 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey for Landing Generative AI in Social and E-commerce Recsys -- the Industry Perspectives
Jun 10, 2024Recently, generative AI (GAI), with their emerging capabilities, have presented unique opportunities for augmenting and revolutionizing industrial recommender systems (Recsys). Despite growing research efforts at the intersection of these fields, the integration of GAI into industrial Recsys remains in its infancy, largely due to the intricate nature of modern industrial Recsys infrastructure, operations, and product sophistication. Drawing upon our experiences in successfully integrating GAI into several major social and e-commerce platforms, this survey aims to comprehensively examine the underlying system and AI foundations, solution frameworks, connections to key research advancements, as well as summarize the practical insights and challenges encountered in the endeavor to integrate GAI into industrial Recsys. As pioneering work in this domain, we hope outline the representative developments of relevant fields, shed lights on practical GAI adoptions in the industry, and motivate future research.
CoRE: LLM as Interpreter for Natural Language Programming, Pseudo-Code Programming, and Flow Programming of AI Agents
May 11, 2024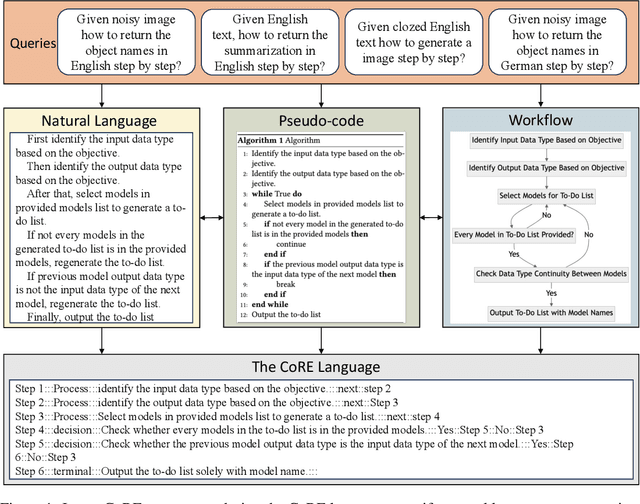
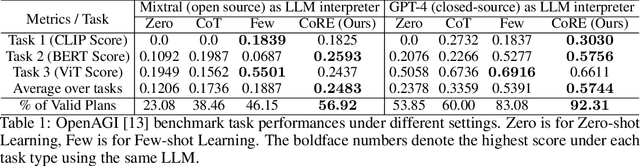


Since their inception, programming languages have trended towards greater readability and lower barriers for programmers. Following this trend, natural language can be a promising type of programming language that provides great flexibility and usability and helps towards the democracy of programming. However, the inherent vagueness, ambiguity, and verbosity of natural language pose significant challenges in developing an interpreter that can accurately understand the programming logic and execute instructions written in natural language. Fortunately, recent advancements in Large Language Models (LLMs) have demonstrated remarkable proficiency in interpreting complex natural language. Inspired by this, we develop a novel system for Code Representation and Execution (CoRE), which employs LLM as interpreter to interpret and execute natural language instructions. The proposed system unifies natural language programming, pseudo-code programming, and flow programming under the same representation for constructing language agents, while LLM serves as the interpreter to interpret and execute the agent programs. In this paper, we begin with defining the programming syntax that structures natural language instructions logically. During the execution, we incorporate external memory to minimize redundancy. Furthermore, we equip the designed interpreter with the capability to invoke external tools, compensating for the limitations of LLM in specialized domains or when accessing real-time information. This work is open-source at https://github.com/agiresearch/CoRE.
