 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-HYPER: Generative CTR Modeling for Cold-Start Ad Personalization via LLM-Based Hypernetworks
Apr 13, 2026On online advertising platforms, newly introduced promotional ads face the cold-start problem, as they lack sufficient user feedback for model training. In this work, we propose LLM-HYPER, a novel framework that treats large language models (LLMs) as hypernetworks to directly generate the parameters of the click-through rate (CTR) estimator in a training-free manner. LLM-HYPER uses few-shot Chain-of-Thought prompting over multimodal ad content (text and images) to infer feature-wise model weights for a linear CTR predictor. By retrieving semantically similar past campaigns via CLIP embeddings and formatting them into prompt-based demonstrations, the LLM learns to reason about customer intent, feature influence, and content relevance. To ensure numerical stability and serviceability, we introduce normalization and calibration techniques that align the generated weights with production-ready CTR distributions. Extensive offline experiments show that LLM-HYPER significantly outperforms cold-start baselines in NDCG$@10$ by 55.9\%. Our real-world online A/B test on one of the top e-commerce platforms in the U.S. demonstrates the strong performance of LLM-HYPER, which drastically reduces the cold-start period and achieves competitive performance. LLM-HYPER has been successfully deployed in production.
CASE: Cadence-Aware Set Encoding for Large-Scale Next Basket Repurchase Recommendation
Apr 09, 2026Repurchase behavior is a primary signal in large-scale retail recommendation, particularly in categories with frequent replenishment: many items in a user's next basket were previously purchased and their timing follows stable, item-specific cadences. Yet most next basket repurchase recommendation models represent history as a sequence of discrete basket events indexed by visit order, which cannot explicitly model elapsed calendar time or update item rankings as days pass between purchases. We present CASE (Cadence-Aware Set Encoding for next basket repurchase recommendation), which decouples item-level cadence learning from cross-item interaction, enabling explicit calendar-time modeling while remaining production-scalable. CASE represents each item's purchase history as a calendar-time signal over a fixed horizon, applies shared multi-scale temporal convolutions to capture recurring rhythms, and uses induced set attention to model cross-item dependencies with sub-quadratic complexity, allowing efficient batch inference at scale. Across three public benchmarks and a proprietary dataset, CASE consistently improves Precision, Recall, and NDCG at multiple cutoffs compared to strong next basket prediction baselines. In a production-scale evaluation with tens of millions of users and a large item catalog, CASE achieves up to 8.6% relative Precision and 9.9% Recall lift at top-5, demonstrating that scalable cadence-aware modeling yields measurable gains in both benchmark and industrial settings.
Campaign-2-PT-RAG: LLM-Guided Semantic Product Type Attribution for Scalable Campaign Ranking
Feb 11, 2026E-commerce campaign ranking models require large-scale training labels indicating which users purchased due to campaign influence. However, generating these labels is challenging because campaigns use creative, thematic language that does not directly map to product purchases. Without clear product-level attribution, supervised learning for campaign optimization remains limited. We present \textbf{Campaign-2-PT-RAG}, a scalable label generation framework that constructs user--campaign purchase labels by inferring which product types (PTs) each campaign promotes. The framework first interprets campaign content using large language models (LLMs) to capture implicit intent, then retrieves candidate PTs through semantic search over the platform taxonomy. A structured LLM-based classifier evaluates each PT's relevance, producing a campaign-specific product coverage set. User purchases matching these PTs generate positive training labels for downstream ranking models. This approach reframes the ambiguous attribution problem into a tractable semantic alignment task, enabling scalable and consistent supervision for downstream tasks such as campaign ranking optimization in production e-commerce environments. Experiments on internal and synthetic datasets, validated against expert-annotated campaign--PT mappings, show that our LLM-assisted approach generates high-quality labels with 78--90% precision while maintaining over 99% recall.
