 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-TAKE: Theme Aware Keyword Extraction Using Large Language Models
Dec 01, 2023

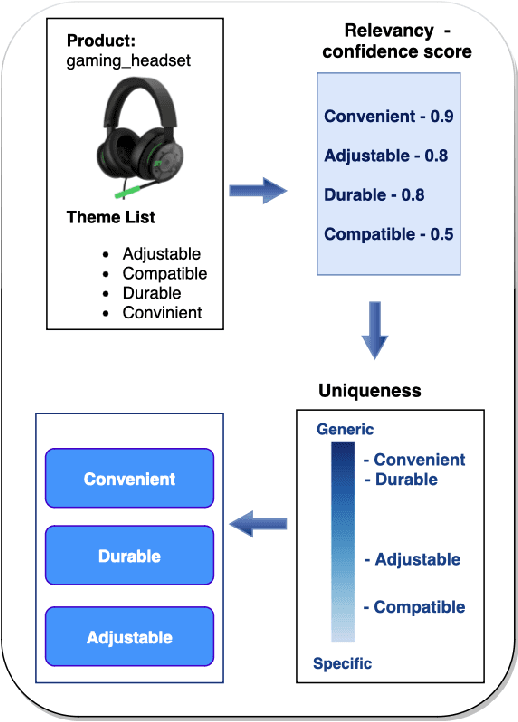
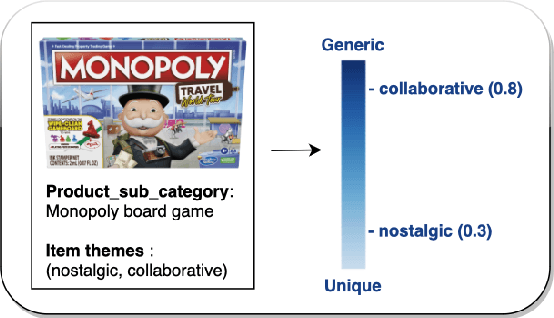
Keyword extraction is one of the core tasks in natural language processing. Classic extraction models are notorious for having a short attention span which make it hard for them to conclude relational connections among the words and sentences that are far from each other. This, in turn, makes their usage prohibitive for generating keywords that are inferred from the context of the whole text. In this paper, we explore using Large Language Models (LLMs) in generating keywords for items that are inferred from the items textual metadata. Our modeling framework includes several stages to fine grain the results by avoiding outputting keywords that are non informative or sensitive and reduce hallucinations common in LLM. We call our LLM-based framework Theme-Aware Keyword Extraction (LLM TAKE). We propose two variations of framework for generating extractive and abstractive themes for products in an E commerce setting. We perform an extensive set of experiments on three real data sets and show that our modeling framework can enhance accuracy based and diversity based metrics when compared with benchmark models.
Reversing The Twenty Questions Game
Jan 19, 2023Twenty questions is a widely popular verbal game. In recent years, many computerized versions of this game have been developed in which a user thinks of an entity and a computer attempts to guess this entity by asking a series of boolean-type (yes/no) questions. In this research, we aim to reverse this game by making the computer choose an entity at random. The human aims to guess this entity by quizzing the computer with natural language queries which the computer will then attempt to parse using a boolean question answering model. The game ends when the human is successfully able to guess the entity of the computer's choice.