 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deployment Audit of Release-Side Risk in Conformal Triage under Prevalence Shift
May 20, 2026Conformal triage converts predictive scores into deployment actions that either release a case, flag it for urgent attention, or defer it to human review. Under prevalence shift, however, the usual summaries of marginal coverage and human-review rate can miss the safety-critical question of whether patients who truly experience the target event are released without review. To address this gap, we introduce a leakage-aware deployment audit for release-side conformal triage. It first assigns target subjects to three non-overlapping roles: prevalence correction, conformal calibration, and held-out release-safety evaluation. This separation then lets the audit evaluate release directly: how many event-positive patients are cleared without review, whether the pilot has enough event labels for calibration, and how the safety-review trade-off shifts. Applying this audit to a retrospective NSCLC pilot shows why lower review can be misleading: after prevalence correction, the pooled conformal branch lowers review by releasing more patients, some of whom are event-positive. Within the audit, the classwise branch acts as a scarcity diagnostic: the pilot has too few event labels to certify safe low-review release.
FORTIS: Benchmarking Over-Privilege in Agent Skills
May 09, 2026Large language model agents increasingly operate through an intermediate skill layer that mediates between user intent and concrete task execution. This layer is widely treated as an organizational abstraction, but we argue it is also a privilege boundary that current models routinely exceed. We present \textbf{FORTIS}, a benchmark that evaluates over-privilege in agent skills across two stages: whether a model selects the minimally sufficient skill from a large overlapping library, and whether it executes that skill without expanding into broader tools or actions than the skill permits. Across ten frontier models and three domains, we find that over-privileged behavior is the norm rather than the exception. Models consistently reach for higher-privilege skills and tools than the task requires, failing at both stages at rates that remain high even for the strongest available models. Failure is especially severe under the ordinary conditions of real user interaction: incomplete specification, convenience framing, and proximity to skill boundaries. None of these requires adversarial construction. The results indicate that the skill layer, far from containing agent behavior, is itself a primary source of privilege escalation in current systems.
Heterophily-Agnostic Hypergraph Neural Networks with Riemannian Local Exchanger
Feb 28, 2026Hypergraphs are the natural description of higher-order interactions among objects, widely applied in social network analysis, cross-modal retrieval, etc. Hypergraph Neural Networks (HGNNs) have become the dominant solution for learning on hypergraphs. Traditional HGNNs are extended from message passing graph neural networks, following the homophily assumption, and thus struggle with the prevalent heterophilic hypergraphs that call for long-range dependence modeling. In this paper, we achieve heterophily-agnostic message passing through the lens of Riemannian geometry. The key insight lies in the connection between oversquashing and hypergraph bottleneck within the framework of Riemannian manifold heat flow. Building on this, we propose the novel idea of locally adapting the bottlenecks of different subhypergraphs. The core innovation of the proposed mechanism is the design of an adaptive local (heat) exchanger. Specifically, it captures the rich long-range dependencies via the Robin condition, and preserves the representation distinguishability via source terms, thereby enabling heterophily-agnostic message passing with theoretical guarantees. Based on this theoretical foundation, we present a novel Heat-Exchanger with Adaptive Locality for Hypergraph Neural Network (HealHGNN), designed as a node-hyperedge bidirectional systems with linear complexity in the number of nodes and hyperedges. Extensive experiments on both homophilic and heterophilic cases show that HealHGNN achieves the state-of-the-art performance.
BTTackler: A Diagnosis-based Framework for Efficient Deep Learning Hyperparameter Optimization
Feb 27, 2026Hyperparameter optimization (HPO) is known to be costly in deep learning, especially when leveraging automated approaches. Most of the existing automated HPO methods are accuracy-based, i.e., accuracy metrics are used to guide the trials of different hyperparameter configurations amongst a specific search space. However, many trials may encounter severe training problems, such as vanishing gradients and insufficient convergence, which can hardly be reflected by accuracy metrics in the early stages of the training and often result in poor performance. This leads to an inefficient optimization trajectory because the bad trials occupy considerable computation resources and reduce the probability of finding excellent hyperparameter configurations within a time limitation. In this paper, we propose \textbf{Bad Trial Tackler (BTTackler)}, a novel HPO framework that introduces training diagnosis to identify training problems automatically and hence tackles bad trials. BTTackler diagnoses each trial by calculating a set of carefully designed quantified indicators and triggers early termination if any training problems are detected. Evaluations are performed on representative HPO tasks consisting of three classical deep neural networks (DNN) and four widely used HPO methods. To better quantify the effectiveness of an automated HPO method, we propose two new measurements based on accuracy and time consumption. Results show the advantage of BTTackler on two-fold: (1) it reduces 40.33\% of time consumption to achieve the same accuracy comparable to baseline methods on average and (2) it conducts 44.5\% more top-10 trials than baseline methods on average within a given time budget. We also released an open-source Python library that allows users to easily apply BTTackler to automated HPO processes with minimal code changes.
