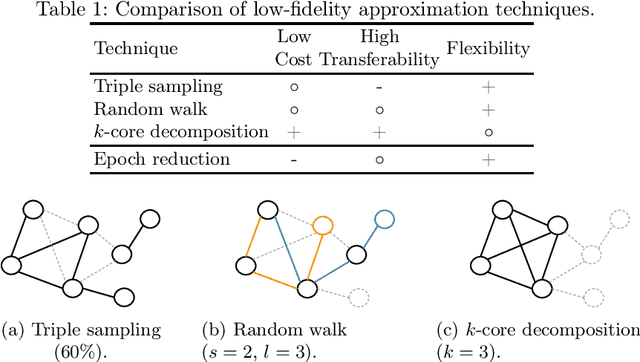
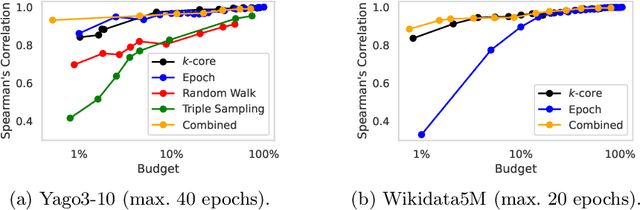
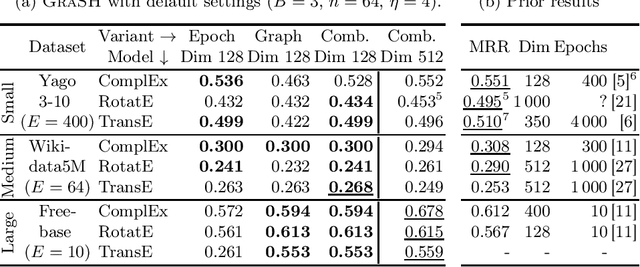
Knowledge graph embedding (KGE) models are an effective and popular approach to represent and reason with multi-relational data. Prior studies have shown that KGE models are sensitive to hyperparameter settings, however, and that suitable choices are dataset-dependent. In this paper, we explore hyperparameter optimization (HPO) for very large knowledge graphs, where the cost of evaluating individual hyperparameter configurations is excessive. Prior studies often avoided this cost by using various heuristics; e.g., by training on a subgraph or by using fewer epochs. We systematically discuss and evaluate the quality and cost savings of such heuristics and other low-cost approximation techniques. Based on our findings, we introduce GraSH, an efficient multi-fidelity HPO algorithm for large-scale KGEs that combines both graph and epoch reduction techniques and runs in multiple rounds of increasing fidelities. We conducted an experimental study and found that GraSH obtains state-of-the-art results on large graphs at a low cost (three complete training runs in total).
Good Intentions: Adaptive Parameter Servers via Intent Signaling
Jun 01, 2022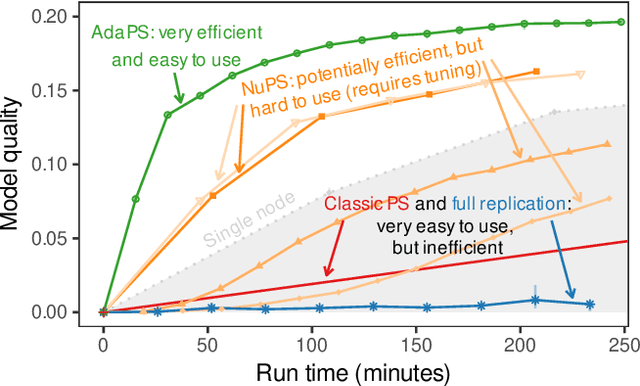


Parameter servers (PSs) ease the implementation of distributed training for large machine learning (ML) tasks by providing primitives for shared parameter access. Especially for ML tasks that access parameters sparsely, PSs can achieve high efficiency and scalability. To do so, they employ a number of techniques -- such as replication or relocation -- to reduce communication cost and/or latency of parameter accesses. A suitable choice and parameterization of these techniques is crucial to realize these gains, however. Unfortunately, such choices depend on the task, the workload, and even individual parameters, they often require expensive upfront experimentation, and they are susceptible to workload changes. In this paper, we explore whether PSs can automatically adapt to the workload without any prior tuning. Our goals are to improve usability and to maintain (or even improve) efficiency. We propose (i) a novel intent signaling mechanism that acts as an enabler for adaptivity and naturally integrates into ML tasks, and (ii) a fully adaptive, zero-tuning PS called AdaPS based on this mechanism. Our experimental evaluation suggests that automatic adaptation to the workload is indeed possible: AdaPS matched or outperformed state-of-the-art PSs out of the box.
