 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedPart: Embedding-Driven Graph Partitioning for Scalable Graph Neural Network Training
Apr 01, 2026Graph Neural Networks (GNNs) are widely used for learning on graph-structured data, but scaling GNN training to massive graphs remains challenging. To enable scalable distributed training, graphs are divided into smaller partitions that are distributed across multiple machines such that inter-machine communication is minimized and computational load is balanced. In practice, existing partitioning approaches face a fundamental trade-off between partitioning overhead and partitioning quality. We propose EmbedPart, an embedding-driven partitioning approach that achieves both speed and quality. Instead of operating directly on irregular graph structures, EmbedPart leverages node embeddings produced during the actual GNN training workload and clusters these dense embeddings to derive a partitioning. EmbedPart achieves more than 100x speedup over Metis while maintaining competitive partitioning quality and accelerating distributed GNN training. Moreover, EmbedPart naturally supports graph updates and fast repartitioning, and can be applied to graph reordering to improve data locality and accelerate single-machine GNN training. By shifting partitioning from irregular graph structures to dense embeddings, EmbedPart enables scalable and high-quality graph data optimization.
reBEN: Refined BigEarthNet Dataset for Remote Sensing Image Analysis
Jul 04, 2024



This paper presents refined BigEarthNet (reBEN) that is a large-scale, multi-modal remote sensing dataset constructed to support deep learning (DL) studies for remote sensing image analysis. The reBEN dataset consists of 549,488 pairs of Sentinel-1 and Sentinel-2 image patches. To construct reBEN, we initially consider the Sentinel-1 and Sentinel-2 tiles used to construct the BigEarthNet dataset and then divide them into patches of size 1200 m x 1200 m. We apply atmospheric correction to the Sentinel-2 patches using the latest version of the sen2cor tool, resulting in higher-quality patches compared to those present in BigEarthNet. Each patch is then associated with a pixel-level reference map and scene-level multi-labels. This makes reBEN suitable for pixel- and scene-based learning tasks. The labels are derived from the most recent CORINE Land Cover (CLC) map of 2018 by utilizing the 19-class nomenclature as in BigEarthNet. The use of the most recent CLC map results in overcoming the label noise present in BigEarthNet. Furthermore, we introduce a new geographical-based split assignment algorithm that significantly reduces the spatial correlation among the train, validation, and test sets with respect to those present in BigEarthNet. This increases the reliability of the evaluation of DL models. To minimize the DL model training time, we introduce software tools that convert the reBEN dataset into a DL-optimized data format. In our experiments, we show the potential of reBEN for multi-modal multi-label image classification problems by considering several state-of-the-art DL models. The pre-trained model weights, associated code, and complete dataset are available at https://bigearth.net.
Missing Value Imputation for Multi-attribute Sensor Data Streams via Message Propagation (Extended Version)
Nov 14, 2023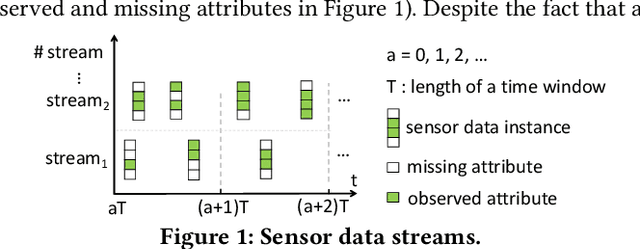

Sensor data streams occur widely in various real-time applications in the context of the Internet of Things (IoT). However, sensor data streams feature missing values due to factors such as sensor failures, communication errors, or depleted batteries. Missing values can compromise the quality of real-time analytics tasks and downstream applications. Existing imputation methods either make strong assumptions about streams or have low efficiency. In this study, we aim to accurately and efficiently impute missing values in data streams that satisfy only general characteristics in order to benefit real-time applications more widely. First, we propose a message propagation imputation network (MPIN) that is able to recover the missing values of data instances in a time window. We give a theoretical analysis of why MPIN is effective. Second, we present a continuous imputation framework that consists of data update and model update mechanisms to enable MPIN to perform continuous imputation both effectively and efficiently. Extensive experiments on multiple real datasets show that MPIN can outperform the existing data imputers by wide margins and that the continuous imputation framework is efficient and accurate.
