 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Relational Tucker Decomposition for Multi-Relational Link Prediction
Paper and Code
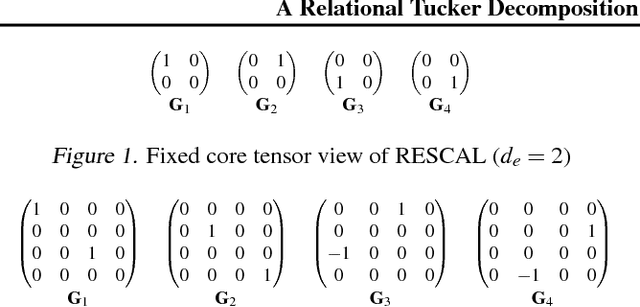

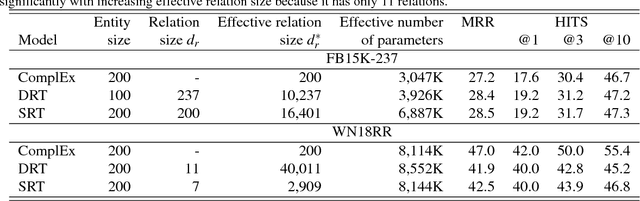
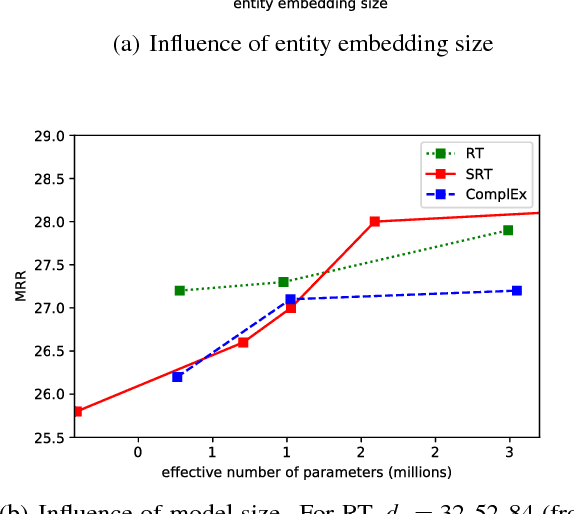
We propose the Relational Tucker3 (RT) decomposition for multi-relational link prediction in knowledge graphs. We show that many existing knowledge graph embedding models are special cases of the RT decomposition with certain predefined sparsity patterns in its components. In contrast to these prior models, RT decouples the sizes of entity and relation embeddings, allows parameter sharing across relations, and does not make use of a predefined sparsity pattern. We use the RT decomposition as a tool to explore whether it is possible and beneficial to automatically learn sparsity patterns, and whether dense models can outperform sparse models (using the same number of parameters). Our experiments indicate that---depending on the dataset--both questions can be answered affirmatively.