Sequence-to-Sequence Knowledge Graph Completion and Question Answering
Mar 19, 2022
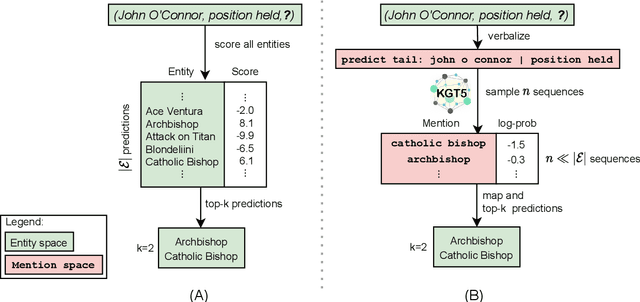
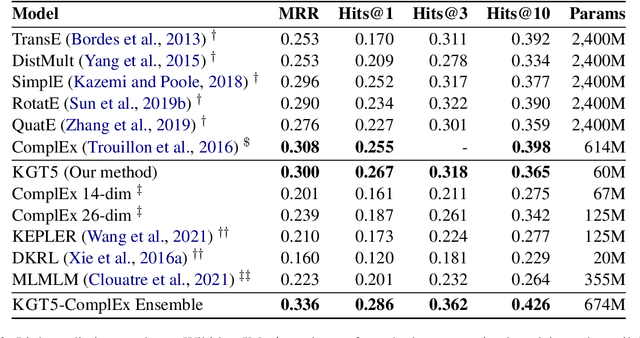
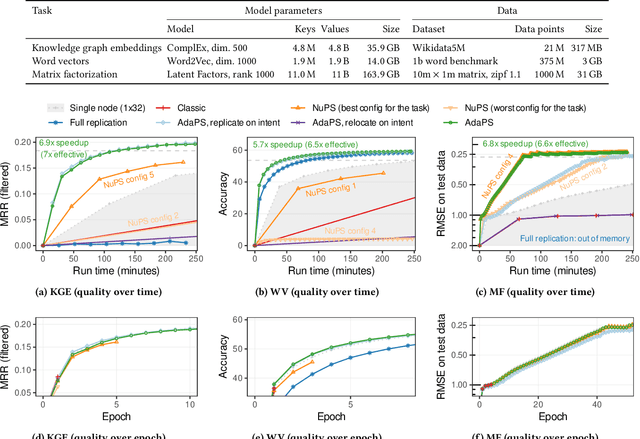
Knowledge graph embedding (KGE) models represent each entity and relation of a knowledge graph (KG) with low-dimensional embedding vectors. These methods have recently been applied to KG link prediction and question answering over incomplete KGs (KGQA). KGEs typically create an embedding for each entity in the graph, which results in large model sizes on real-world graphs with millions of entities. For downstream tasks these atomic entity representations often need to be integrated into a multi stage pipeline, limiting their utility. We show that an off-the-shelf encoder-decoder Transformer model can serve as a scalable and versatile KGE model obtaining state-of-the-art results for KG link prediction and incomplete KG question answering. We achieve this by posing KG link prediction as a sequence-to-sequence task and exchange the triple scoring approach taken by prior KGE methods with autoregressive decoding. Such a simple but powerful method reduces the model size up to 98% compared to conventional KGE models while keeping inference time tractable. After finetuning this model on the task of KGQA over incomplete KGs, our approach outperforms baselines on multiple large-scale datasets without extensive hyperparameter tuning.
Replicate or Relocate? Non-Uniform Access in Parameter Servers
Apr 01, 2021Parameter servers (PSs) facilitate the implementation of distributed training for large machine learning tasks. A key challenge for PS performance is that parameter access is non-uniform in many real-world machine learning tasks, i.e., different parameters exhibit drastically different access patterns. We identify skew and nondeterminism as two major sources for non-uniformity. Existing PSs are ill-suited for managing such non-uniform access because they uniformly apply the same parameter management technique to all parameters. As consequence, the performance of existing PSs is negatively affected and may even fall behind that of single node baselines. In this paper, we explore how PSs can manage non-uniform access efficiently. We find that it is key for PSs to support multiple management techniques and to leverage a well-suited management technique for each parameter. We present Lapse2, a PS that replicates hot spot parameters, relocates less frequently accessed parameters, and employs specialized techniques to manage nondeterminism that arises from random sampling. In our experimental study, Lapse2 outperformed existing, single-technique PSs by up to one order of magnitude and provided near-linear scalability across multiple machine learning tasks.