ScaleFormer: Span Representation Cumulation for Long-Context Transformer
Nov 13, 2025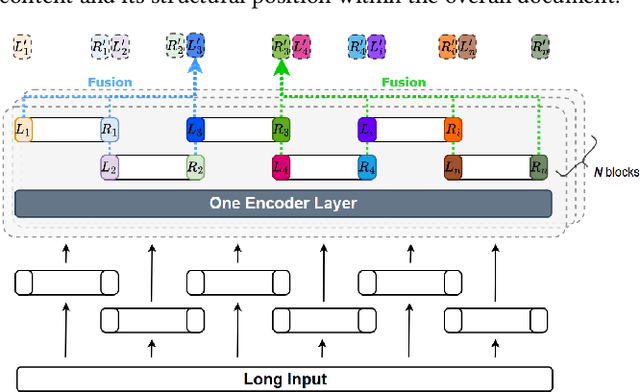


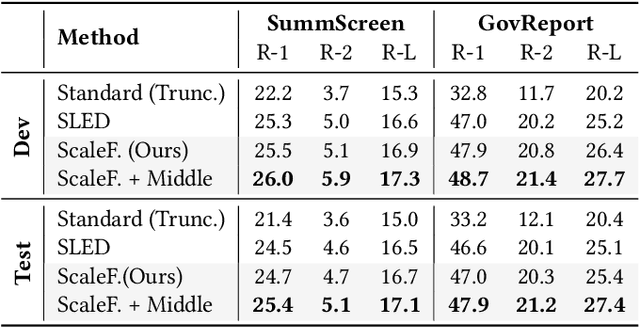
The quadratic complexity of standard self-attention severely limits the application of Transformer-based models to long-context tasks. While efficient Transformer variants exist, they often require architectural changes and costly pre-training from scratch. To circumvent this, we propose ScaleFormer(Span Representation Cumulation for Long-Context Transformer) - a simple and effective plug-and-play framework that adapts off-the-shelf pre-trained encoder-decoder models to process long sequences without requiring architectural modifications. Our approach segments long inputs into overlapping chunks and generates a compressed, context-aware representation for the decoder. The core of our method is a novel, parameter-free fusion mechanism that endows each chunk's representation with structural awareness of its position within the document. It achieves this by enriching each chunk's boundary representations with cumulative context vectors from all preceding and succeeding chunks. This strategy provides the model with a strong signal of the document's narrative flow, achieves linear complexity, and enables pre-trained models to reason effectively over long-form text. Experiments on long-document summarization show that our method is highly competitive with and often outperforms state-of-the-art approaches without requiring architectural modifications or external retrieval mechanisms.
Automating Personalization: Prompt Optimization for Recommendation Reranking
Apr 04, 2025Modern recommender systems increasingly leverage large language models (LLMs) for reranking to improve personalization. However, existing approaches face two key limitations: (1) heavy reliance on manually crafted prompts that are difficult to scale, and (2) inadequate handling of unstructured item metadata that complicates preference inference. We present AGP (Auto-Guided Prompt Refinement), a novel framework that automatically optimizes user profile generation prompts for personalized reranking. AGP introduces two key innovations: (1) position-aware feedback mechanisms for precise ranking correction, and (2) batched training with aggregated feedback to enhance generalization.
