 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClick-Conversion Multi-Task Model with Position Bias Mitigation for Sponsored Search in eCommerce
Jul 29, 2023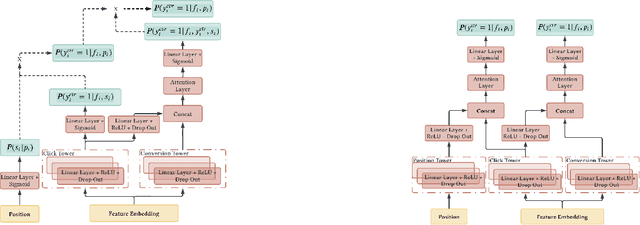
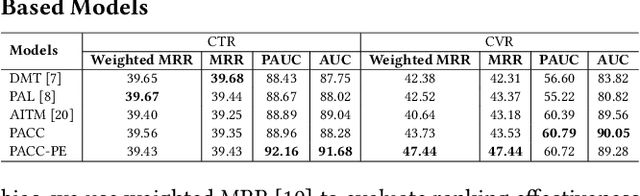
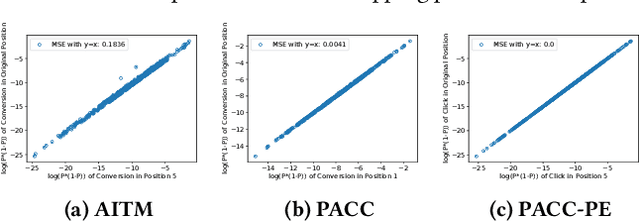
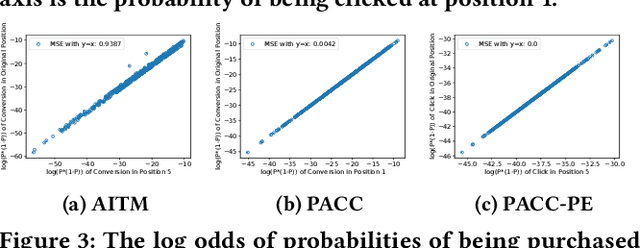
Position bias, the phenomenon whereby users tend to focus on higher-ranked items of the search result list regardless of the actual relevance to queries, is prevailing in many ranking systems. Position bias in training data biases the ranking model, leading to increasingly unfair item rankings, click-through-rate (CTR), and conversion rate (CVR) predictions. To jointly mitigate position bias in both item CTR and CVR prediction, we propose two position-bias-free CTR and CVR prediction models: Position-Aware Click-Conversion (PACC) and PACC via Position Embedding (PACC-PE). PACC is built upon probability decomposition and models position information as a probability. PACC-PE utilizes neural networks to model product-specific position information as embedding. Experiments on the E-commerce sponsored product search dataset show that our proposed models have better ranking effectiveness and can greatly alleviate position bias in both CTR and CVR prediction.
* Modified some typos of the published SIGIR version
Mitigating Frequency Bias in Next-Basket Recommendation via Deconfounders
Nov 16, 2022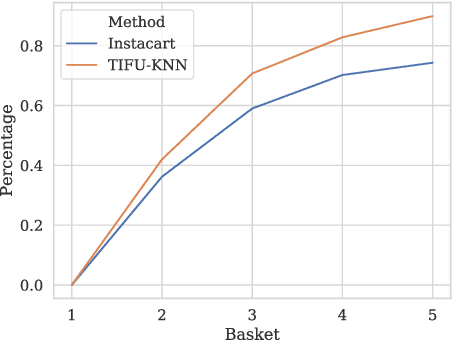
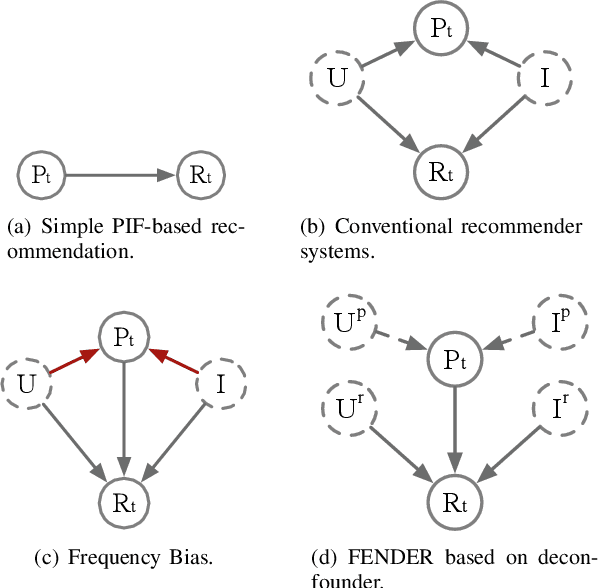
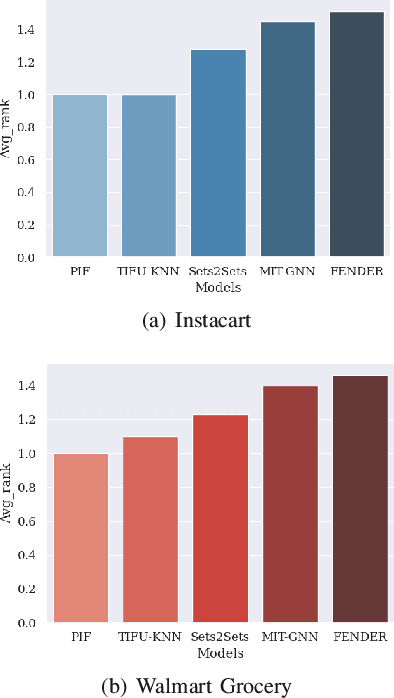
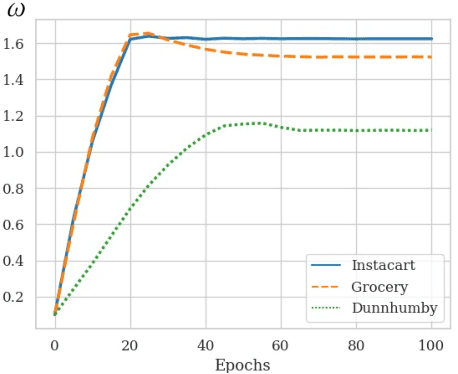