Differentiable Implicit Layers
Oct 14, 2020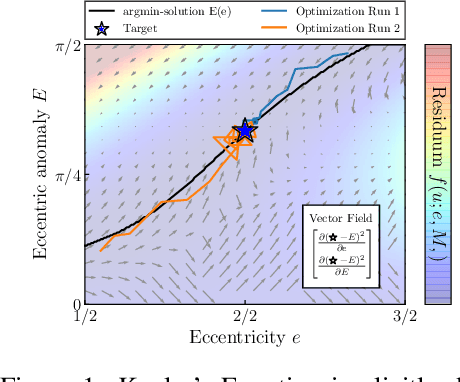
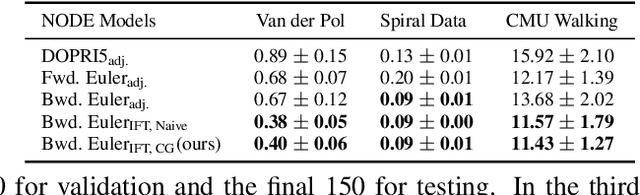
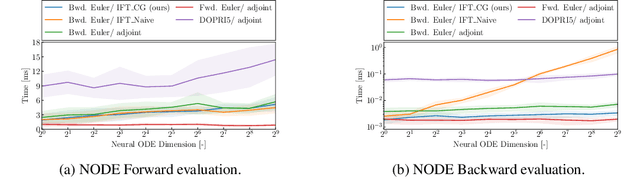

In this paper, we introduce an efficient backpropagation scheme for non-constrained implicit functions. These functions are parametrized by a set of learnable weights and may optionally depend on some input; making them perfectly suitable as learnable layer in a neural network. We demonstrate our scheme on different applications: (i) neural ODEs with the implicit Euler method, and (ii) system identification in model predictive control.
Dynamic Parameter Allocation in Parameter Servers
Feb 03, 2020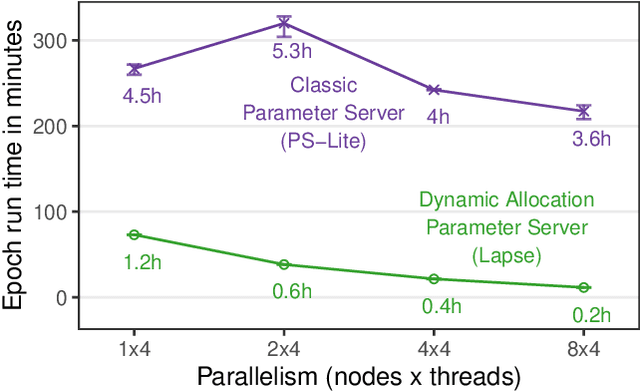
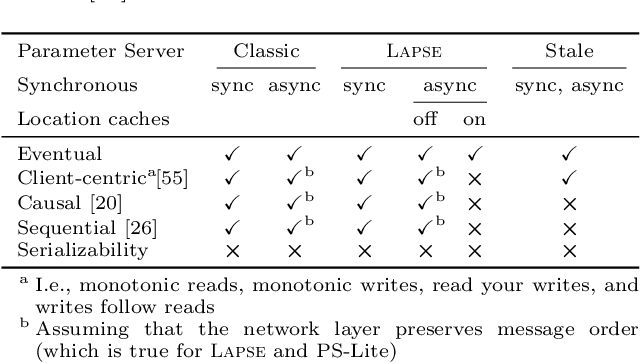
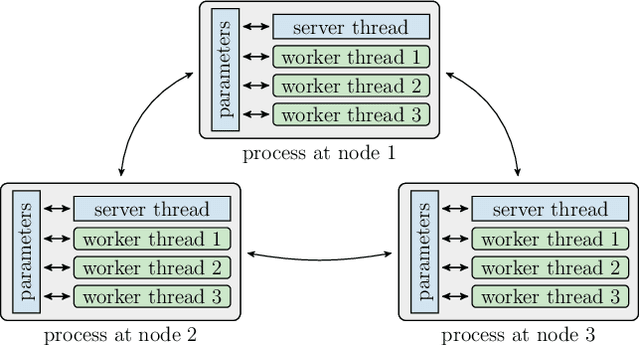
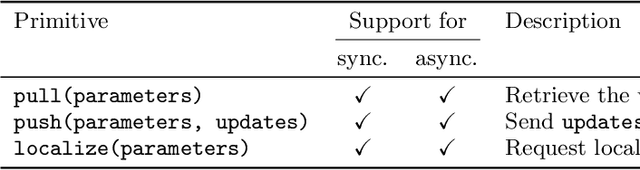
To keep up with increasing dataset sizes and model complexity, distributed training has become a necessity for large machine learning tasks. Parameter servers ease the implementation of distributed parameter management---a key concern in distributed training---, but can induce severe communication overhead. To reduce communication overhead, distributed machine learning algorithms use techniques to increase parameter access locality (PAL), achieving up to linear speed-ups. We found that existing parameter servers provide only limited support for PAL techniques, however, and therefore prevent efficient training. In this paper, we explore whether and to what extent PAL techniques can be supported, and whether such support is beneficial. We propose to integrate dynamic parameter allocation into parameter servers, describe an efficient implementation of such a parameter server called Lapse, and experimentally compare its performance to existing parameter servers across a number of machine learning tasks. We found that Lapse provides near linear scaling and can be orders of magnitude faster than existing parameter servers.
