 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Parameter Allocation in Parameter Servers
Feb 03, 2020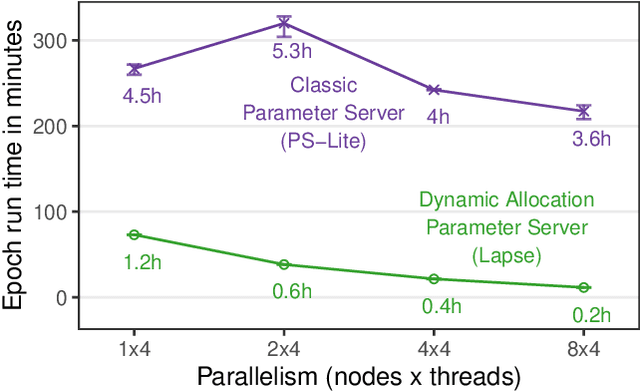
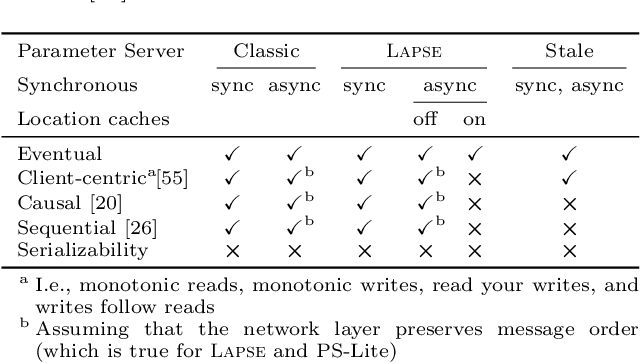
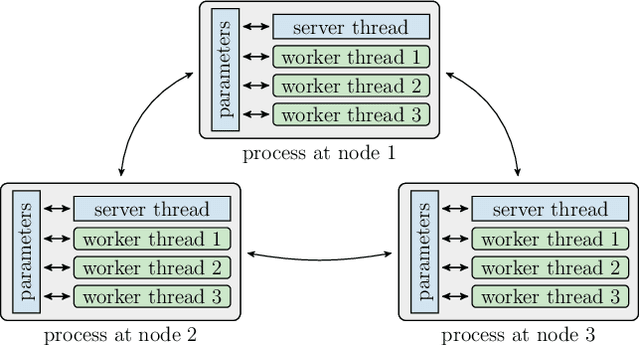
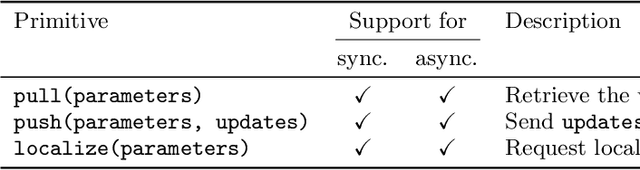
To keep up with increasing dataset sizes and model complexity, distributed training has become a necessity for large machine learning tasks. Parameter servers ease the implementation of distributed parameter management---a key concern in distributed training---, but can induce severe communication overhead. To reduce communication overhead, distributed machine learning algorithms use techniques to increase parameter access locality (PAL), achieving up to linear speed-ups. We found that existing parameter servers provide only limited support for PAL techniques, however, and therefore prevent efficient training. In this paper, we explore whether and to what extent PAL techniques can be supported, and whether such support is beneficial. We propose to integrate dynamic parameter allocation into parameter servers, describe an efficient implementation of such a parameter server called Lapse, and experimentally compare its performance to existing parameter servers across a number of machine learning tasks. We found that Lapse provides near linear scaling and can be orders of magnitude faster than existing parameter servers.