Artificial intelligence to advance Earth observation: a perspective
May 15, 2023Earth observation (EO) is a prime instrument for monitoring land and ocean processes, studying the dynamics at work, and taking the pulse of our planet. This article gives a bird's eye view of the essential scientific tools and approaches informing and supporting the transition from raw EO data to usable EO-based information. The promises, as well as the current challenges of these developments, are highlighted under dedicated sections. Specifically, we cover the impact of (i) Computer vision; (ii) Machine learning; (iii) Advanced processing and computing; (iv) Knowledge-based AI; (v) Explainable AI and causal inference; (vi) Physics-aware models; (vii) User-centric approaches; and (viii) the much-needed discussion of ethical and societal issues related to the massive use of ML technologies in EO.
Satellite Image Search in AgoraEO
Aug 23, 2022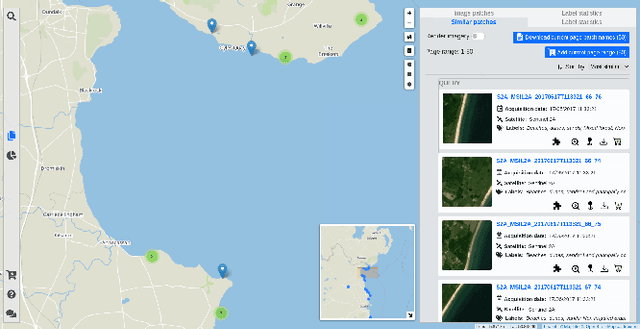

The growing operational capability of global Earth Observation (EO) creates new opportunities for data-driven approaches to understand and protect our planet. However, the current use of EO archives is very restricted due to the huge archive sizes and the limited exploration capabilities provided by EO platforms. To address this limitation, we have recently proposed MiLaN, a content-based image retrieval approach for fast similarity search in satellite image archives. MiLaN is a deep hashing network based on metric learning that encodes high-dimensional image features into compact binary hash codes. We use these codes as keys in a hash table to enable real-time nearest neighbor search and highly accurate retrieval. In this demonstration, we showcase the efficiency of MiLaN by integrating it with EarthQube, a browser and search engine within AgoraEO. EarthQube supports interactive visual exploration and Query-by-Example over satellite image repositories. Demo visitors will interact with EarthQube playing the role of different users that search images in a large-scale remote sensing archive by their semantic content and apply other filters.
Good Intentions: Adaptive Parameter Servers via Intent Signaling
Jun 01, 2022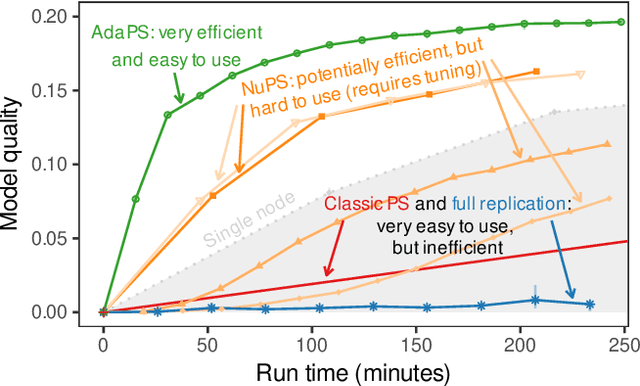


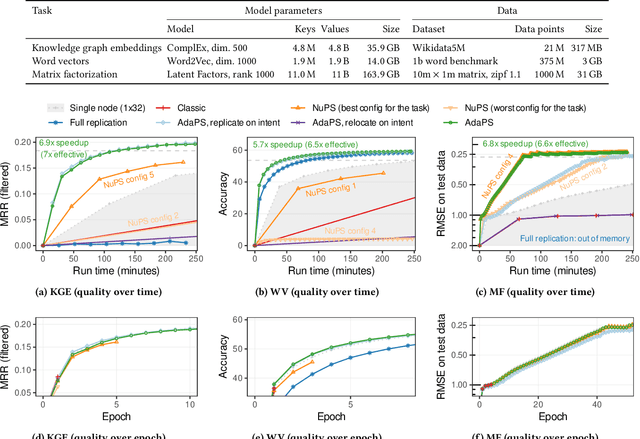