Towards LLM-RecSys Alignment with Textual ID Learning
Mar 27, 2024Generative recommendation based on Large Language Models (LLMs) have transformed the traditional ranking-based recommendation style into a text-to-text generation paradigm. However, in contrast to standard NLP tasks that inherently operate on human vocabulary, current research in generative recommendations struggles to effectively encode recommendation items within the text-to-text framework using concise yet meaningful ID representations. To better align LLMs with recommendation needs, we propose IDGen, representing each item as a unique, concise, semantically rich, platform-agnostic textual ID using human language tokens. This is achieved by training a textual ID generator alongside the LLM-based recommender, enabling seamless integration of personalized recommendations into natural language generation. Notably, as user history is expressed in natural language and decoupled from the original dataset, our approach suggests the potential for a foundational generative recommendation model. Experiments show that our framework consistently surpasses existing models in sequential recommendation under standard experimental setting. Then, we explore the possibility of training a foundation recommendation model with the proposed method on data collected from 19 different datasets and tested its recommendation performance on 6 unseen datasets across different platforms under a completely zero-shot setting. The results show that the zero-shot performance of the pre-trained foundation model is comparable to or even better than some traditional recommendation models based on supervised training, showing the potential of the IDGen paradigm serving as the foundation model for generative recommendation. Code and data are open-sourced at https://github.com/agiresearch/IDGenRec.
AIOS: LLM Agent Operating System
Mar 26, 2024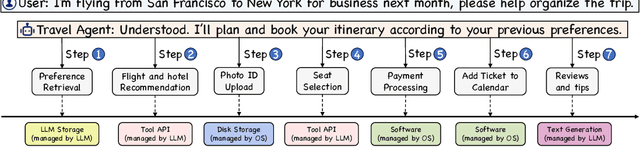
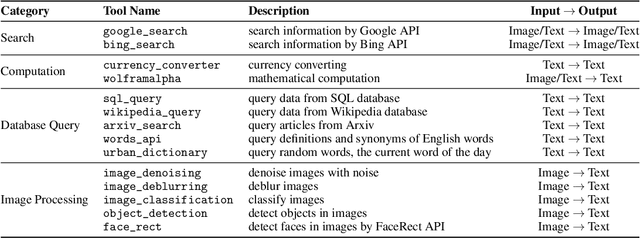
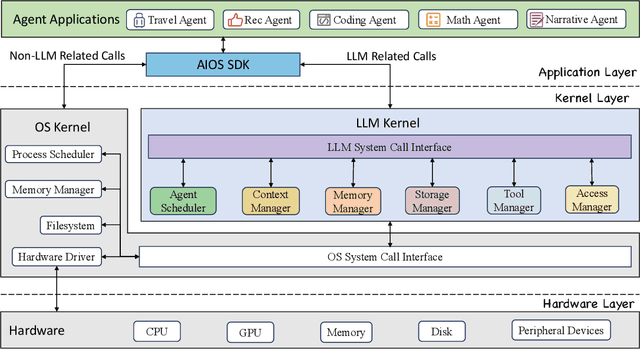
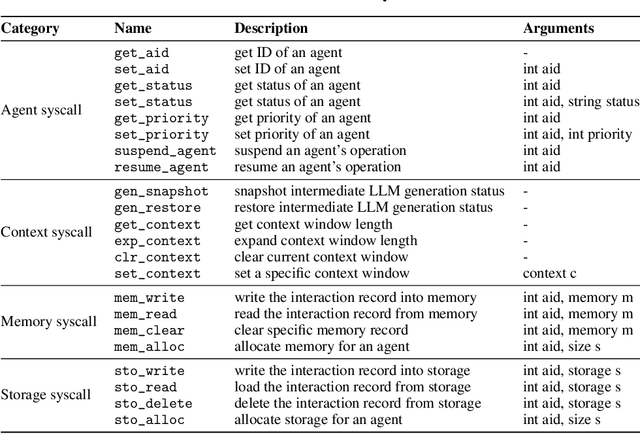
The integration and deployment of large language model (LLM)-based intelligent agents have been fraught with challenges that compromise their efficiency and efficacy. Among these issues are sub-optimal scheduling and resource allocation of agent requests over the LLM, the difficulties in maintaining context during interactions between agent and LLM, and the complexities inherent in integrating heterogeneous agents with different capabilities and specializations. The rapid increase of agent quantity and complexity further exacerbates these issues, often leading to bottlenecks and sub-optimal utilization of resources. Inspired by these challenges, this paper presents AIOS, an LLM agent operating system, which embeds large language model into operating systems (OS) as the brain of the OS, enabling an operating system "with soul" -- an important step towards AGI. Specifically, AIOS is designed to optimize resource allocation, facilitate context switch across agents, enable concurrent execution of agents, provide tool service for agents, and maintain access control for agents. We present the architecture of such an operating system, outline the core challenges it aims to resolve, and provide the basic design and implementation of the AIOS. Our experiments on concurrent execution of multiple agents demonstrate the reliability and efficiency of our AIOS modules. Through this, we aim to not only improve the performance and efficiency of LLM agents but also to pioneer for better development and deployment of the AIOS ecosystem in the future. The project is open-source at https://github.com/agiresearch/AIOS.
