 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood Intentions: Adaptive Parameter Servers via Intent Signaling
Jun 01, 2022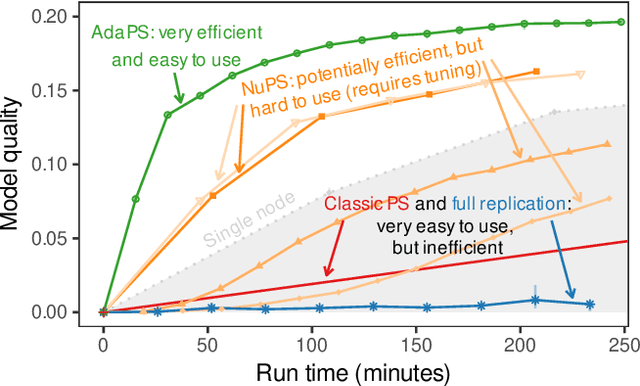


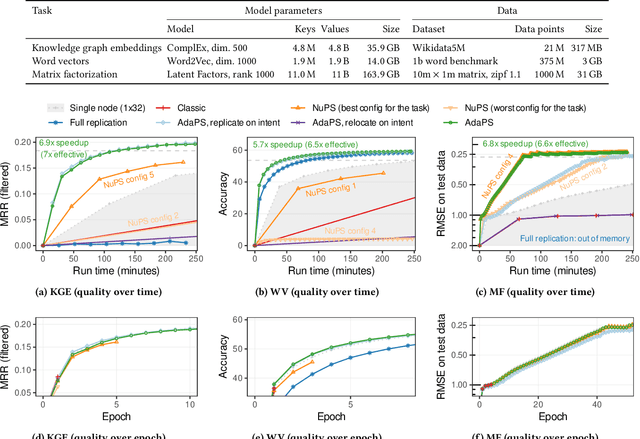
Parameter servers (PSs) ease the implementation of distributed training for large machine learning (ML) tasks by providing primitives for shared parameter access. Especially for ML tasks that access parameters sparsely, PSs can achieve high efficiency and scalability. To do so, they employ a number of techniques -- such as replication or relocation -- to reduce communication cost and/or latency of parameter accesses. A suitable choice and parameterization of these techniques is crucial to realize these gains, however. Unfortunately, such choices depend on the task, the workload, and even individual parameters, they often require expensive upfront experimentation, and they are susceptible to workload changes. In this paper, we explore whether PSs can automatically adapt to the workload without any prior tuning. Our goals are to improve usability and to maintain (or even improve) efficiency. We propose (i) a novel intent signaling mechanism that acts as an enabler for adaptivity and naturally integrates into ML tasks, and (ii) a fully adaptive, zero-tuning PS called AdaPS based on this mechanism. Our experimental evaluation suggests that automatic adaptation to the workload is indeed possible: AdaPS matched or outperformed state-of-the-art PSs out of the box.
Towards Loosely-Coupling Knowledge Graph Embeddings and Ontology-based Reasoning
Feb 07, 2022
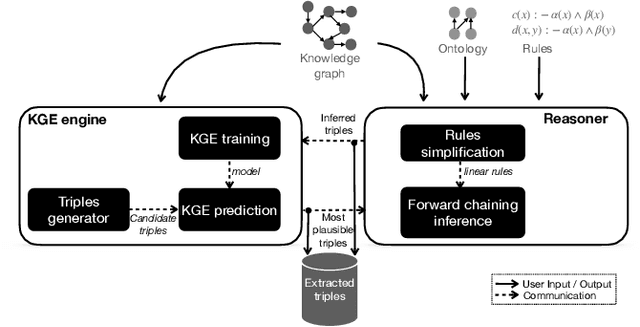


Knowledge graph completion (a.k.a.~link prediction), i.e.,~the task of inferring missing information from knowledge graphs, is a widely used task in many applications, such as product recommendation and question answering. The state-of-the-art approaches of knowledge graph embeddings and/or rule mining and reasoning are data-driven and, thus, solely based on the information the input knowledge graph contains. This leads to unsatisfactory prediction results which make such solutions inapplicable to crucial domains such as healthcare. To further enhance the accuracy of knowledge graph completion we propose to loosely-couple the data-driven power of knowledge graph embeddings with domain-specific reasoning stemming from experts or entailment regimes (e.g., OWL2). In this way, we not only enhance the prediction accuracy with domain knowledge that may not be included in the input knowledge graph but also allow users to plugin their own knowledge graph embedding and reasoning method. Our initial results show that we enhance the MRR accuracy of vanilla knowledge graph embeddings by up to 3x and outperform hybrid solutions that combine knowledge graph embeddings with rule mining and reasoning up to 3.5x MRR.