Recent studies on Next-basket Recommendation (NBR) have achieved much progress by leveraging Personalized Item Frequency (PIF) as one of the main features, which measures the frequency of the user's interactions with the item. However, taking the PIF as an explicit feature incurs bias towards frequent items. Items that a user purchases frequently are assigned higher weights in the PIF-based recommender system and appear more frequently in the personalized recommendation list. As a result, the system will lose the fairness and balance between items that the user frequently purchases and items that the user never purchases. We refer to this systematic bias on personalized recommendation lists as frequency bias, which narrows users' browsing scope and reduces the system utility. We adopt causal inference theory to address this issue. Considering the influence of historical purchases on users' future interests, the user and item representations can be viewed as unobserved confounders in the causal diagram. In this paper, we propose a deconfounder model named FENDER (Frequency-aware Deconfounder for Next-basket Recommendation) to mitigate the frequency bias. With the deconfounder theory and the causal diagram we propose, FENDER decomposes PIF with a neural tensor layer to obtain substitute confounders for users and items. Then, FENDER performs unbiased recommendations considering the effect of these substitute confounders. Experimental results demonstrate that FENDER has derived diverse and fair results compared to ten baseline models on three datasets while achieving competitive performance. Further experiments illustrate how FENDER balances users' historical purchases and potential interests.