Is More Context Always Better? Examining LLM Reasoning Capability for Time Interval Prediction
Jan 15, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning and prediction across different domains. Yet, their ability to infer temporal regularities from structured behavioral data remains underexplored. This paper presents a systematic study investigating whether LLMs can predict time intervals between recurring user actions, such as repeated purchases, and how different levels of contextual information shape their predictive behavior. Using a simple but representative repurchase scenario, we benchmark state-of-the-art LLMs in zero-shot settings against both statistical and machine-learning models. Two key findings emerge. First, while LLMs surpass lightweight statistical baselines, they consistently underperform dedicated machine-learning models, showing their limited ability to capture quantitative temporal structure. Second, although moderate context can improve LLM accuracy, adding further user-level detail degrades performance. These results challenge the assumption that "more context leads to better reasoning". Our study highlights fundamental limitations of today's LLMs in structured temporal inference and offers guidance for designing future context-aware hybrid models that integrate statistical precision with linguistic flexibility.
Spatial Reasoning in Foundation Models: Benchmarking Object-Centric Spatial Understanding
Sep 26, 2025
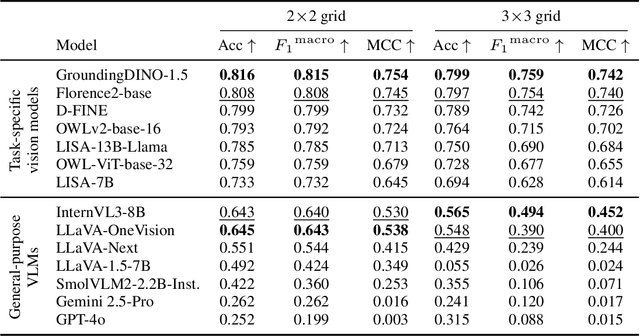

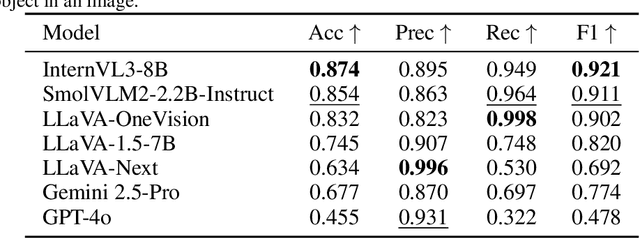
Spatial understanding is a critical capability for vision foundation models. While recent advances in large vision models or vision-language models (VLMs) have expanded recognition capabilities, most benchmarks emphasize localization accuracy rather than whether models capture how objects are arranged and related within a scene. This gap is consequential; effective scene understanding requires not only identifying objects, but reasoning about their relative positions, groupings, and depth. In this paper, we present a systematic benchmark for object-centric spatial reasoning in foundation models. Using a controlled synthetic dataset, we evaluate state-of-the-art vision models (e.g., GroundingDINO, Florence-2, OWLv2) and large VLMs (e.g., InternVL, LLaVA, GPT-4o) across three tasks: spatial localization, spatial reasoning, and downstream retrieval tasks. We find a stable trade-off: detectors such as GroundingDINO and OWLv2 deliver precise boxes with limited relational reasoning, while VLMs like SmolVLM and GPT-4o provide coarse layout cues and fluent captions but struggle with fine-grained spatial context. Our study highlights the gap between localization and true spatial understanding, and pointing toward the need for spatially-aware foundation models in the community.