OPIEC: An Open Information Extraction Corpus
Apr 28, 2019
Open information extraction (OIE) systems extract relations and their arguments from natural language text in an unsupervised manner. The resulting extractions are a valuable resource for downstream tasks such as knowledge base construction, open question answering, or event schema induction. In this paper, we release, describe, and analyze an OIE corpus called OPIEC, which was extracted from the text of English Wikipedia. OPIEC complements the available OIE resources: It is the largest OIE corpus publicly available to date (over 340M triples) and contains valuable metadata such as provenance information, confidence scores, linguistic annotations, and semantic annotations including spatial and temporal information. We analyze the OPIEC corpus by comparing its content with knowledge bases such as DBpedia or YAGO, which are also based on Wikipedia. We found that most of the facts between entities present in OPIEC cannot be found in DBpedia and/or YAGO, that OIE facts often differ in the level of specificity compared to knowledge base facts, and that OIE open relations are generally highly polysemous. We believe that the OPIEC corpus is a valuable resource for future research on automated knowledge base construction.
* In Proceedings of the Conference of Automatic Knowledge Base Construction (AKBC) 2019
A Relational Tucker Decomposition for Multi-Relational Link Prediction
Feb 03, 2019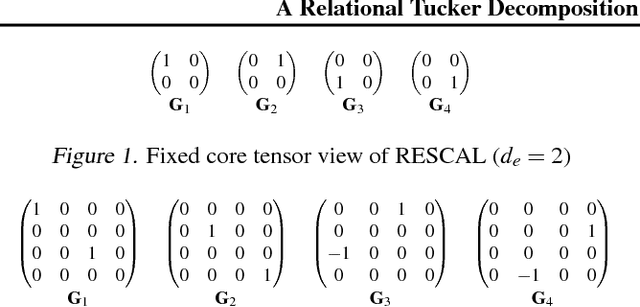

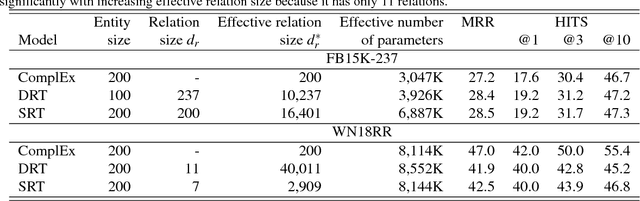
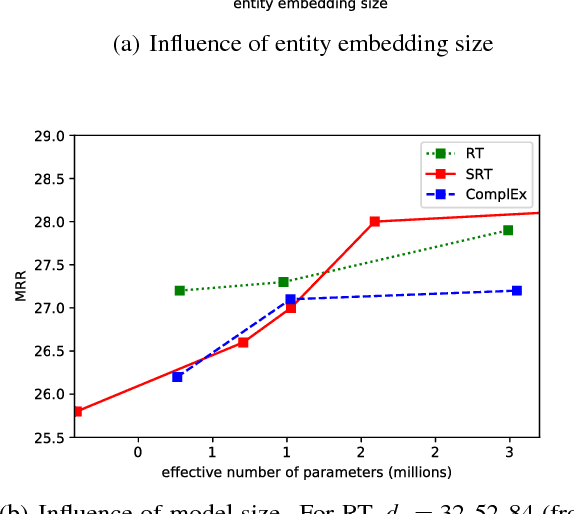
We propose the Relational Tucker3 (RT) decomposition for multi-relational link prediction in knowledge graphs. We show that many existing knowledge graph embedding models are special cases of the RT decomposition with certain predefined sparsity patterns in its components. In contrast to these prior models, RT decouples the sizes of entity and relation embeddings, allows parameter sharing across relations, and does not make use of a predefined sparsity pattern. We use the RT decomposition as a tool to explore whether it is possible and beneficial to automatically learn sparsity patterns, and whether dense models can outperform sparse models (using the same number of parameters). Our experiments indicate that---depending on the dataset--both questions can be answered affirmatively.