Causal Structure Learning with Recommendation System
Oct 19, 2022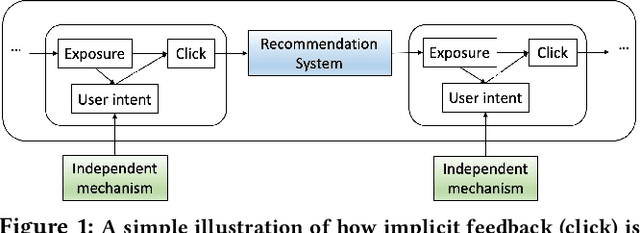
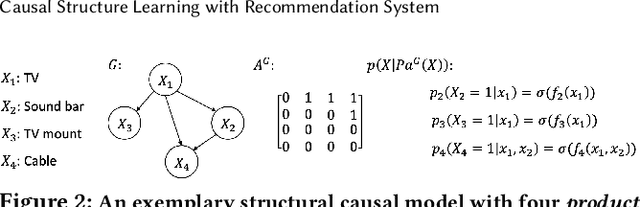
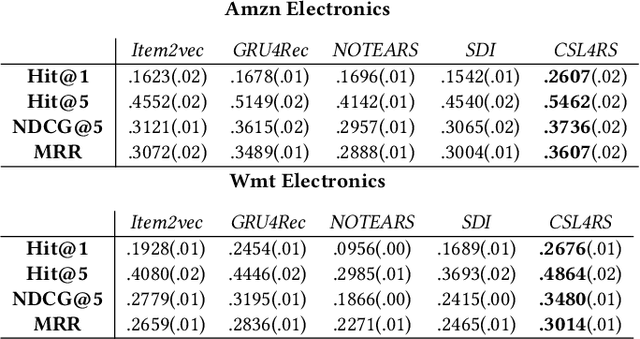
A fundamental challenge of recommendation systems (RS) is understanding the causal dynamics underlying users' decision making. Most existing literature addresses this problem by using causal structures inferred from domain knowledge. However, there are numerous phenomenons where domain knowledge is insufficient, and the causal mechanisms must be learnt from the feedback data. Discovering the causal mechanism from RS feedback data is both novel and challenging, since RS itself is a source of intervention that can influence both the users' exposure and their willingness to interact. Also for this reason, most existing solutions become inappropriate since they require data collected free from any RS. In this paper, we first formulate the underlying causal mechanism as a causal structural model and describe a general causal structure learning framework grounded in the real-world working mechanism of RS. The essence of our approach is to acknowledge the unknown nature of RS intervention. We then derive the learning objective from our framework and propose an augmented Lagrangian solver for efficient optimization. We conduct both simulation and real-world experiments to demonstrate how our approach compares favorably to existing solutions, together with the empirical analysis from sensitivity and ablation studies.
Generating Rich Product Descriptions for Conversational E-commerce Systems
Nov 30, 2021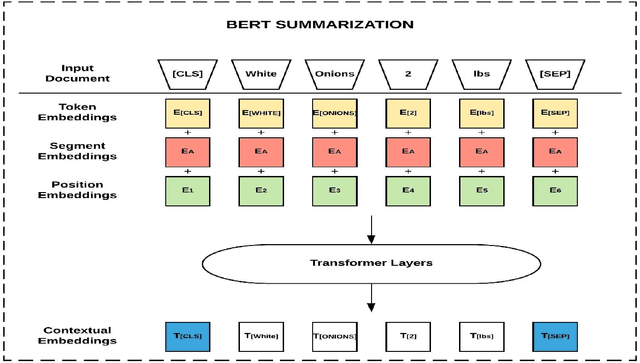

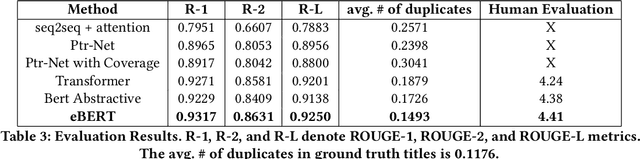
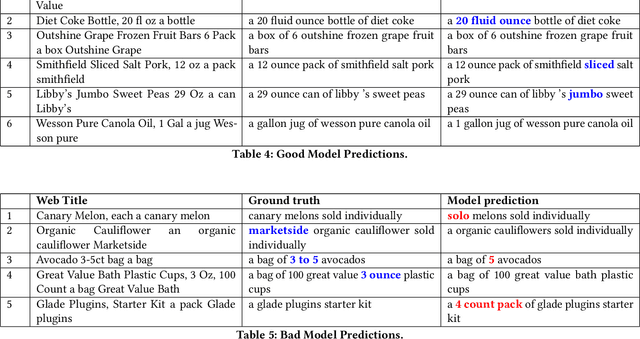
Through recent advancements in speech technologies and introduction of smart assistants, such as Amazon Alexa, Apple Siri and Google Home, increasing number of users are interacting with various applications through voice commands. E-commerce companies typically display short product titles on their webpages, either human-curated or algorithmically generated, when brevity is required. However, these titles are dissimilar from natural spoken language. For example, "Lucky Charms Gluten Free Break-fast Cereal, 20.5 oz a box Lucky Charms Gluten Free" is acceptable to display on a webpage, while a similar title cannot be used in a voice based text-to-speech application. In such conversational systems, an easy to comprehend sentence, such as "a 20.5 ounce box of lucky charms gluten free cereal" is preferred. Compared to display devices, where images and detailed product information can be presented to users, short titles for products which convey the most important information, are necessary when interfacing with voice assistants. We propose eBERT, a sequence-to-sequence approach by further pre-training the BERT embeddings on an e-commerce product description corpus, and then fine-tuning the resulting model to generate short, natural, spoken language titles from input web titles. Our extensive experiments on a real-world industry dataset, as well as human evaluation of model output, demonstrate that eBERT summarization outperforms comparable baseline models. Owing to the efficacy of the model, a version of this model has been deployed in real-world setting.