Parameter servers (PSs) ease the implementation of distributed training for large machine learning (ML) tasks by providing primitives for shared parameter access. Especially for ML tasks that access parameters sparsely, PSs can achieve high efficiency and scalability. To do so, they employ a number of techniques -- such as replication or relocation -- to reduce communication cost and/or latency of parameter accesses. A suitable choice and parameterization of these techniques is crucial to realize these gains, however. Unfortunately, such choices depend on the task, the workload, and even individual parameters, they often require expensive upfront experimentation, and they are susceptible to workload changes. In this paper, we explore whether PSs can automatically adapt to the workload without any prior tuning. Our goals are to improve usability and to maintain (or even improve) efficiency. We propose (i) a novel intent signaling mechanism that acts as an enabler for adaptivity and naturally integrates into ML tasks, and (ii) a fully adaptive, zero-tuning PS called AdaPS based on this mechanism. Our experimental evaluation suggests that automatic adaptation to the workload is indeed possible: AdaPS matched or outperformed state-of-the-art PSs out of the box.
Towards Loosely-Coupling Knowledge Graph Embeddings and Ontology-based Reasoning
Feb 07, 2022
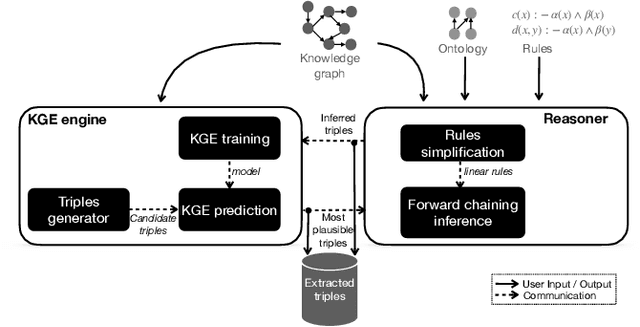


Knowledge graph completion (a.k.a.~link prediction), i.e.,~the task of inferring missing information from knowledge graphs, is a widely used task in many applications, such as product recommendation and question answering. The state-of-the-art approaches of knowledge graph embeddings and/or rule mining and reasoning are data-driven and, thus, solely based on the information the input knowledge graph contains. This leads to unsatisfactory prediction results which make such solutions inapplicable to crucial domains such as healthcare. To further enhance the accuracy of knowledge graph completion we propose to loosely-couple the data-driven power of knowledge graph embeddings with domain-specific reasoning stemming from experts or entailment regimes (e.g., OWL2). In this way, we not only enhance the prediction accuracy with domain knowledge that may not be included in the input knowledge graph but also allow users to plugin their own knowledge graph embedding and reasoning method. Our initial results show that we enhance the MRR accuracy of vanilla knowledge graph embeddings by up to 3x and outperform hybrid solutions that combine knowledge graph embeddings with rule mining and reasoning up to 3.5x MRR.