RiemannGFM: Learning a Graph Foundation Model from Riemannian Geometry
Feb 05, 2025



The foundation model has heralded a new era in artificial intelligence, pretraining a single model to offer cross-domain transferability on different datasets. Graph neural networks excel at learning graph data, the omnipresent non-Euclidean structure, but often lack the generalization capacity. Hence, graph foundation model is drawing increasing attention, and recent efforts have been made to leverage Large Language Models. On the one hand, existing studies primarily focus on text-attributed graphs, while a wider range of real graphs do not contain fruitful textual attributes. On the other hand, the sequential graph description tailored for the Large Language Model neglects the structural complexity, which is a predominant characteristic of the graph. Such limitations motivate an important question: Can we go beyond Large Language Models, and pretrain a universal model to learn the structural knowledge for any graph? The answer in the language or vision domain is a shared vocabulary. We observe the fact that there also exist shared substructures underlying graph domain, and thereby open a new opportunity of graph foundation model with structural vocabulary. The key innovation is the discovery of a simple yet effective structural vocabulary of trees and cycles, and we explore its inherent connection to Riemannian geometry. Herein, we present a universal pretraining model, RiemannGFM. Concretely, we first construct a novel product bundle to incorporate the diverse geometries of the vocabulary. Then, on this constructed space, we stack Riemannian layers where the structural vocabulary, regardless of specific graph, is learned in Riemannian manifold offering cross-domain transferability. Extensive experiments show the effectiveness of RiemannGFM on a diversity of real graphs.
Uncertainty Quantification on Graph Learning: A Survey
Apr 23, 2024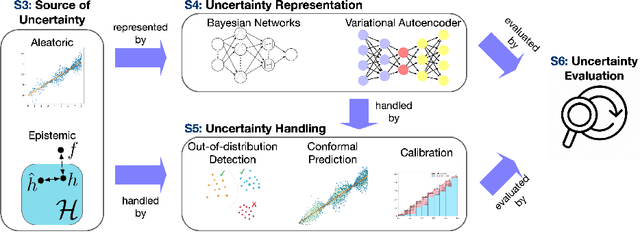
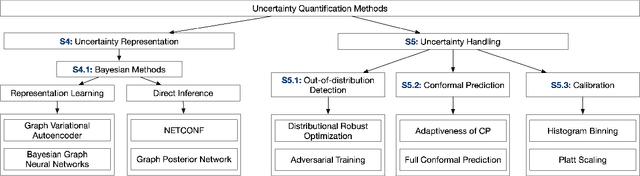
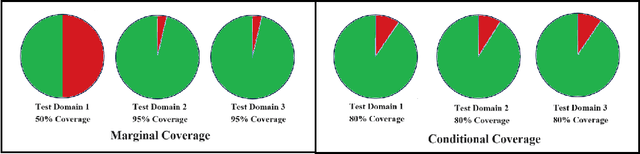
Graphical models, including Graph Neural Networks (GNNs) and Probabilistic Graphical Models (PGMs), have demonstrated their exceptional capabilities across numerous fields. These models necessitate effective uncertainty quantification to ensure reliable decision-making amid the challenges posed by model training discrepancies and unpredictable testing scenarios. This survey examines recent works that address uncertainty quantification within the model architectures, training, and inference of GNNs and PGMs. We aim to provide an overview of the current landscape of uncertainty in graphical models by organizing the recent methods into uncertainty representation and handling. By summarizing state-of-the-art methods, this survey seeks to deepen the understanding of uncertainty quantification in graphical models, thereby increasing their effectiveness and safety in critical applications.
