 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distribution Data: An Acquaintance of Adversarial Examples -- A Survey
Apr 08, 2024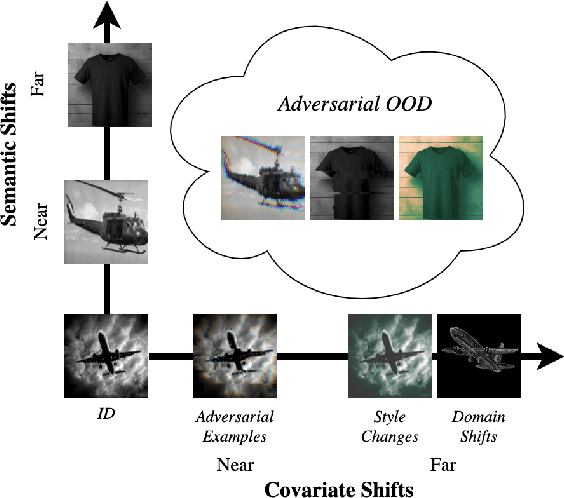
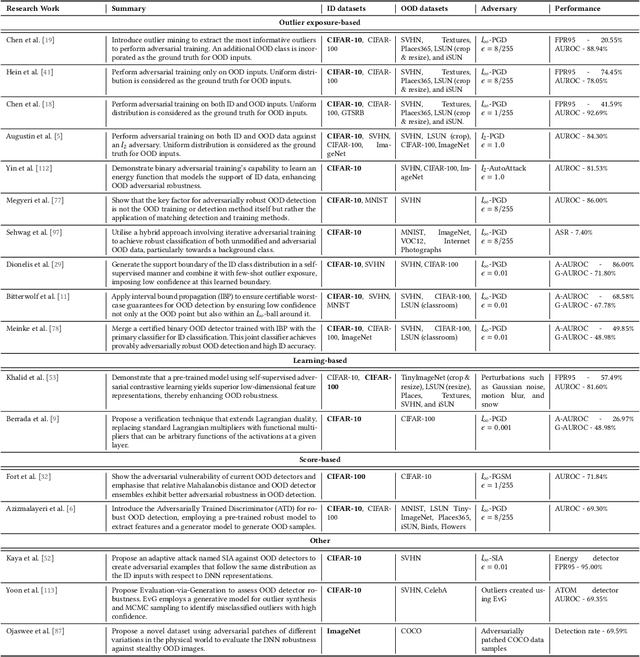
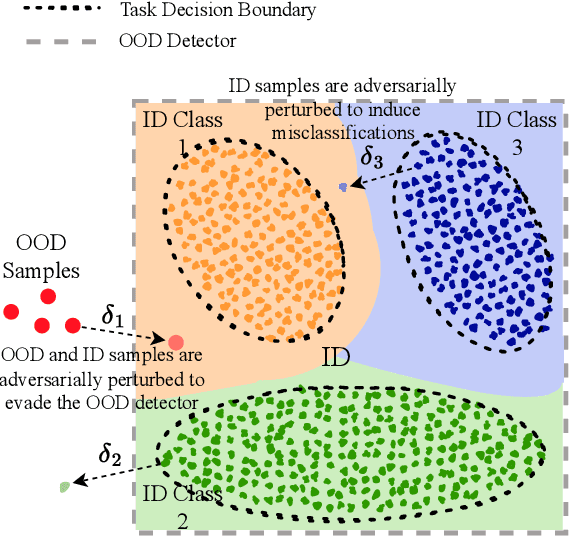
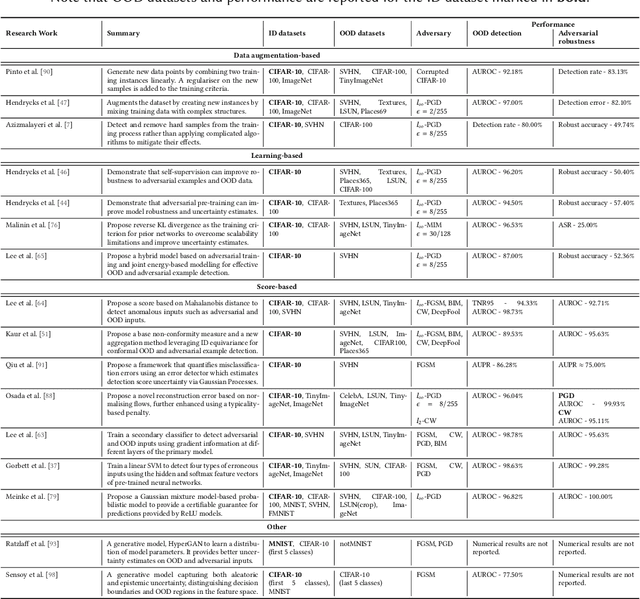
Deep neural networks (DNNs) deployed in real-world applications can encounter out-of-distribution (OOD) data and adversarial examples. These represent distinct forms of distributional shifts that can significantly impact DNNs' reliability and robustness. Traditionally, research has addressed OOD detection and adversarial robustness as separate challenges. This survey focuses on the intersection of these two areas, examining how the research community has investigated them together. Consequently, we identify two key research directions: robust OOD detection and unified robustness. Robust OOD detection aims to differentiate between in-distribution (ID) data and OOD data, even when they are adversarially manipulated to deceive the OOD detector. Unified robustness seeks a single approach to make DNNs robust against both adversarial attacks and OOD inputs. Accordingly, first, we establish a taxonomy based on the concept of distributional shifts. This framework clarifies how robust OOD detection and unified robustness relate to other research areas addressing distributional shifts, such as OOD detection, open set recognition, and anomaly detection. Subsequently, we review existing work on robust OOD detection and unified robustness. Finally, we highlight the limitations of the existing work and propose promising research directions that explore adversarial and OOD inputs within a unified framework.