BigEarthNet-MM: A Large Scale Multi-Modal Multi-Label Benchmark Archive for Remote Sensing Image Classification and Retrieval
May 17, 2021
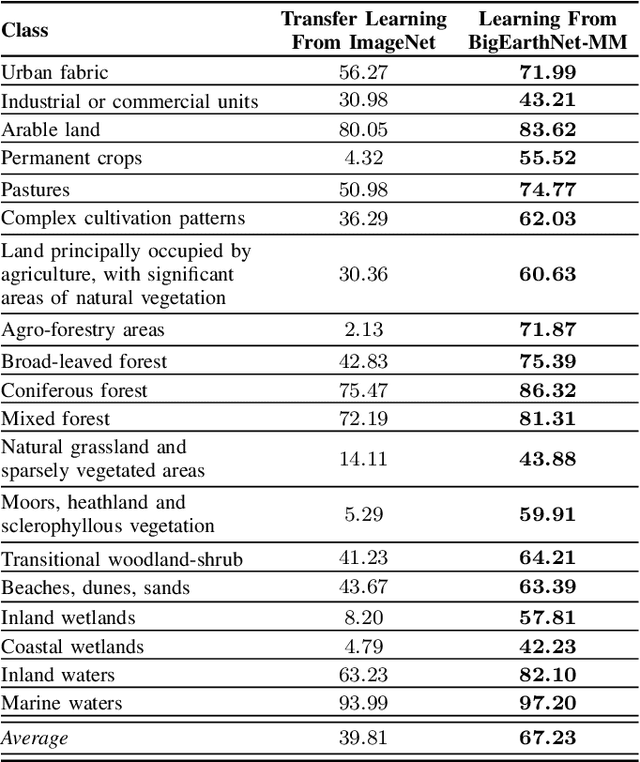
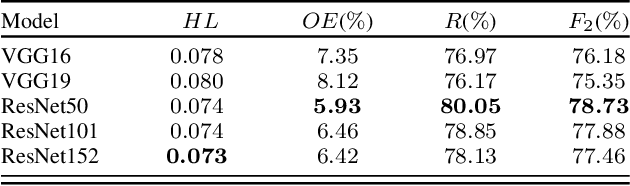
This paper presents the multi-modal BigEarthNet (BigEarthNet-MM) benchmark archive made up of 590,326 pairs of Sentinel-1 and Sentinel-2 image patches to support the deep learning (DL) studies in multi-modal multi-label remote sensing (RS) image retrieval and classification. Each pair of patches in BigEarthNet-MM is annotated with multi-labels provided by the CORINE Land Cover (CLC) map of 2018 based on its thematically most detailed Level-3 class nomenclature. Our initial research demonstrates that some CLC classes are challenging to be accurately described by only considering (single-date) BigEarthNet-MM images. In this paper, we also introduce an alternative class-nomenclature as an evolution of the original CLC labels to address this problem. This is achieved by interpreting and arranging the CLC Level-3 nomenclature based on the properties of BigEarthNet-MM images in a new nomenclature of 19 classes. In our experiments, we show the potential of BigEarthNet-MM for multi-modal multi-label image retrieval and classification problems by considering several state-of-the-art DL models. We also demonstrate that the DL models trained from scratch on BigEarthNet-MM outperform those pre-trained on ImageNet, especially in relation to some complex classes, including agriculture and other vegetated and natural environments. We make all the data and the DL models publicly available at https://bigearth.net, offering an important resource to support studies on multi-modal image scene classification and retrieval problems in RS.
Replicate or Relocate? Non-Uniform Access in Parameter Servers
Apr 01, 2021Parameter servers (PSs) facilitate the implementation of distributed training for large machine learning tasks. A key challenge for PS performance is that parameter access is non-uniform in many real-world machine learning tasks, i.e., different parameters exhibit drastically different access patterns. We identify skew and nondeterminism as two major sources for non-uniformity. Existing PSs are ill-suited for managing such non-uniform access because they uniformly apply the same parameter management technique to all parameters. As consequence, the performance of existing PSs is negatively affected and may even fall behind that of single node baselines. In this paper, we explore how PSs can manage non-uniform access efficiently. We find that it is key for PSs to support multiple management techniques and to leverage a well-suited management technique for each parameter. We present Lapse2, a PS that replicates hot spot parameters, relocates less frequently accessed parameters, and employs specialized techniques to manage nondeterminism that arises from random sampling. In our experimental study, Lapse2 outperformed existing, single-technique PSs by up to one order of magnitude and provided near-linear scalability across multiple machine learning tasks.