Replicate or Relocate? Non-Uniform Access in Parameter Servers
Apr 01, 2021Parameter servers (PSs) facilitate the implementation of distributed training for large machine learning tasks. A key challenge for PS performance is that parameter access is non-uniform in many real-world machine learning tasks, i.e., different parameters exhibit drastically different access patterns. We identify skew and nondeterminism as two major sources for non-uniformity. Existing PSs are ill-suited for managing such non-uniform access because they uniformly apply the same parameter management technique to all parameters. As consequence, the performance of existing PSs is negatively affected and may even fall behind that of single node baselines. In this paper, we explore how PSs can manage non-uniform access efficiently. We find that it is key for PSs to support multiple management techniques and to leverage a well-suited management technique for each parameter. We present Lapse2, a PS that replicates hot spot parameters, relocates less frequently accessed parameters, and employs specialized techniques to manage nondeterminism that arises from random sampling. In our experimental study, Lapse2 outperformed existing, single-technique PSs by up to one order of magnitude and provided near-linear scalability across multiple machine learning tasks.
RDFFrames: Knowledge Graph Access for Machine Learning Tools
Feb 10, 2020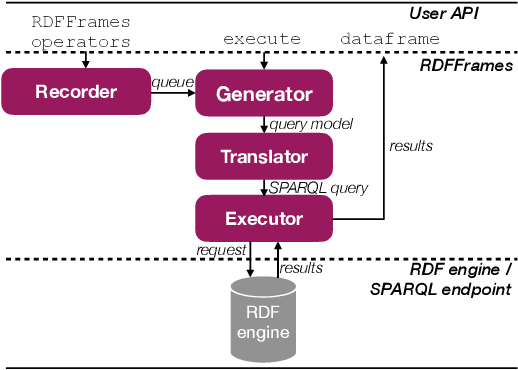

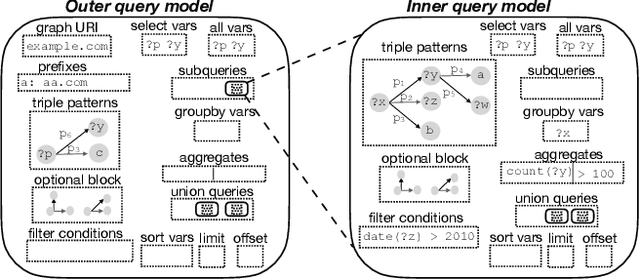
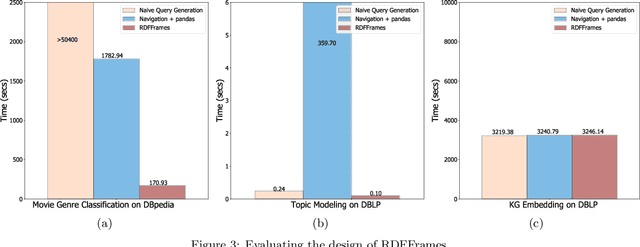
Knowledge graphs represented as RDF datasets are becoming increasingly popular, and they are an integral part of many machine learning applications. A rich ecosystem of data management systems and tools that support RDF has evolved over the years to facilitate high performance storage and retrieval of RDF data, most notably RDF database management systems that support the SPARQL query language. Surprisingly, machine learning tools for knowledge graphs typically do not use SPARQL, despite the obvious advantages of using a database system. This is due to the mismatch between SPARQL and machine learning tools in terms of the expected data model and the programming style. Machine learning tools work on data in tabular format and process it using an imperative programming style, while SPARQL is declarative and has as the basic query operation matching graph patterns to RDF triples. We posit that a good interface to knowledge graphs from a machine learning software stack should use an imperative, navigational programming paradigm based on graph traversal rather than the SPARQL query paradigm based on graph patterns. In this paper, we introduce RDFFrames, a framework that provides such an interface. RDFFrames enables the user to make a sequence of calls in a programming language such as Python to define the data to be extracted from a knowledge graph stored in an RDF database system. It then translates these calls into compact SPQARL queries, executes these queries on the database system, and returns the results in a standard tabular format. Thus, RDFframes combines the usability of a machine learning software stack with the performance of an RDF database system.