* 8 pages, 1 figure. arXiv admin note: substantial text overlap with arXiv:2007.11768
Pre-training Recommender Systems via Reinforced Attentive Multi-relational Graph Neural Network
Nov 28, 2021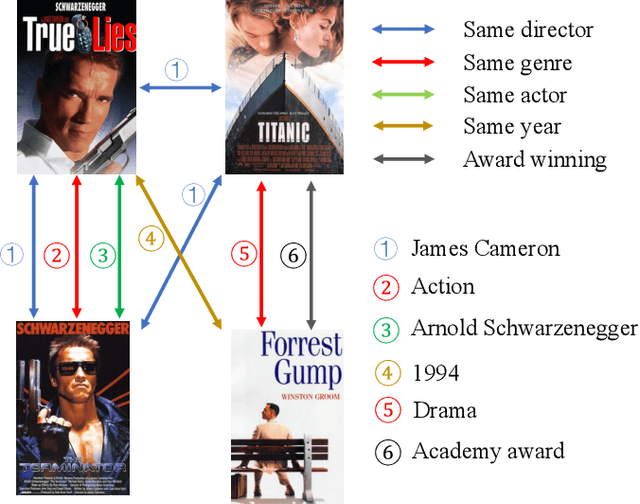
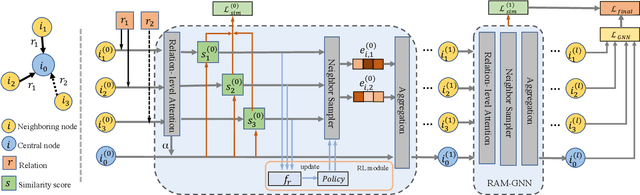
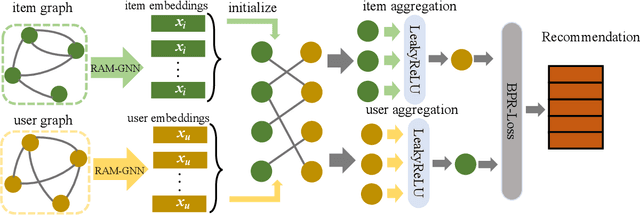
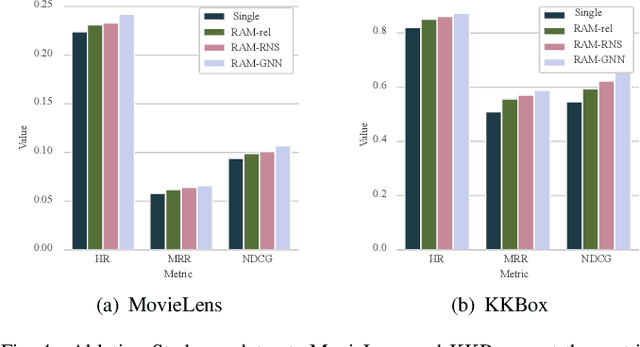
Recently, Graph Neural Networks (GNNs) have proven their effectiveness for recommender systems. Existing studies have applied GNNs to capture collaborative relations in the data. However, in real-world scenarios, the relations in a recommendation graph can be of various kinds. For example, two movies may be associated either by the same genre or by the same director/actor. If we use a single graph to elaborate all these relations, the graph can be too complex to process. To address this issue, we bring the idea of pre-training to process the complex graph step by step. Based on the idea of divide-and-conquer, we separate the large graph into three sub-graphs: user graph, item graph, and user-item interaction graph. Then the user and item embeddings are pre-trained from user and item graphs, respectively. To conduct pre-training, we construct the multi-relational user graph and item graph, respectively, based on their attributes. In this paper, we propose a novel Reinforced Attentive Multi-relational Graph Neural Network (RAM-GNN) to the pre-train user and item embeddings on the user and item graph prior to the recommendation step. Specifically, we design a relation-level attention layer to learn the importance of different relations. Next, a Reinforced Neighbor Sampler (RNS) is applied to search the optimal filtering threshold for sampling top-k similar neighbors in the graph, which avoids the over-smoothing issue. We initialize the recommendation model with the pre-trained user/item embeddings. Finally, an aggregation-based GNN model is utilized to learn from the collaborative relations in the user-item interaction graph and provide recommendations. Our experiments demonstrate that RAM-GNN outperforms other state-of-the-art graph-based recommendation models and multi-relational graph neural networks.