Dynamic Parameter Allocation in Parameter Servers
Feb 03, 2020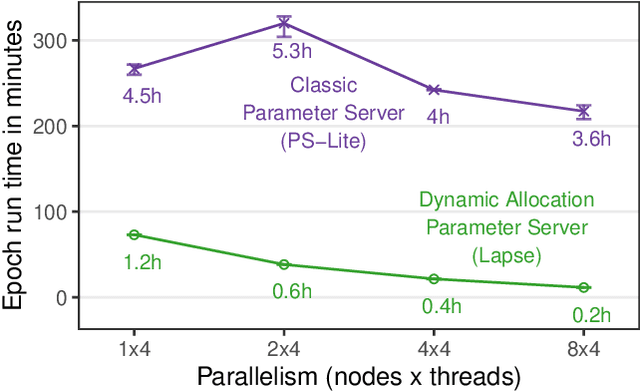
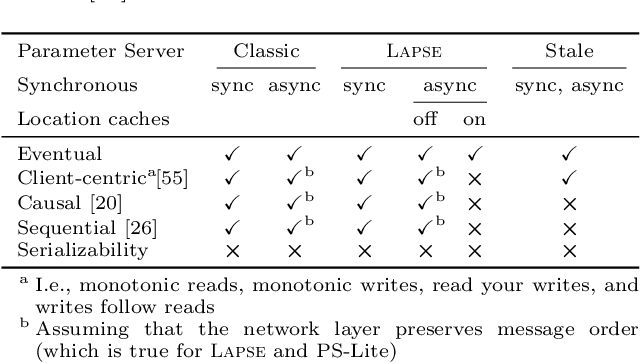
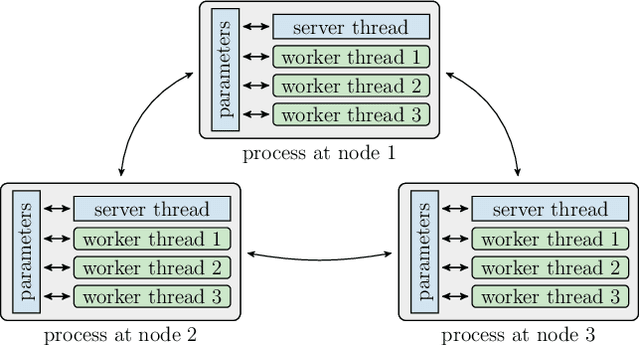
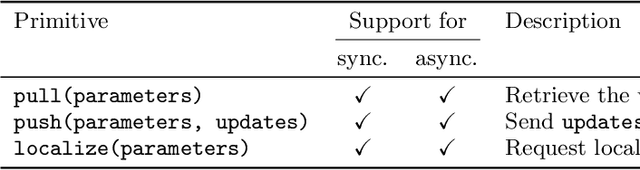
To keep up with increasing dataset sizes and model complexity, distributed training has become a necessity for large machine learning tasks. Parameter servers ease the implementation of distributed parameter management---a key concern in distributed training---, but can induce severe communication overhead. To reduce communication overhead, distributed machine learning algorithms use techniques to increase parameter access locality (PAL), achieving up to linear speed-ups. We found that existing parameter servers provide only limited support for PAL techniques, however, and therefore prevent efficient training. In this paper, we explore whether and to what extent PAL techniques can be supported, and whether such support is beneficial. We propose to integrate dynamic parameter allocation into parameter servers, describe an efficient implementation of such a parameter server called Lapse, and experimentally compare its performance to existing parameter servers across a number of machine learning tasks. We found that Lapse provides near linear scaling and can be orders of magnitude faster than existing parameter servers.