Agora: Towards An Open Ecosystem for Democratizing Data Science & Artificial Intelligence
Sep 06, 2019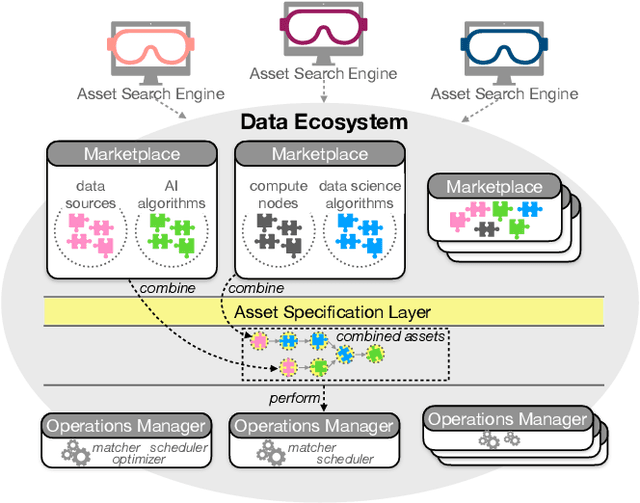
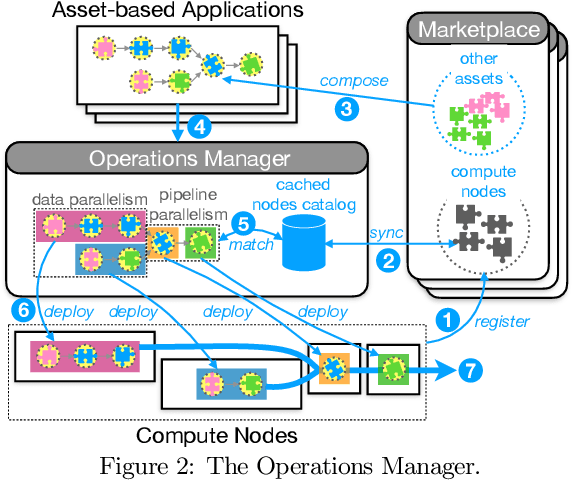
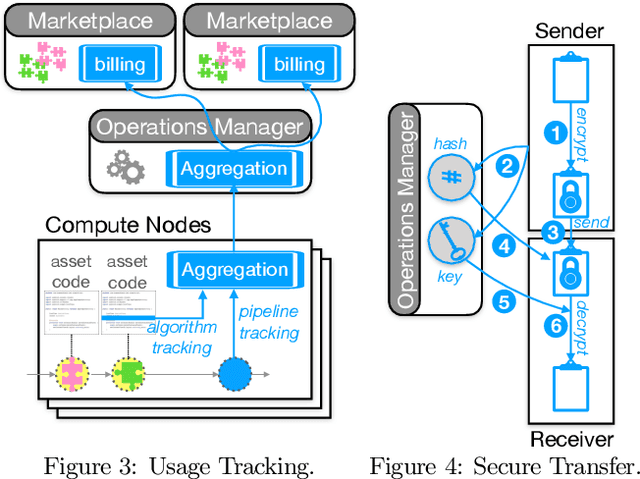
Data science and artificial intelligence are driven by a plethora of diverse data-related assets including datasets, data streams, algorithms, processing software, compute resources, and domain knowledge. As providing all these assets requires a huge investment, data sciences and artificial intelligence are currently dominated by a small number of providers who can afford these investments. In this paper, we present a vision of a data ecosystem to democratize data science and artificial intelligence. In particular, we envision a data infrastructure for fine-grained asset exchange in combination with scalable systems operation. This will overcome lock-in effects and remove entry barriers for new asset providers. Our goal is to enable companies, research organizations, and individuals to have equal access to data, data science, and artificial intelligence. Such an open ecosystem has recently been put on the agenda of several governments and industrial associations. We point out the requirements and the research challenges as well as outline an initial data infrastructure architecture for building such a data ecosystem.
