 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEMO-4-PAYPAL: Leveraging NVIDIA's Nemo Framework for empowering PayPal's Commerce Agent
Dec 25, 2025We present the development and optimization of PayPal's Commerce Agent, powered by NEMO-4-PAYPAL, a multi-agent system designed to revolutionize agentic commerce on the PayPal platform. Through our strategic partnership with NVIDIA, we leveraged the NeMo Framework for LLM model fine-tuning to enhance agent performance. Specifically, we optimized the Search and Discovery agent by replacing our base model with a fine-tuned Nemotron small language model (SLM). We conducted comprehensive experiments using the llama3.1-nemotron-nano-8B-v1 architecture, training LoRA-based models through systematic hyperparameter sweeps across learning rates, optimizers (Adam, AdamW), cosine annealing schedules, and LoRA ranks. Our contributions include: (1) the first application of NVIDIA's NeMo Framework to commerce-specific agent optimization, (2) LLM powered fine-tuning strategy for retrieval-focused commerce tasks, (3) demonstration of significant improvements in latency and cost while maintaining agent quality, and (4) a scalable framework for multi-agent system optimization in production e-commerce environments. Our results demonstrate that the fine-tuned Nemotron SLM effectively resolves the key performance issue in the retrieval component, which represents over 50\% of total agent response time, while maintaining or enhancing overall system performance.
Solving Normalized Cut Problem with Constrained Action Space
May 20, 2025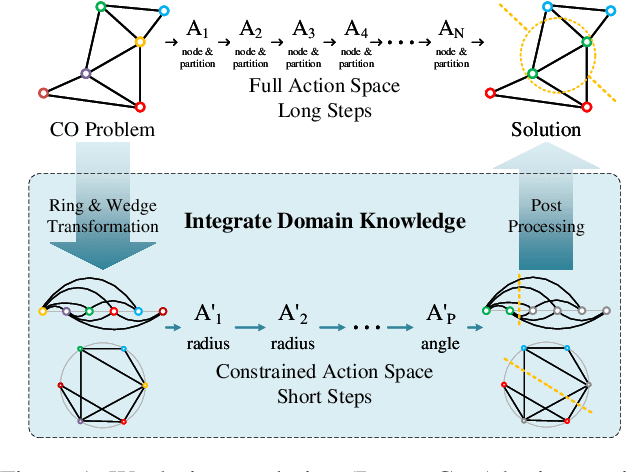
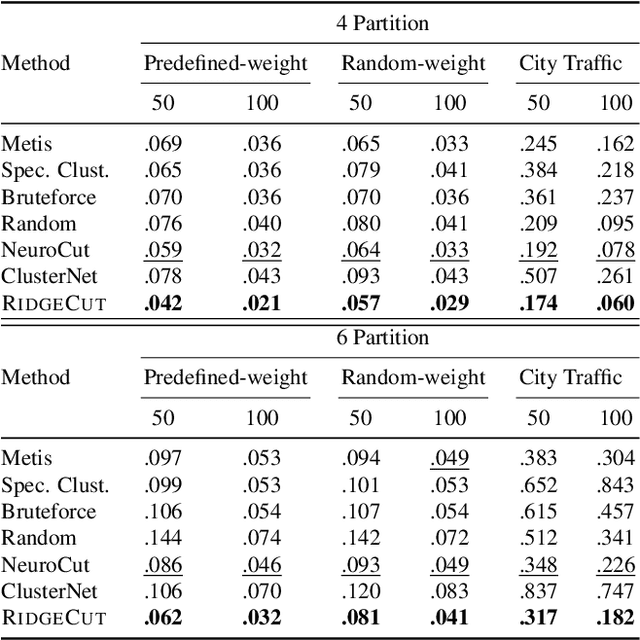
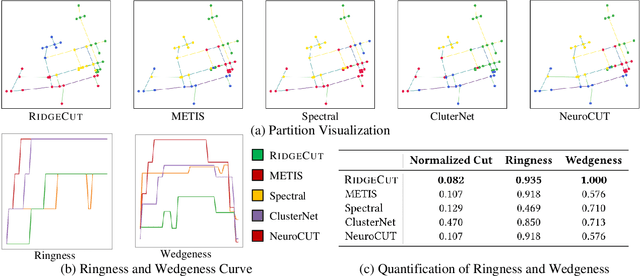
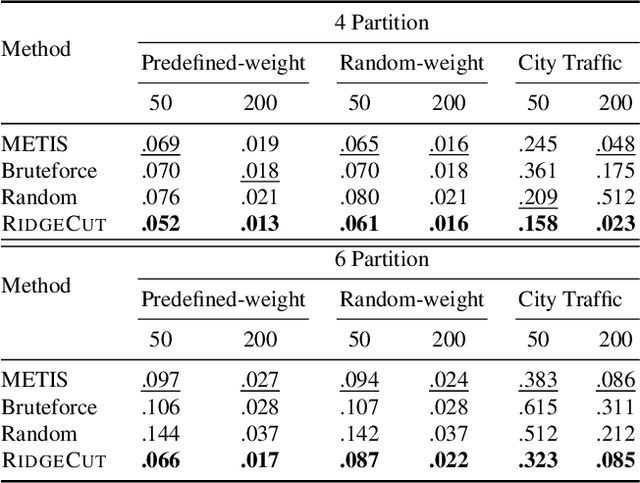
Reinforcement Learning (RL) has emerged as an important paradigm to solve combinatorial optimization problems primarily due to its ability to learn heuristics that can generalize across problem instances. However, integrating external knowledge that will steer combinatorial optimization problem solutions towards domain appropriate outcomes remains an extremely challenging task. In this paper, we propose the first RL solution that uses constrained action spaces to guide the normalized cut problem towards pre-defined template instances. Using transportation networks as an example domain, we create a Wedge and Ring Transformer that results in graph partitions that are shaped in form of Wedges and Rings and which are likely to be closer to natural optimal partitions. However, our approach is general as it is based on principles that can be generalized to other domains.
