 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFanar 2.0: Arabic Generative AI Stack
Mar 17, 2026We present Fanar 2.0, the second generation of Qatar's Arabic-centric Generative AI platform. Sovereignty is a first-class design principle: every component, from data pipelines to deployment infrastructure, was designed and operated entirely at QCRI, Hamad Bin Khalifa University. Fanar 2.0 is a story of resource-constrained excellence: the effort ran on 256 NVIDIA H100 GPUs, with Arabic having only ~0.5% of web data despite 400 million native speakers. Fanar 2.0 adopts a disciplined strategy of data quality over quantity, targeted continual pre-training, and model merging to achieve substantial gains within these constraints. At the core is Fanar-27B, continually pre-trained from a Gemma-3-27B backbone on a curated corpus of 120 billion high-quality tokens across three data recipes. Despite using 8x fewer pre-training tokens than Fanar 1.0, it delivers substantial benchmark improvements: Arabic knowledge (+9.1 pts), language (+7.3 pts), dialects (+3.5 pts), and English capability (+7.6 pts). Beyond the core LLM, Fanar 2.0 introduces a rich stack of new capabilities. FanarGuard is a state-of-the-art 4B bilingual moderation filter for Arabic safety and cultural alignment. The speech family Aura gains a long-form ASR model for hours-long audio. Oryx vision family adds Arabic-aware image and video understanding alongside culturally grounded image generation. An agentic tool-calling framework enables multi-step workflows. Fanar-Sadiq utilizes a multi-agent architecture for Islamic content. Fanar-Diwan provides classical Arabic poetry generation. FanarShaheen delivers LLM-powered bilingual translation. A redesigned multi-layer orchestrator coordinates all components through intent-aware routing and defense-in-depth safety validation. Taken together, Fanar 2.0 demonstrates that sovereign, resource-constrained AI development can produce systems competitive with those built at far greater scale.
Can LLMs Detect Their Confabulations? Estimating Reliability in Uncertainty-Aware Language Models
Aug 11, 2025



Large Language Models (LLMs) are prone to generating fluent but incorrect content, known as confabulation, which poses increasing risks in multi-turn or agentic applications where outputs may be reused as context. In this work, we investigate how in-context information influences model behavior and whether LLMs can identify their unreliable responses. We propose a reliability estimation that leverages token-level uncertainty to guide the aggregation of internal model representations. Specifically, we compute aleatoric and epistemic uncertainty from output logits to identify salient tokens and aggregate their hidden states into compact representations for response-level reliability prediction. Through controlled experiments on open QA benchmarks, we find that correct in-context information improves both answer accuracy and model confidence, while misleading context often induces confidently incorrect responses, revealing a misalignment between uncertainty and correctness. Our probing-based method captures these shifts in model behavior and improves the detection of unreliable outputs across multiple open-source LLMs. These results underscore the limitations of direct uncertainty signals and highlight the potential of uncertainty-guided probing for reliability-aware generation.