AI-CARGO: A Data-Driven Air-Cargo Revenue Management System
May 22, 2019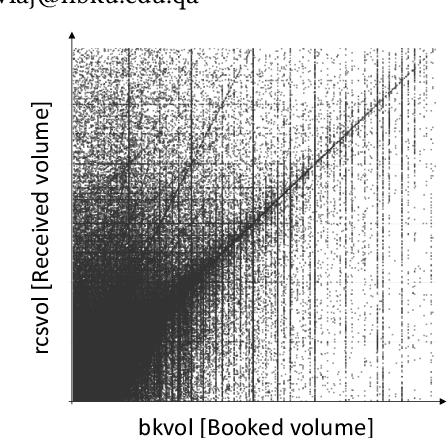
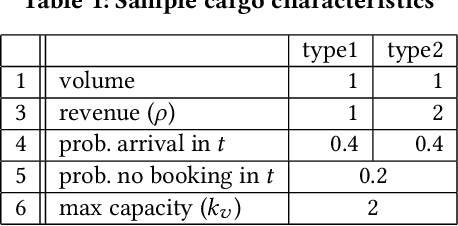
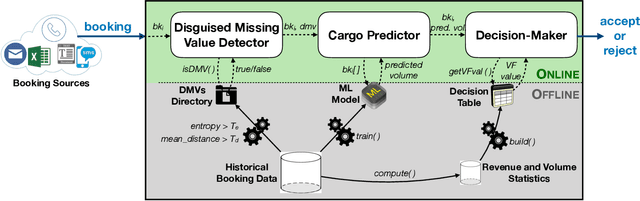
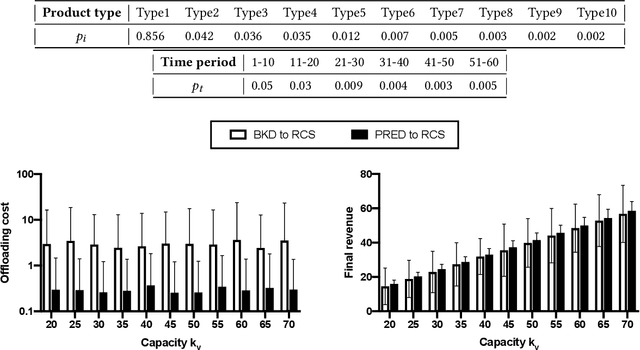
We propose AI-CARGO, a revenue management system for air-cargo that combines machine learning prediction with decision-making using mathematical optimization methods. AI-CARGO addresses a problem that is unique to the air-cargo business, namely the wide discrepancy between the quantity (weight or volume) that a shipper will book and the actual received amount at departure time by the airline. The discrepancy results in sub-optimal and inefficient behavior by both the shipper and the airline resulting in the overall loss of potential revenue for the airline. AI-CARGO also includes a data cleaning component to deal with the heterogeneous forms in which booking data is transmitted to the airline cargo system. AI-CARGO is deployed in the production environment of a large commercial airline company. We have validated the benefits of AI-CARGO using real and synthetic datasets. Especially, we have carried out simulations using dynamic programming techniques to elicit the impact on offloading costs and revenue generation of our proposed system. Our results suggest that combining prediction within a decision-making framework can help dramatically to reduce offloading costs and optimize revenue generation.