Automating Personalization: Prompt Optimization for Recommendation Reranking
Apr 04, 2025Modern recommender systems increasingly leverage large language models (LLMs) for reranking to improve personalization. However, existing approaches face two key limitations: (1) heavy reliance on manually crafted prompts that are difficult to scale, and (2) inadequate handling of unstructured item metadata that complicates preference inference. We present AGP (Auto-Guided Prompt Refinement), a novel framework that automatically optimizes user profile generation prompts for personalized reranking. AGP introduces two key innovations: (1) position-aware feedback mechanisms for precise ranking correction, and (2) batched training with aggregated feedback to enhance generalization.
CoMAL: Collaborative Multi-Agent Large Language Models for Mixed-Autonomy Traffic
Oct 18, 2024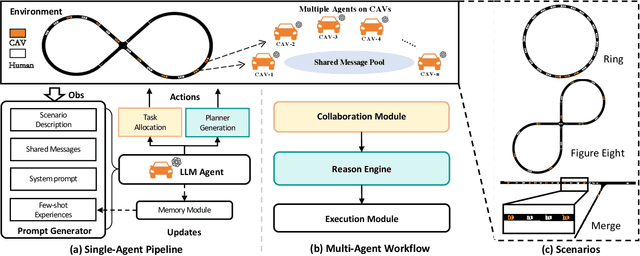
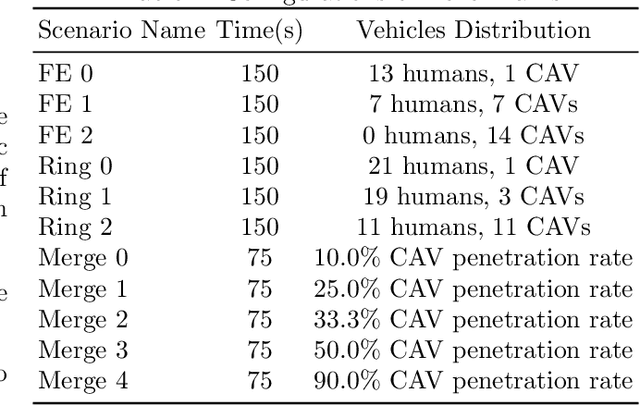

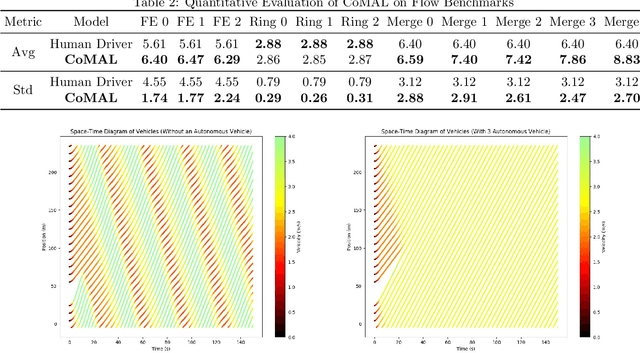
The integration of autonomous vehicles into urban traffic has great potential to improve efficiency by reducing congestion and optimizing traffic flow systematically. In this paper, we introduce CoMAL (Collaborative Multi-Agent LLMs), a framework designed to address the mixed-autonomy traffic problem by collaboration among autonomous vehicles to optimize traffic flow. CoMAL is built upon large language models, operating in an interactive traffic simulation environment. It utilizes a Perception Module to observe surrounding agents and a Memory Module to store strategies for each agent. The overall workflow includes a Collaboration Module that encourages autonomous vehicles to discuss the effective strategy and allocate roles, a reasoning engine to determine optimal behaviors based on assigned roles, and an Execution Module that controls vehicle actions using a hybrid approach combining rule-based models. Experimental results demonstrate that CoMAL achieves superior performance on the Flow benchmark. Additionally, we evaluate the impact of different language models and compare our framework with reinforcement learning approaches. It highlights the strong cooperative capability of LLM agents and presents a promising solution to the mixed-autonomy traffic challenge. The code is available at https://github.com/Hyan-Yao/CoMAL.