Solving Normalized Cut Problem with Constrained Action Space
May 20, 2025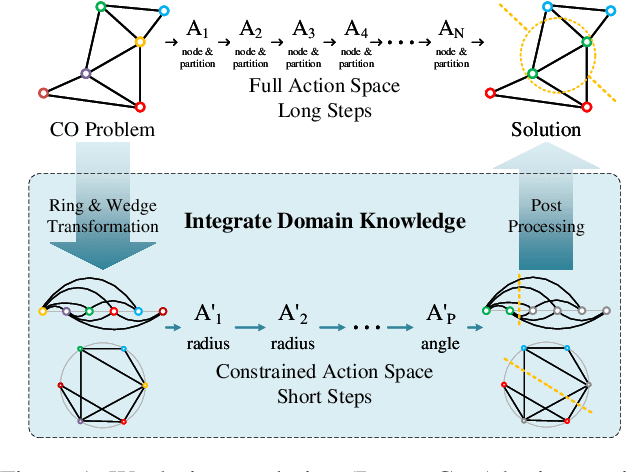
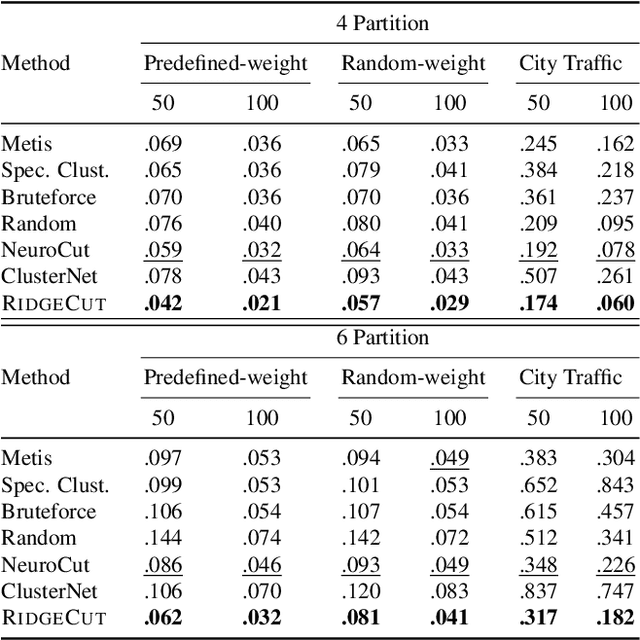
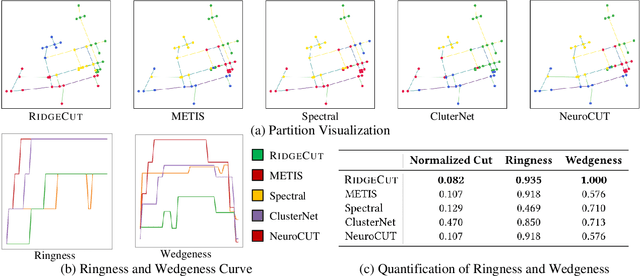
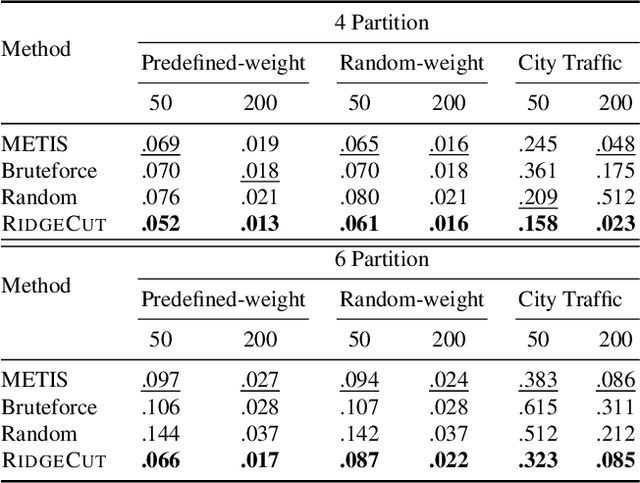
Reinforcement Learning (RL) has emerged as an important paradigm to solve combinatorial optimization problems primarily due to its ability to learn heuristics that can generalize across problem instances. However, integrating external knowledge that will steer combinatorial optimization problem solutions towards domain appropriate outcomes remains an extremely challenging task. In this paper, we propose the first RL solution that uses constrained action spaces to guide the normalized cut problem towards pre-defined template instances. Using transportation networks as an example domain, we create a Wedge and Ring Transformer that results in graph partitions that are shaped in form of Wedges and Rings and which are likely to be closer to natural optimal partitions. However, our approach is general as it is based on principles that can be generalized to other domains.
aiXamine: Simplified LLM Safety and Security
Apr 23, 2025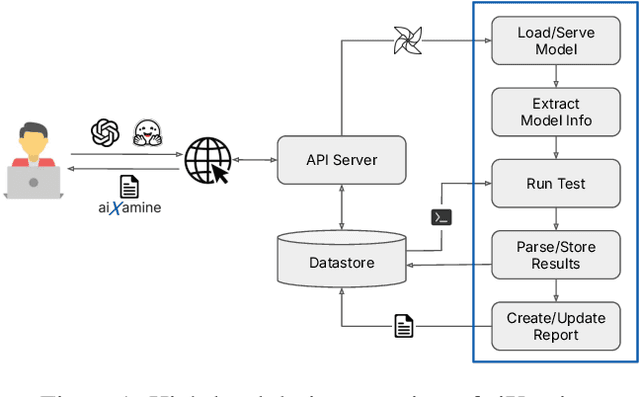



Evaluating Large Language Models (LLMs) for safety and security remains a complex task, often requiring users to navigate a fragmented landscape of ad hoc benchmarks, datasets, metrics, and reporting formats. To address this challenge, we present aiXamine, a comprehensive black-box evaluation platform for LLM safety and security. aiXamine integrates over 40 tests (i.e., benchmarks) organized into eight key services targeting specific dimensions of safety and security: adversarial robustness, code security, fairness and bias, hallucination, model and data privacy, out-of-distribution (OOD) robustness, over-refusal, and safety alignment. The platform aggregates the evaluation results into a single detailed report per model, providing a detailed breakdown of model performance, test examples, and rich visualizations. We used aiXamine to assess over 50 publicly available and proprietary LLMs, conducting over 2K examinations. Our findings reveal notable vulnerabilities in leading models, including susceptibility to adversarial attacks in OpenAI's GPT-4o, biased outputs in xAI's Grok-3, and privacy weaknesses in Google's Gemini 2.0. Additionally, we observe that open-source models can match or exceed proprietary models in specific services such as safety alignment, fairness and bias, and OOD robustness. Finally, we identify trade-offs between distillation strategies, model size, training methods, and architectural choices.