VL-CLIP: Enhancing Multimodal Recommendations via Visual Grounding and LLM-Augmented CLIP Embeddings
Jul 22, 2025Multimodal learning plays a critical role in e-commerce recommendation platforms today, enabling accurate recommendations and product understanding. However, existing vision-language models, such as CLIP, face key challenges in e-commerce recommendation systems: 1) Weak object-level alignment, where global image embeddings fail to capture fine-grained product attributes, leading to suboptimal retrieval performance; 2) Ambiguous textual representations, where product descriptions often lack contextual clarity, affecting cross-modal matching; and 3) Domain mismatch, as generic vision-language models may not generalize well to e-commerce-specific data. To address these limitations, we propose a framework, VL-CLIP, that enhances CLIP embeddings by integrating Visual Grounding for fine-grained visual understanding and an LLM-based agent for generating enriched text embeddings. Visual Grounding refines image representations by localizing key products, while the LLM agent enhances textual features by disambiguating product descriptions. Our approach significantly improves retrieval accuracy, multimodal retrieval effectiveness, and recommendation quality across tens of millions of items on one of the largest e-commerce platforms in the U.S., increasing CTR by 18.6%, ATC by 15.5%, and GMV by 4.0%. Additional experimental results show that our framework outperforms vision-language models, including CLIP, FashionCLIP, and GCL, in both precision and semantic alignment, demonstrating the potential of combining object-aware visual grounding and LLM-enhanced text representation for robust multimodal recommendations.
Decoding Style: Efficient Fine-Tuning of LLMs for Image-Guided Outfit Recommendation with Preference
Sep 18, 2024



Personalized outfit recommendation remains a complex challenge, demanding both fashion compatibility understanding and trend awareness. This paper presents a novel framework that harnesses the expressive power of large language models (LLMs) for this task, mitigating their "black box" and static nature through fine-tuning and direct feedback integration. We bridge the item visual-textual gap in items descriptions by employing image captioning with a Multimodal Large Language Model (MLLM). This enables the LLM to extract style and color characteristics from human-curated fashion images, forming the basis for personalized recommendations. The LLM is efficiently fine-tuned on the open-source Polyvore dataset of curated fashion images, optimizing its ability to recommend stylish outfits. A direct preference mechanism using negative examples is employed to enhance the LLM's decision-making process. This creates a self-enhancing AI feedback loop that continuously refines recommendations in line with seasonal fashion trends. Our framework is evaluated on the Polyvore dataset, demonstrating its effectiveness in two key tasks: fill-in-the-blank, and complementary item retrieval. These evaluations underline the framework's ability to generate stylish, trend-aligned outfit suggestions, continuously improving through direct feedback. The evaluation results demonstrated that our proposed framework significantly outperforms the base LLM, creating more cohesive outfits. The improved performance in these tasks underscores the proposed framework's potential to enhance the shopping experience with accurate suggestions, proving its effectiveness over the vanilla LLM based outfit generation.
LLM-Ensemble: Optimal Large Language Model Ensemble Method for E-commerce Product Attribute Value Extraction
Feb 29, 2024


Product attribute value extraction is a pivotal component in Natural Language Processing (NLP) and the contemporary e-commerce industry. The provision of precise product attribute values is fundamental in ensuring high-quality recommendations and enhancing customer satisfaction. The recently emerging Large Language Models (LLMs) have demonstrated state-of-the-art performance in numerous attribute extraction tasks, without the need for domain-specific training data. Nevertheless, varying strengths and weaknesses are exhibited by different LLMs due to the diversity in data, architectures, and hyperparameters. This variation makes them complementary to each other, with no single LLM dominating all others. Considering the diverse strengths and weaknesses of LLMs, it becomes necessary to develop an ensemble method that leverages their complementary potentials. In this paper, we propose a novel algorithm called LLM-ensemble to ensemble different LLMs' outputs for attribute value extraction. We iteratively learn the weights for different LLMs to aggregate the labels with weights to predict the final attribute value. Not only can our proposed method be proven theoretically optimal, but it also ensures efficient computation, fast convergence, and safe deployment. We have also conducted extensive experiments with various state-of-the-art LLMs, including Llama2-13B, Llama2-70B, PaLM-2, GPT-3.5, and GPT-4, on Walmart's internal data. Our offline metrics demonstrate that the LLM-ensemble method outperforms all the state-of-the-art single LLMs on Walmart's internal dataset. This method has been launched in several production models, leading to improved Gross Merchandise Volume (GMV), Click-Through Rate (CTR), Conversion Rate (CVR), and Add-to-Cart Rate (ATC).