LLM as OS, Agents as Apps: Envisioning AIOS, Agents and the AIOS-Agent Ecosystem
Dec 09, 2023This paper envisions a revolutionary AIOS-Agent ecosystem, where Large Language Model (LLM) serves as the (Artificial) Intelligent Operating System (IOS, or AIOS)--an operating system "with soul". Upon this foundation, a diverse range of LLM-based AI Agent Applications (Agents, or AAPs) are developed, enriching the AIOS-Agent ecosystem and signaling a paradigm shift from the traditional OS-APP ecosystem. We envision that LLM's impact will not be limited to the AI application level, instead, it will in turn revolutionize the design and implementation of computer system, architecture, software, and programming language, featured by several main concepts: LLM as OS (system-level), Agents as Applications (application-level), Natural Language as Programming Interface (user-level), and Tools as Devices/Libraries (hardware/middleware-level). We begin by introducing the architecture of traditional OS. Then we formalize a conceptual framework for AIOS through "LLM as OS (LLMOS)", drawing analogies between AIOS and traditional OS: LLM is likened to OS kernel, context window to memory, external storage to file system, hardware tools to peripheral devices, software tools to programming libraries, and user prompts to user commands. Subsequently, we introduce the new AIOS-Agent Ecosystem, where users can easily program Agent Applications (AAPs) using natural language, democratizing the development of software, which is different from the traditional OS-APP ecosystem. Following this, we explore the diverse scope of Agent Applications. We delve into both single-agent and multi-agent systems, as well as human-agent interaction. Lastly, drawing on the insights from traditional OS-APP ecosystem, we propose a roadmap for the evolution of the AIOS-Agent ecosystem. This roadmap is designed to guide the future research and development, suggesting systematic progresses of AIOS and its Agent applications.
Natural Language is All a Graph Needs
Aug 24, 2023The emergence of large-scale pre-trained language models, such as ChatGPT, has revolutionized various research fields in artificial intelligence. Transformers-based large language models (LLMs) have gradually replaced CNNs and RNNs to unify fields of computer vision and natural language processing. Compared with the data that exists relatively independently such as images, videos or texts, graph is a type of data that contains rich structural and relational information. Meanwhile, natural language, as one of the most expressive mediums, excels in describing complex structures. However, existing work on incorporating graph learning problems into the generative language modeling framework remains very limited. As the importance of large language models continues to grow, it becomes essential to explore whether LLMs can also replace GNNs as the foundation model for graphs. In this paper, we propose InstructGLM (Instruction-finetuned Graph Language Model), systematically design highly scalable prompts based on natural language instructions, and use natural language to describe the geometric structure and node features of the graph for instruction tuning an LLM to perform learning and inference on graphs in a generative manner. Our method exceeds all competitive GNN baselines on ogbn-arxiv, Cora and PubMed datasets, which demonstrates the effectiveness of our method and sheds light on generative large language models as the foundation model for graph machine learning.
GenRec: Large Language Model for Generative Recommendation
Jul 04, 2023In recent years, large language models (LLM) have emerged as powerful tools for diverse natural language processing tasks. However, their potential for recommender systems under the generative recommendation paradigm remains relatively unexplored. This paper presents an innovative approach to recommendation systems using large language models (LLMs) based on text data. In this paper, we present a novel LLM for generative recommendation (GenRec) that utilized the expressive power of LLM to directly generate the target item to recommend, rather than calculating ranking score for each candidate item one by one as in traditional discriminative recommendation. GenRec uses LLM's understanding ability to interpret context, learn user preferences, and generate relevant recommendation. Our proposed approach leverages the vast knowledge encoded in large language models to accomplish recommendation tasks. We first we formulate specialized prompts to enhance the ability of LLM to comprehend recommendation tasks. Subsequently, we use these prompts to fine-tune the LLaMA backbone LLM on a dataset of user-item interactions, represented by textual data, to capture user preferences and item characteristics. Our research underscores the potential of LLM-based generative recommendation in revolutionizing the domain of recommendation systems and offers a foundational framework for future explorations in this field. We conduct extensive experiments on benchmark datasets, and the experiments shows that our GenRec has significant better results on large dataset.