aiXamine: LLM Safety and Security Simplified
Apr 21, 2025Evaluating Large Language Models (LLMs) for safety and security remains a complex task, often requiring users to navigate a fragmented landscape of ad hoc benchmarks, datasets, metrics, and reporting formats. To address this challenge, we present aiXamine, a comprehensive black-box evaluation platform for LLM safety and security. aiXamine integrates over 40 tests (i.e., benchmarks) organized into eight key services targeting specific dimensions of safety and security: adversarial robustness, code security, fairness and bias, hallucination, model and data privacy, out-of-distribution (OOD) robustness, over-refusal, and safety alignment. The platform aggregates the evaluation results into a single detailed report per model, providing a detailed breakdown of model performance, test examples, and rich visualizations. We used aiXamine to assess over 50 publicly available and proprietary LLMs, conducting over 2K examinations. Our findings reveal notable vulnerabilities in leading models, including susceptibility to adversarial attacks in OpenAI's GPT-4o, biased outputs in xAI's Grok-3, and privacy weaknesses in Google's Gemini 2.0. Additionally, we observe that open-source models can match or exceed proprietary models in specific services such as safety alignment, fairness and bias, and OOD robustness. Finally, we identify trade-offs between distillation strategies, model size, training methods, and architectural choices.
DeBackdoor: A Deductive Framework for Detecting Backdoor Attacks on Deep Models with Limited Data
Mar 27, 2025


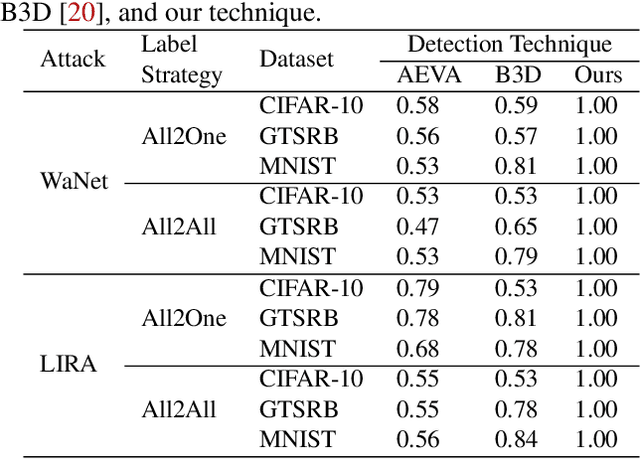
Backdoor attacks are among the most effective, practical, and stealthy attacks in deep learning. In this paper, we consider a practical scenario where a developer obtains a deep model from a third party and uses it as part of a safety-critical system. The developer wants to inspect the model for potential backdoors prior to system deployment. We find that most existing detection techniques make assumptions that are not applicable to this scenario. In this paper, we present a novel framework for detecting backdoors under realistic restrictions. We generate candidate triggers by deductively searching over the space of possible triggers. We construct and optimize a smoothed version of Attack Success Rate as our search objective. Starting from a broad class of template attacks and just using the forward pass of a deep model, we reverse engineer the backdoor attack. We conduct extensive evaluation on a wide range of attacks, models, and datasets, with our technique performing almost perfectly across these settings.
A Perspective on Symbolic Machine Learning in Physical Sciences
Feb 25, 2025


Machine learning is rapidly making its pathway across all of the natural sciences, including physical sciences. The rate at which ML is impacting non-scientific disciplines is incomparable to that in the physical sciences. This is partly due to the uninterpretable nature of deep neural networks. Symbolic machine learning stands as an equal and complementary partner to numerical machine learning in speeding up scientific discovery in physics. This perspective discusses the main differences between the ML and scientific approaches. It stresses the need to develop and apply symbolic machine learning to physics problems equally, in parallel to numerical machine learning, because of the dual nature of physics research.