LLMs with User-defined Prompts as Generic Data Operators for Reliable Data Processing
Dec 26, 2023Data processing is one of the fundamental steps in machine learning pipelines to ensure data quality. Majority of the applications consider the user-defined function (UDF) design pattern for data processing in databases. Although the UDF design pattern introduces flexibility, reusability and scalability, the increasing demand on machine learning pipelines brings three new challenges to this design pattern -- not low-code, not dependency-free and not knowledge-aware. To address these challenges, we propose a new design pattern that large language models (LLMs) could work as a generic data operator (LLM-GDO) for reliable data cleansing, transformation and modeling with their human-compatible performance. In the LLM-GDO design pattern, user-defined prompts (UDPs) are used to represent the data processing logic rather than implementations with a specific programming language. LLMs can be centrally maintained so users don't have to manage the dependencies at the run-time. Fine-tuning LLMs with domain-specific data could enhance the performance on the domain-specific tasks which makes data processing knowledge-aware. We illustrate these advantages with examples in different data processing tasks. Furthermore, we summarize the challenges and opportunities introduced by LLMs to provide a complete view of this design pattern for more discussions.
LLM-TAKE: Theme Aware Keyword Extraction Using Large Language Models
Dec 01, 2023

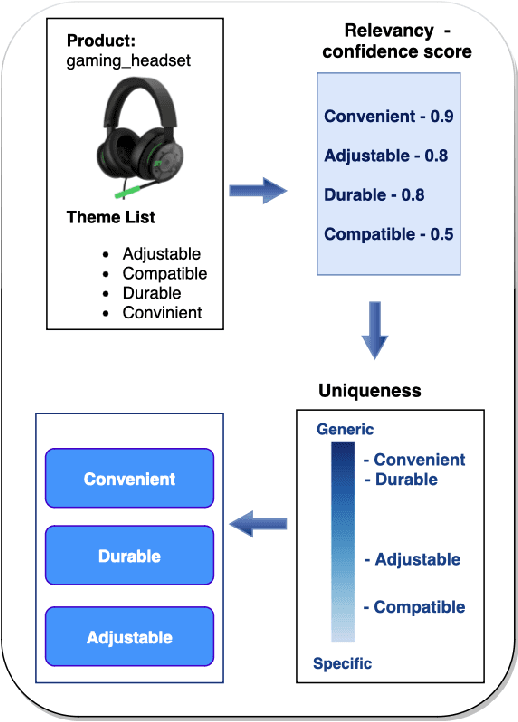
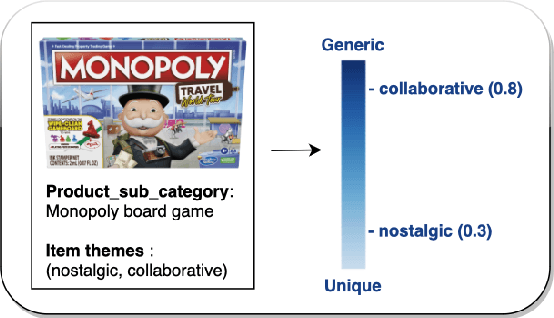
Keyword extraction is one of the core tasks in natural language processing. Classic extraction models are notorious for having a short attention span which make it hard for them to conclude relational connections among the words and sentences that are far from each other. This, in turn, makes their usage prohibitive for generating keywords that are inferred from the context of the whole text. In this paper, we explore using Large Language Models (LLMs) in generating keywords for items that are inferred from the items textual metadata. Our modeling framework includes several stages to fine grain the results by avoiding outputting keywords that are non informative or sensitive and reduce hallucinations common in LLM. We call our LLM-based framework Theme-Aware Keyword Extraction (LLM TAKE). We propose two variations of framework for generating extractive and abstractive themes for products in an E commerce setting. We perform an extensive set of experiments on three real data sets and show that our modeling framework can enhance accuracy based and diversity based metrics when compared with benchmark models.