PairRank: Online Pairwise Learning to Rank by Divide-and-Conquer
Mar 03, 2021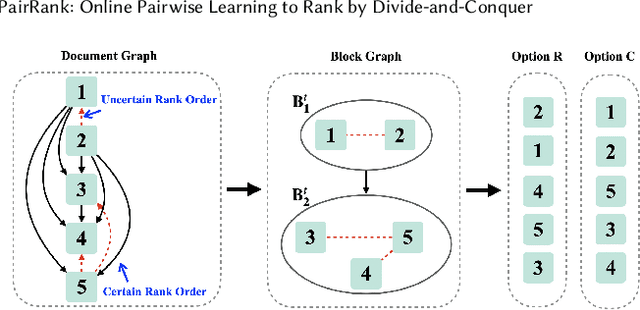

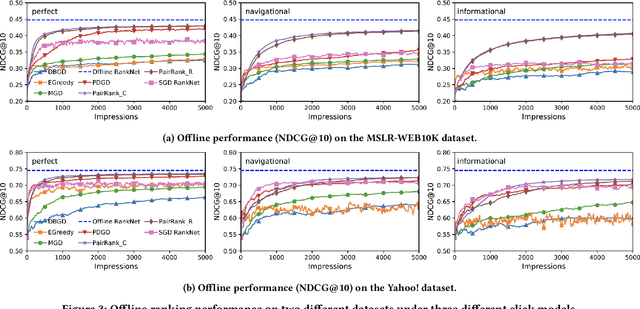
Online Learning to Rank (OL2R) eliminates the need of explicit relevance annotation by directly optimizing the rankers from their interactions with users. However, the required exploration drives it away from successful practices in offline learning to rank, which limits OL2R's empirical performance and practical applicability. In this work, we propose to estimate a pairwise learning to rank model online. In each round, candidate documents are partitioned and ranked according to the model's confidence on the estimated pairwise rank order, and exploration is only performed on the uncertain pairs of documents, i.e., \emph{divide-and-conquer}. Regret directly defined on the number of mis-ordered pairs is proven, which connects the online solution's theoretical convergence with its expected ranking performance. Comparisons against an extensive list of OL2R baselines on two public learning to rank benchmark datasets demonstrate the effectiveness of the proposed solution.
A Real-Time Whole Page Personalization Framework for E-Commerce
Dec 08, 2020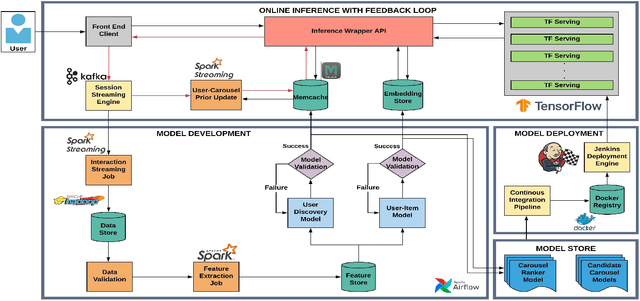
E-commerce platforms consistently aim to provide personalized recommendations to drive user engagement, enhance overall user experience, and improve business metrics. Most e-commerce platforms contain multiple carousels on their homepage, each attempting to capture different facets of the shopping experience. Given varied user preferences, optimizing the placement of these carousels is critical for improved user satisfaction. Furthermore, items within a carousel may change dynamically based on sequential user actions, thus necessitating online ranking of carousels. In this work, we present a scalable end-to-end production system to optimally rank item-carousels in real-time on the Walmart online grocery homepage. The proposed system utilizes a novel model that captures the user's affinity for different carousels and their likelihood to interact with previously unseen items. Our system is flexible in design and is easily extendable to settings where page components need to be ranked. We provide the system architecture consisting of a model development phase and an online inference framework. To ensure low-latency, various optimizations across these stages are implemented. We conducted extensive online evaluations to benchmark against the prior experience. In production, our system resulted in an improvement in item discovery, an increase in online engagement, and a significant lift on add-to-carts (ATCs) per visitor on the homepage.