Counterfactual Collaborative Reasoning
Jun 30, 2023Causal reasoning and logical reasoning are two important types of reasoning abilities for human intelligence. However, their relationship has not been extensively explored under machine intelligence context. In this paper, we explore how the two reasoning abilities can be jointly modeled to enhance both accuracy and explainability of machine learning models. More specifically, by integrating two important types of reasoning ability -- counterfactual reasoning and (neural) logical reasoning -- we propose Counterfactual Collaborative Reasoning (CCR), which conducts counterfactual logic reasoning to improve the performance. In particular, we use recommender system as an example to show how CCR alleviate data scarcity, improve accuracy and enhance transparency. Technically, we leverage counterfactual reasoning to generate "difficult" counterfactual training examples for data augmentation, which -- together with the original training examples -- can enhance the model performance. Since the augmented data is model irrelevant, they can be used to enhance any model, enabling the wide applicability of the technique. Besides, most of the existing data augmentation methods focus on "implicit data augmentation" over users' implicit feedback, while our framework conducts "explicit data augmentation" over users explicit feedback based on counterfactual logic reasoning. Experiments on three real-world datasets show that CCR achieves better performance than non-augmented models and implicitly augmented models, and also improves model transparency by generating counterfactual explanations.
OpenP5: Benchmarking Foundation Models for Recommendation
Jun 19, 2023



This paper presents OpenP5, an open-source library for benchmarking foundation models for recommendation under the Pre-train, Personalized Prompt and Predict Paradigm (P5). We consider the implementation of P5 on three dimensions: 1) downstream task, 2) recommendation dataset, and 3) item indexing method. For 1), we provide implementation over two downstream tasks: sequential recommendation and straightforward recommendation. For 2), we surveyed frequently used datasets in recommender system research in recent years and provide implementation on ten datasets. In particular, we provide both single-dataset implementation and the corresponding checkpoints (P5) and another Super P5 (SP5) implementation that is pre-trained on all of the datasets, which supports recommendation across various domains with one model. For 3), we provide implementation of three item indexing methods to create item IDs: random indexing, sequential indexing, and collaborative indexing. We also provide comprehensive evaluation results of the library over the two downstream tasks, the ten datasets, and the three item indexing methods to facilitate reproducibility and future research. We open-source the code and the pre-trained checkpoints of the OpenP5 library at https://github.com/agiresearch/OpenP5.
UP5: Unbiased Foundation Model for Fairness-aware Recommendation
May 20, 2023



Recent advancements in foundation models such as large language models (LLM) have propelled them to the forefront of recommender systems (RS). Moreover, fairness in RS is critical since many users apply it for decision-making and demand fulfillment. However, at present, there is a lack of understanding regarding the level of fairness exhibited by recommendation foundation models and the appropriate methods for equitably treating different groups of users in foundation models. In this paper, we focus on user-side unfairness problem and show through a thorough examination that there is unfairness involved in LLMs that lead to unfair recommendation results. To eliminate bias from LLM for fairness-aware recommendation, we introduce a novel Unbiased P5 (UP5) foundation model based on Counterfactually-Fair-Prompting (CFP) techniques. CFP includes two sub-modules: a personalized prefix prompt that enhances fairness with respect to individual sensitive attributes, and a Prompt Mixture that integrates multiple counterfactually-fair prompts for a set of sensitive attributes. Experiments are conducted on two real-world datasets, MovieLens-1M and Insurance, and results are compared with both matching-based and sequential-based fairness-aware recommendation models. The results show that UP5 achieves better recommendation performance and meanwhile exhibits a high level of fairness.