ExCeL : Combined Extreme and Collective Logit Information for Enhancing Out-of-Distribution Detection
Nov 23, 2023



Deep learning models often exhibit overconfidence in predicting out-of-distribution (OOD) data, underscoring the crucial role of OOD detection in ensuring reliability in predictions. Among various OOD detection approaches, post-hoc detectors have gained significant popularity, primarily due to their ease of use and implementation. However, the effectiveness of most post-hoc OOD detectors has been constrained as they rely solely either on extreme information, such as the maximum logit, or on the collective information (i.e., information spanned across classes or training samples) embedded within the output layer. In this paper, we propose ExCeL that combines both extreme and collective information within the output layer for enhanced accuracy in OOD detection. We leverage the logit of the top predicted class as the extreme information (i.e., the maximum logit), while the collective information is derived in a novel approach that involves assessing the likelihood of other classes appearing in subsequent ranks across various training samples. Our idea is motivated by the observation that, for in-distribution (ID) data, the ranking of classes beyond the predicted class is more deterministic compared to that in OOD data. Experiments conducted on CIFAR100 and ImageNet-200 datasets demonstrate that ExCeL consistently is among the five top-performing methods out of twenty-one existing post-hoc baselines when the joint performance on near-OOD and far-OOD is considered (i.e., in terms of AUROC and FPR95). Furthermore, ExCeL shows the best overall performance across both datasets, unlike other baselines that work best on one dataset but has a performance drop in the other.
Privacy-Preserving Spam Filtering using Functional Encryption
Dec 08, 2020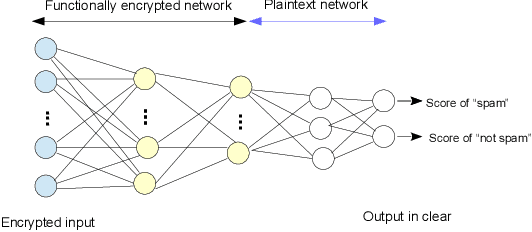
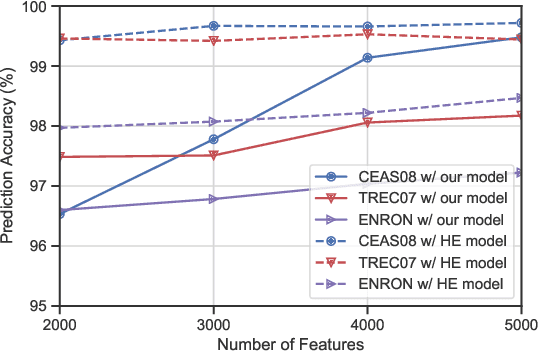
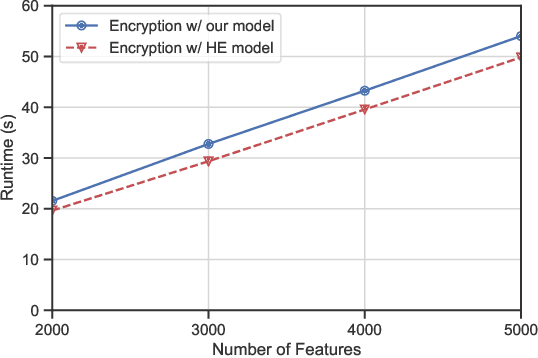
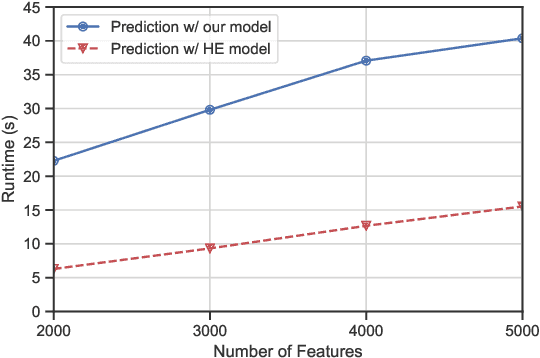
Traditional spam classification requires the end-user to reveal the content of its received email to the spam classifier which violates the privacy. Spam classification over encrypted emails enables the classifier to classify spam email without accessing the email, hence protects the privacy of email content. In this paper, we construct a spam classification framework that enables the classification of encrypted emails. Our classification model is based on a neural network with a quadratic network part and a multi-layer perception network part. The quadratic network architecture is compatible with the operation of an existing quadratic functional encryption scheme that enables our classification to predict the label of encrypted emails without revealing the associated plain-text email. The evaluation results on real-world spam datasets indicate that our proposed spam classification model achieves an accuracy of over 96%.
