 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood Intentions: Adaptive Parameter Servers via Intent Signaling
Jun 01, 2022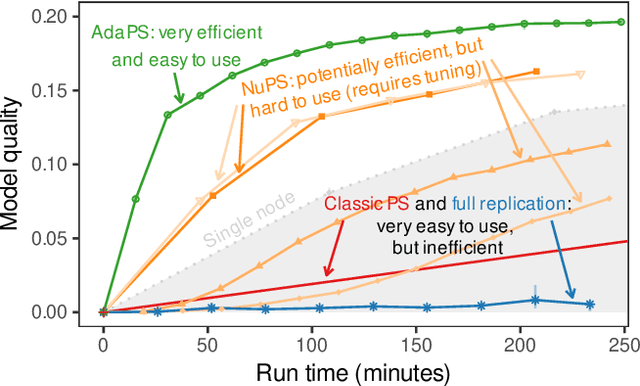


Parameter servers (PSs) ease the implementation of distributed training for large machine learning (ML) tasks by providing primitives for shared parameter access. Especially for ML tasks that access parameters sparsely, PSs can achieve high efficiency and scalability. To do so, they employ a number of techniques -- such as replication or relocation -- to reduce communication cost and/or latency of parameter accesses. A suitable choice and parameterization of these techniques is crucial to realize these gains, however. Unfortunately, such choices depend on the task, the workload, and even individual parameters, they often require expensive upfront experimentation, and they are susceptible to workload changes. In this paper, we explore whether PSs can automatically adapt to the workload without any prior tuning. Our goals are to improve usability and to maintain (or even improve) efficiency. We propose (i) a novel intent signaling mechanism that acts as an enabler for adaptivity and naturally integrates into ML tasks, and (ii) a fully adaptive, zero-tuning PS called AdaPS based on this mechanism. Our experimental evaluation suggests that automatic adaptation to the workload is indeed possible: AdaPS matched or outperformed state-of-the-art PSs out of the box.
Replicate or Relocate? Non-Uniform Access in Parameter Servers
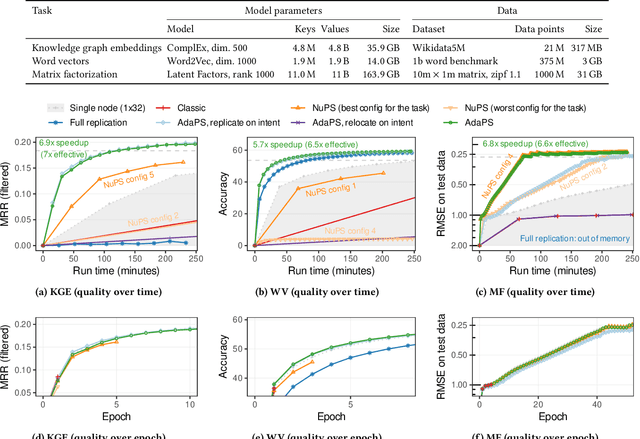
Apr 01, 2021Parameter servers (PSs) facilitate the implementation of distributed training for large machine learning tasks. A key challenge for PS performance is that parameter access is non-uniform in many real-world machine learning tasks, i.e., different parameters exhibit drastically different access patterns. We identify skew and nondeterminism as two major sources for non-uniformity. Existing PSs are ill-suited for managing such non-uniform access because they uniformly apply the same parameter management technique to all parameters. As consequence, the performance of existing PSs is negatively affected and may even fall behind that of single node baselines. In this paper, we explore how PSs can manage non-uniform access efficiently. We find that it is key for PSs to support multiple management techniques and to leverage a well-suited management technique for each parameter. We present Lapse2, a PS that replicates hot spot parameters, relocates less frequently accessed parameters, and employs specialized techniques to manage nondeterminism that arises from random sampling. In our experimental study, Lapse2 outperformed existing, single-technique PSs by up to one order of magnitude and provided near-linear scalability across multiple machine learning tasks.
Dynamic Parameter Allocation in Parameter Servers
Feb 03, 2020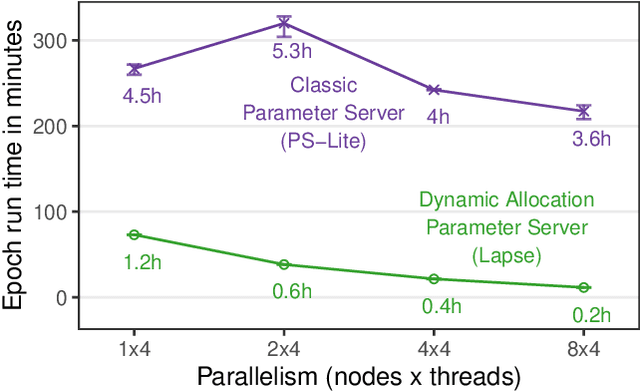
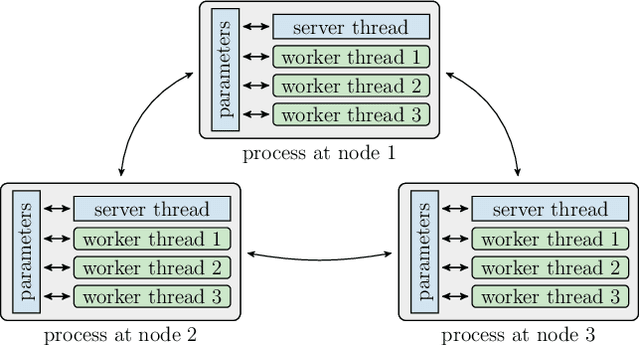
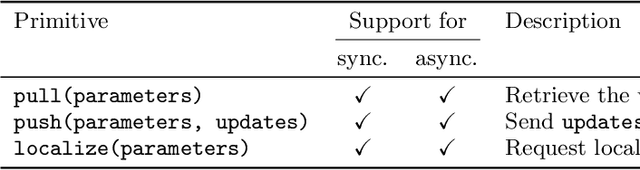
To keep up with increasing dataset sizes and model complexity, distributed training has become a necessity for large machine learning tasks. Parameter servers ease the implementation of distributed parameter management---a key concern in distributed training---, but can induce severe communication overhead. To reduce communication overhead, distributed machine learning algorithms use techniques to increase parameter access locality (PAL), achieving up to linear speed-ups. We found that existing parameter servers provide only limited support for PAL techniques, however, and therefore prevent efficient training. In this paper, we explore whether and to what extent PAL techniques can be supported, and whether such support is beneficial. We propose to integrate dynamic parameter allocation into parameter servers, describe an efficient implementation of such a parameter server called Lapse, and experimentally compare its performance to existing parameter servers across a number of machine learning tasks. We found that Lapse provides near linear scaling and can be orders of magnitude faster than existing parameter servers.