Inferring Interpretable Models of Fragmentation Functions using Symbolic Regression
Jan 13, 2025Machine learning is rapidly making its path into natural sciences, including high-energy physics. We present the first study that infers, directly from experimental data, a functional form of fragmentation functions. The latter represent a key ingredient to describe physical observables measured in high-energy physics processes that involve hadron production, and predict their values at different energy. Fragmentation functions can not be calculated in theory and have to be determined instead from data. Traditional approaches rely on global fits of experimental data using a pre-assumed functional form inspired from phenomenological models to learn its parameters. This novel approach uses a ML technique, namely symbolic regression, to learn an analytical model from measured charged hadron multiplicities. The function learned by symbolic regression resembles the Lund string function and describes the data well, thus representing a potential candidate for use in global FFs fits. This study represents an approach to follow in such QCD-related phenomenology studies and more generally in sciences.
Exploiting the Layered Intrinsic Dimensionality of Deep Models for Practical Adversarial Training
May 27, 2024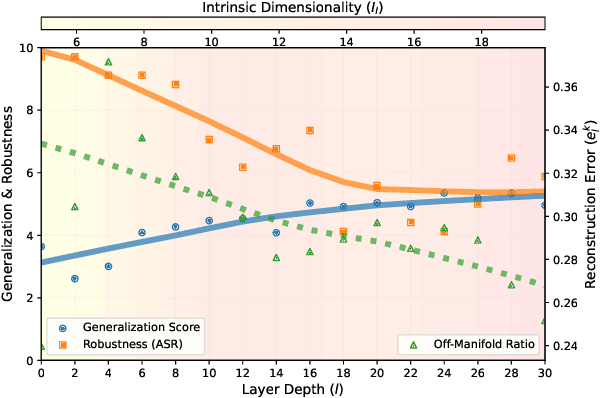



Despite being a heavily researched topic, Adversarial Training (AT) is rarely, if ever, deployed in practical AI systems for two primary reasons: (i) the gained robustness is frequently accompanied by a drop in generalization and (ii) generating adversarial examples (AEs) is computationally prohibitively expensive. To address these limitations, we propose SMAAT, a new AT algorithm that leverages the manifold conjecture, stating that off-manifold AEs lead to better robustness while on-manifold AEs result in better generalization. Specifically, SMAAT aims at generating a higher proportion of off-manifold AEs by perturbing the intermediate deepnet layer with the lowest intrinsic dimension. This systematically results in better scalability compared to classical AT as it reduces the PGD chains length required for generating the AEs. Additionally, our study provides, to the best of our knowledge, the first explanation for the difference in the generalization and robustness trends between vision and language models, ie., AT results in a drop in generalization in vision models whereas, in encoder-based language models, generalization either improves or remains unchanged. We show that vision transformers and decoder-based models tend to have low intrinsic dimensionality in the earlier layers of the network (more off-manifold AEs), while encoder-based models have low intrinsic dimensionality in the later layers. We demonstrate the efficacy of SMAAT; on several tasks, including robustifying (i) sentiment classifiers, (ii) safety filters in decoder-based models, and (iii) retrievers in RAG setups. SMAAT requires only 25-33% of the GPU time compared to standard AT, while significantly improving robustness across all applications and maintaining comparable generalization.
S$^2$AC: Energy-Based Reinforcement Learning with Stein Soft Actor Critic
May 02, 2024Learning expressive stochastic policies instead of deterministic ones has been proposed to achieve better stability, sample complexity, and robustness. Notably, in Maximum Entropy Reinforcement Learning (MaxEnt RL), the policy is modeled as an expressive Energy-Based Model (EBM) over the Q-values. However, this formulation requires the estimation of the entropy of such EBMs, which is an open problem. To address this, previous MaxEnt RL methods either implicitly estimate the entropy, resulting in high computational complexity and variance (SQL), or follow a variational inference procedure that fits simplified actor distributions (e.g., Gaussian) for tractability (SAC). We propose Stein Soft Actor-Critic (S$^2$AC), a MaxEnt RL algorithm that learns expressive policies without compromising efficiency. Specifically, S$^2$AC uses parameterized Stein Variational Gradient Descent (SVGD) as the underlying policy. We derive a closed-form expression of the entropy of such policies. Our formula is computationally efficient and only depends on first-order derivatives and vector products. Empirical results show that S$^2$AC yields more optimal solutions to the MaxEnt objective than SQL and SAC in the multi-goal environment, and outperforms SAC and SQL on the MuJoCo benchmark. Our code is available at: https://github.com/SafaMessaoud/S2AC-Energy-Based-RL-with-Stein-Soft-Actor-Critic