Sequential Recommendation via Adaptive Robust Attention with Multi-dimensional Embeddings
Sep 08, 2024



Sequential recommendation models have achieved state-of-the-art performance using self-attention mechanism. It has since been found that moving beyond only using item ID and positional embeddings leads to a significant accuracy boost when predicting the next item. In recent literature, it was reported that a multi-dimensional kernel embedding with temporal contextual kernels to capture users' diverse behavioral patterns results in a substantial performance improvement. In this study, we further improve the sequential recommender model's robustness and generalization by introducing a mix-attention mechanism with a layer-wise noise injection (LNI) regularization. We refer to our proposed model as adaptive robust sequential recommendation framework (ADRRec), and demonstrate through extensive experiments that our model outperforms existing self-attention architectures.
S$^2$AC: Energy-Based Reinforcement Learning with Stein Soft Actor Critic
May 02, 2024Learning expressive stochastic policies instead of deterministic ones has been proposed to achieve better stability, sample complexity, and robustness. Notably, in Maximum Entropy Reinforcement Learning (MaxEnt RL), the policy is modeled as an expressive Energy-Based Model (EBM) over the Q-values. However, this formulation requires the estimation of the entropy of such EBMs, which is an open problem. To address this, previous MaxEnt RL methods either implicitly estimate the entropy, resulting in high computational complexity and variance (SQL), or follow a variational inference procedure that fits simplified actor distributions (e.g., Gaussian) for tractability (SAC). We propose Stein Soft Actor-Critic (S$^2$AC), a MaxEnt RL algorithm that learns expressive policies without compromising efficiency. Specifically, S$^2$AC uses parameterized Stein Variational Gradient Descent (SVGD) as the underlying policy. We derive a closed-form expression of the entropy of such policies. Our formula is computationally efficient and only depends on first-order derivatives and vector products. Empirical results show that S$^2$AC yields more optimal solutions to the MaxEnt objective than SQL and SAC in the multi-goal environment, and outperforms SAC and SQL on the MuJoCo benchmark. Our code is available at: https://github.com/SafaMessaoud/S2AC-Energy-Based-RL-with-Stein-Soft-Actor-Critic
Are Classification Robustness and Explanation Robustness Really Strongly Correlated? An Analysis Through Input Loss Landscape
Mar 09, 2024This paper delves into the critical area of deep learning robustness, challenging the conventional belief that classification robustness and explanation robustness in image classification systems are inherently correlated. Through a novel evaluation approach leveraging clustering for efficient assessment of explanation robustness, we demonstrate that enhancing explanation robustness does not necessarily flatten the input loss landscape with respect to explanation loss - contrary to flattened loss landscapes indicating better classification robustness. To deeply investigate this contradiction, a groundbreaking training method designed to adjust the loss landscape with respect to explanation loss is proposed. Through the new training method, we uncover that although such adjustments can impact the robustness of explanations, they do not have an influence on the robustness of classification. These findings not only challenge the prevailing assumption of a strong correlation between the two forms of robustness but also pave new pathways for understanding relationship between loss landscape and explanation loss.
Probabilistic Outlier Detection and Generation
Dec 22, 2020



A new method for outlier detection and generation is introduced by lifting data into the space of probability distributions which are not analytically expressible, but from which samples can be drawn using a neural generator. Given a mixture of unknown latent inlier and outlier distributions, a Wasserstein double autoencoder is used to both detect and generate inliers and outliers. The proposed method, named WALDO (Wasserstein Autoencoder for Learning the Distribution of Outliers), is evaluated on classical data sets including MNIST, CIFAR10 and KDD99 for detection accuracy and robustness. We give an example of outlier detection on a real retail sales data set and an example of outlier generation for simulating intrusion attacks. However we foresee many application scenarios where WALDO can be used. To the best of our knowledge this is the first work that studies both outlier detection and generation together.
Integer Programming Relaxations for Integrated Clustering and Outlier Detection
Mar 06, 2014



In this paper we present methods for exemplar based clustering with outlier selection based on the facility location formulation. Given a distance function and the number of outliers to be found, the methods automatically determine the number of clusters and outliers. We formulate the problem as an integer program to which we present relaxations that allow for solutions that scale to large data sets. The advantages of combining clustering and outlier selection include: (i) the resulting clusters tend to be compact and semantically coherent (ii) the clusters are more robust against data perturbations and (iii) the outliers are contextualised by the clusters and more interpretable, i.e. it is easier to distinguish between outliers which are the result of data errors from those that may be indicative of a new pattern emergent in the data. We present and contrast three relaxations to the integer program formulation: (i) a linear programming formulation (LP) (ii) an extension of affinity propagation to outlier detection (APOC) and (iii) a Lagrangian duality based formulation (LD). Evaluation on synthetic as well as real data shows the quality and scalability of these different methods.