An End-to-End ML System for Personalized Conversational Voice Models in Walmart E-Commerce
Nov 02, 2020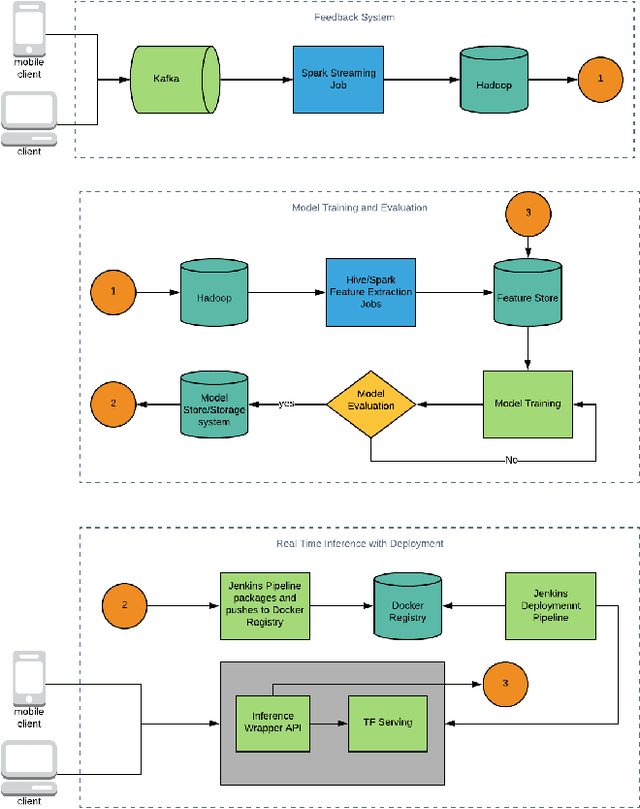
Searching for and making decisions about products is becoming increasingly easier in the e-commerce space, thanks to the evolution of recommender systems. Personalization and recommender systems have gone hand-in-hand to help customers fulfill their shopping needs and improve their experiences in the process. With the growing adoption of conversational platforms for shopping, it has become important to build personalized models at scale to handle the large influx of data and perform inference in real-time. In this work, we present an end-to-end machine learning system for personalized conversational voice commerce. We include components for implicit feedback to the model, model training, evaluation on update, and a real-time inference engine. Our system personalizes voice shopping for Walmart Grocery customers and is currently available via Google Assistant, Siri and Google Home devices.
Basket Recommendation with Multi-Intent Translation Graph Neural Network
Oct 22, 2020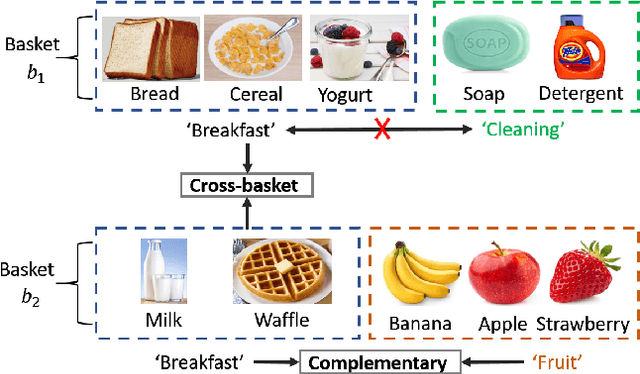
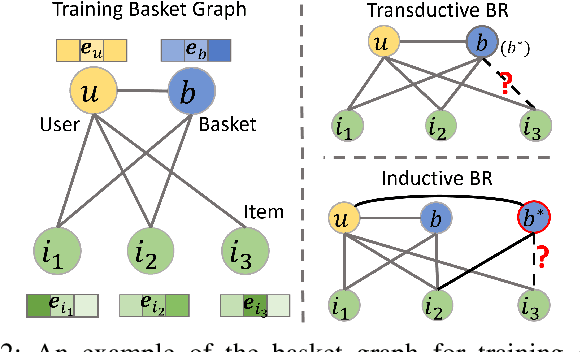
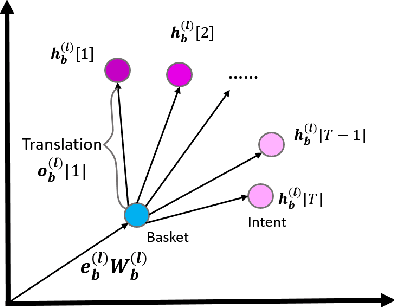
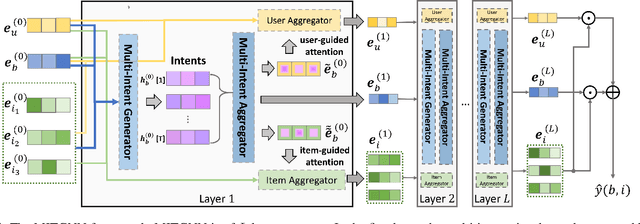
The problem of basket recommendation~(BR) is to recommend a ranking list of items to the current basket. Existing methods solve this problem by assuming the items within the same basket are correlated by one semantic relation, thus optimizing the item embeddings. However, this assumption breaks when there exist multiple intents within a basket. For example, assuming a basket contains \{\textit{bread, cereal, yogurt, soap, detergent}\} where \{\textit{bread, cereal, yogurt}\} are correlated through the "breakfast" intent, while \{\textit{soap, detergent}\} are of "cleaning" intent, ignoring multiple relations among the items spoils the ability of the model to learn the embeddings. To resolve this issue, it is required to discover the intents within the basket. However, retrieving a multi-intent pattern is rather challenging, as intents are latent within the basket. Additionally, intents within the basket may also be correlated. Moreover, discovering