Beyond the Known: Novel Class Discovery for Open-world Graph Learning
Mar 29, 2024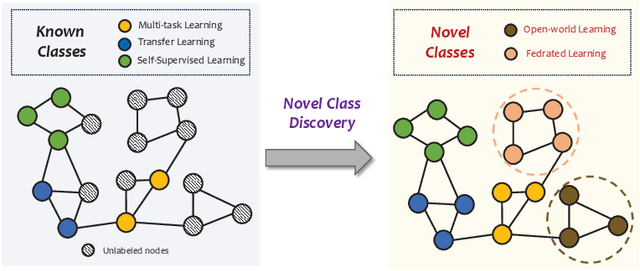
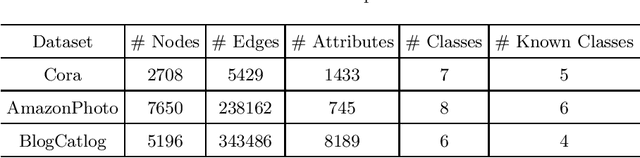
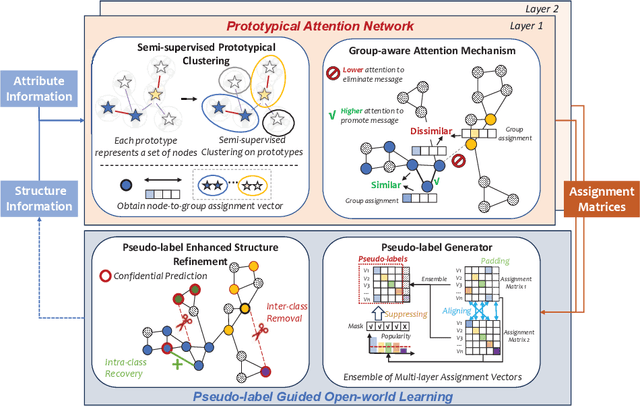
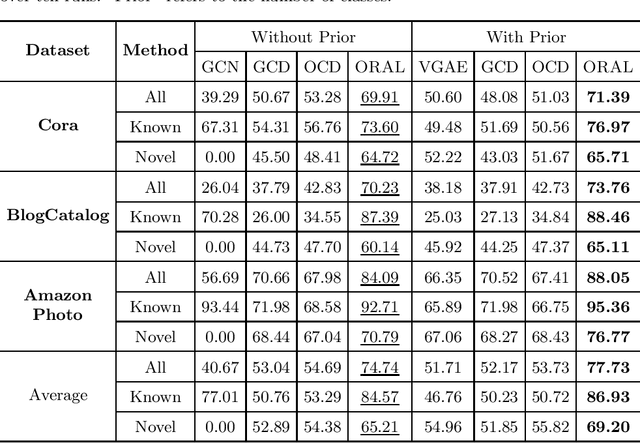
Node classification on graphs is of great importance in many applications. Due to the limited labeling capability and evolution in real-world open scenarios, novel classes can emerge on unlabeled testing nodes. However, little attention has been paid to novel class discovery on graphs. Discovering novel classes is challenging as novel and known class nodes are correlated by edges, which makes their representations indistinguishable when applying message passing GNNs. Furthermore, the novel classes lack labeling information to guide the learning process. In this paper, we propose a novel method Open-world gRAph neuraL network (ORAL) to tackle these challenges. ORAL first detects correlations between classes through semi-supervised prototypical learning. Inter-class correlations are subsequently eliminated by the prototypical attention network, leading to distinctive representations for different classes. Furthermore, to fully explore multi-scale graph features for alleviating label deficiencies, ORAL generates pseudo-labels by aligning and ensembling label estimations from multiple stacked prototypical attention networks. Extensive experiments on several benchmark datasets show the effectiveness of our proposed method.
Motif-aware Riemannian Graph Neural Network with Generative-Contrastive Learning
Jan 02, 2024Graphs are typical non-Euclidean data of complex structures. In recent years, Riemannian graph representation learning has emerged as an exciting alternative to Euclidean ones. However, Riemannian methods are still in an early stage: most of them present a single curvature (radius) regardless of structural complexity, suffer from numerical instability due to the exponential/logarithmic map, and lack the ability to capture motif regularity. In light of the issues above, we propose the problem of \emph{Motif-aware Riemannian Graph Representation Learning}, seeking a numerically stable encoder to capture motif regularity in a diverse-curvature manifold without labels. To this end, we present a novel Motif-aware Riemannian model with Generative-Contrastive learning (MotifRGC), which conducts a minmax game in Riemannian manifold in a self-supervised manner. First, we propose a new type of Riemannian GCN (D-GCN), in which we construct a diverse-curvature manifold by a product layer with the diversified factor, and replace the exponential/logarithmic map by a stable kernel layer. Second, we introduce a motif-aware Riemannian generative-contrastive learning to capture motif regularity in the constructed manifold and learn motif-aware node representation without external labels. Empirical results show the superiority of MofitRGC.