A Multi-modal Neural Embeddings Approach for Detecting Mobile Counterfeit Apps: A Case Study on Google Play Store
Jun 02, 2020
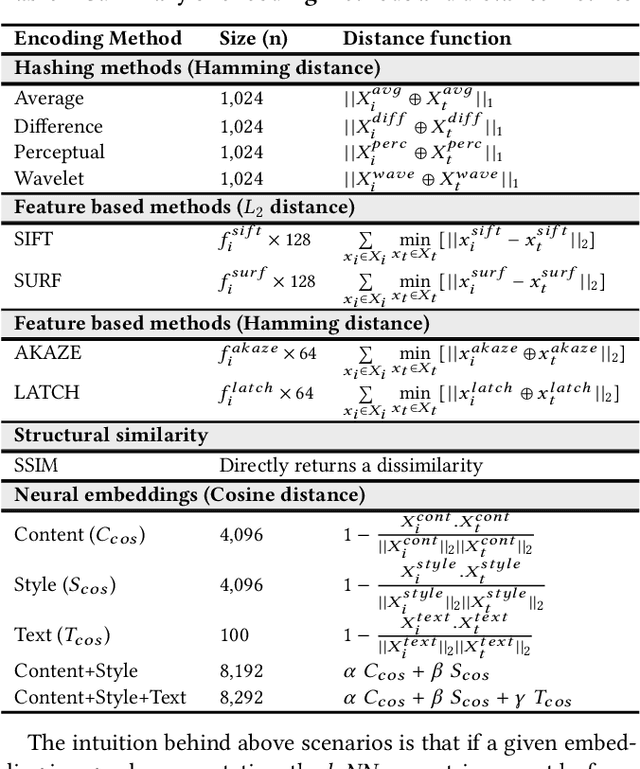
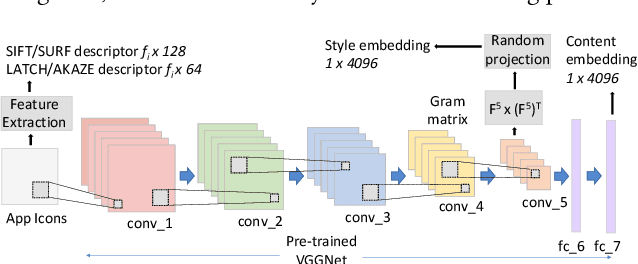
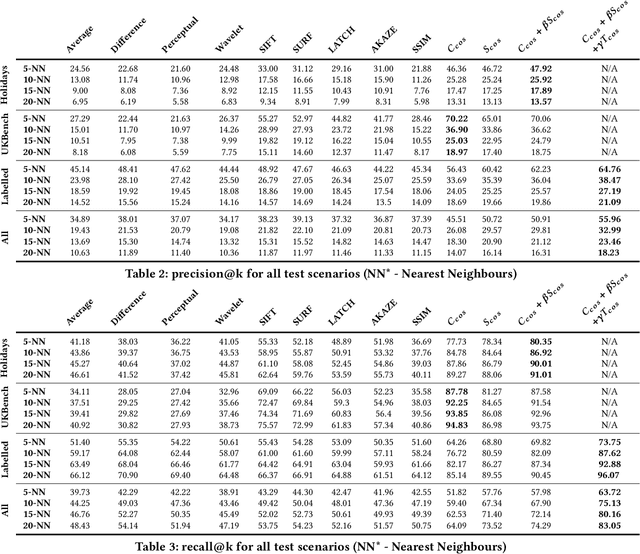
Counterfeit apps impersonate existing popular apps in attempts to misguide users to install them for various reasons such as collecting personal information or spreading malware. Many counterfeits can be identified once installed, however even a tech-savvy user may struggle to detect them before installation. To this end, this paper proposes to leverage the recent advances in deep learning methods to create image and text embeddings so that counterfeit apps can be efficiently identified when they are submitted for publication. We show that a novel approach of combining content embeddings and style embeddings outperforms the baseline methods for image similarity such as SIFT, SURF, and various image hashing methods. We first evaluate the performance of the proposed method on two well-known datasets for evaluating image similarity methods and show that content, style, and combined embeddings increase precision@k and recall@k by 10%-15% and 12%-25%, respectively when retrieving five nearest neighbours. Second, specifically for the app counterfeit detection problem, combined content and style embeddings achieve 12% and 14% increase in precision@k and recall@k, respectively compared to the baseline methods. Third, we present an analysis of approximately 1.2 million apps from Google Play Store and identify a set of potential counterfeits for top-10,000 popular apps. Under a conservative assumption, we were able to find 2,040 potential counterfeits that contain malware in a set of 49,608 apps that showed high similarity to one of the top-10,000 popular apps in Google Play Store. We also find 1,565 potential counterfeits asking for at least five additional dangerous permissions than the original app and 1,407 potential counterfeits having at least five extra third party advertisement libraries.