a multi-intent pattern requires modeling high-order interactions, as the intents across different baskets are also correlated. To this end, we propose a new framework named as \textbf{M}ulti-\textbf{I}ntent \textbf{T}ranslation \textbf{G}raph \textbf{N}eural \textbf{N}etwork~({\textbf{MITGNN}}). MITGNN models $T$ intents as tail entities translated from one corresponding basket embedding via $T$ relation vectors. The relation vectors are learned through multi-head aggregators to handle user and item information. Additionally, MITGNN propagates multiple intents across our defined basket graph to learn the embeddings of users and items by aggregating neighbors. Extensive experiments on two real-world datasets prove the effectiveness of our proposed model on both transductive and inductive BR. The code is available online at https://github.com/JimLiu96/MITGNN.
* Accepted to IEEE Bigdata 2020. Code is available online at https://github.com/JimLiu96/MITGNN
Product Title Generation for Conversational Systems using BERT
Jul 23, 2020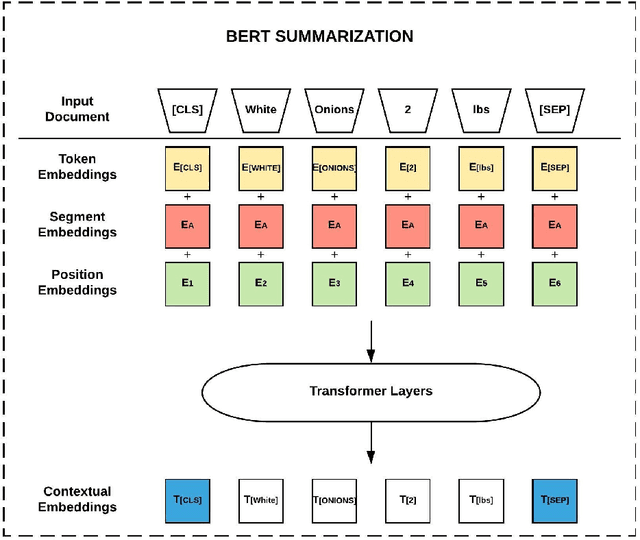



Through recent advancements in speech technology and introduction of smart devices, such as Amazon Alexa and Google Home, increasing number of users are interacting with applications through voice. E-commerce companies typically display short product titles on their webpages, either human-curated or algorithmically generated, when brevity is required, but these titles are dissimilar from natural spoken language. For example, "Lucky Charms Gluten Free Break-fast Cereal, 20.5 oz a box Lucky Charms Gluten Free" is acceptable to display on a webpage, but "a 20.5 ounce box of lucky charms gluten free cereal" is easier to comprehend over a conversational system. As compared to display devices, where images and detailed product information can be presented to users, short titles for products are necessary when interfacing with voice assistants. We propose a sequence-to-sequence approach using BERT to generate short, natural, spoken language titles from input web titles. Our extensive experiments on a real-world industry dataset and human evaluation of model outputs, demonstrate that BERT summarization outperforms comparable baseline models.