 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIOS: LLM Agent Operating System
Mar 26, 2024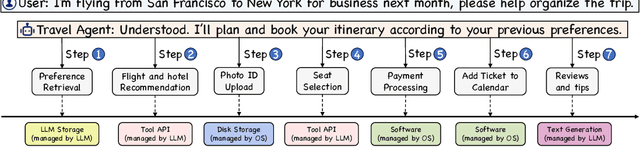
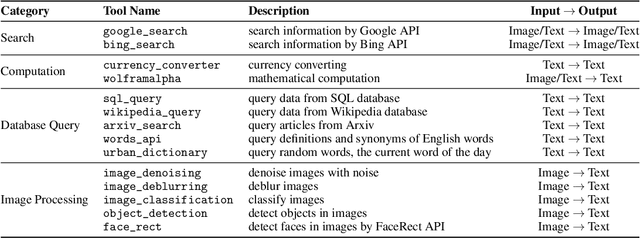
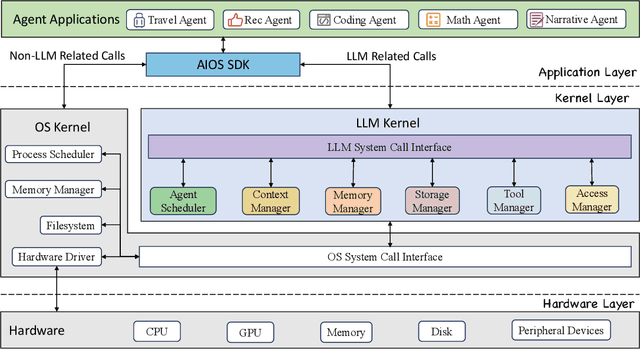
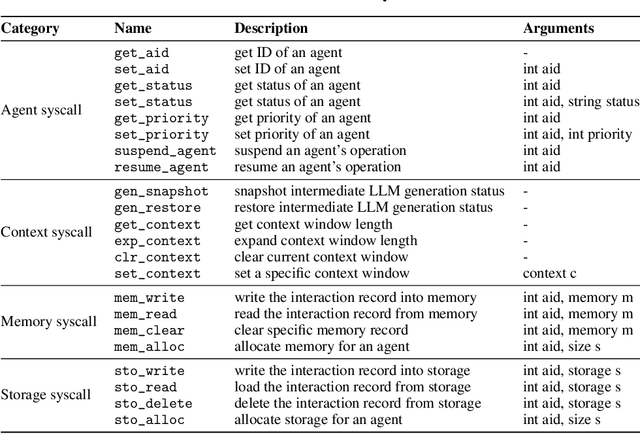
The integration and deployment of large language model (LLM)-based intelligent agents have been fraught with challenges that compromise their efficiency and efficacy. Among these issues are sub-optimal scheduling and resource allocation of agent requests over the LLM, the difficulties in maintaining context during interactions between agent and LLM, and the complexities inherent in integrating heterogeneous agents with different capabilities and specializations. The rapid increase of agent quantity and complexity further exacerbates these issues, often leading to bottlenecks and sub-optimal utilization of resources. Inspired by these challenges, this paper presents AIOS, an LLM agent operating system, which embeds large language model into operating systems (OS) as the brain of the OS, enabling an operating system "with soul" -- an important step towards AGI. Specifically, AIOS is designed to optimize resource allocation, facilitate context switch across agents, enable concurrent execution of agents, provide tool service for agents, and maintain access control for agents. We present the architecture of such an operating system, outline the core challenges it aims to resolve, and provide the basic design and implementation of the AIOS. Our experiments on concurrent execution of multiple agents demonstrate the reliability and efficiency of our AIOS modules. Through this, we aim to not only improve the performance and efficiency of LLM agents but also to pioneer for better development and deployment of the AIOS ecosystem in the future. The project is open-source at https://github.com/agiresearch/AIOS.
Natural Language is All a Graph Needs
Aug 24, 2023The emergence of large-scale pre-trained language models, such as ChatGPT, has revolutionized various research fields in artificial intelligence. Transformers-based large language models (LLMs) have gradually replaced CNNs and RNNs to unify fields of computer vision and natural language processing. Compared with the data that exists relatively independently such as images, videos or texts, graph is a type of data that contains rich structural and relational information. Meanwhile, natural language, as one of the most expressive mediums, excels in describing complex structures. However, existing work on incorporating graph learning problems into the generative language modeling framework remains very limited. As the importance of large language models continues to grow, it becomes essential to explore whether LLMs can also replace GNNs as the foundation model for graphs. In this paper, we propose InstructGLM (Instruction-finetuned Graph Language Model), systematically design highly scalable prompts based on natural language instructions, and use natural language to describe the geometric structure and node features of the graph for instruction tuning an LLM to perform learning and inference on graphs in a generative manner. Our method exceeds all competitive GNN baselines on ogbn-arxiv, Cora and PubMed datasets, which demonstrates the effectiveness of our method and sheds light on generative large language models as the foundation model for graph machine learning.
Reinforcement Learning for Robot Navigation with Adaptive ExecutionDuration (AED) in a Semi-Markov Model
Aug 30, 2021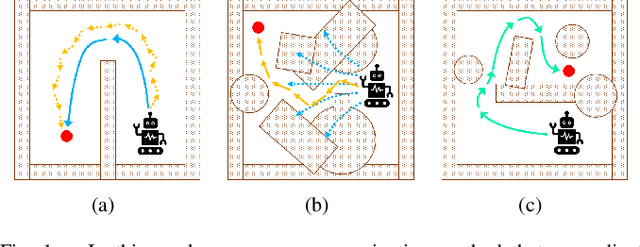
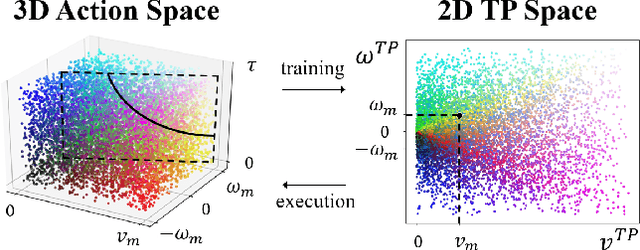
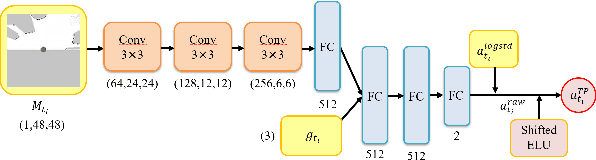
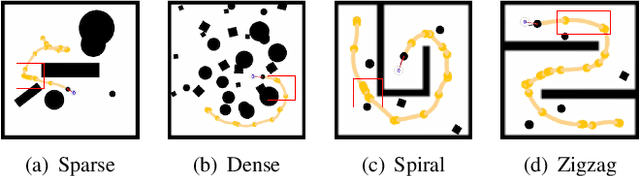
Deep reinforcement learning (DRL) algorithms have proven effective in robot navigation, especially in unknown environments, through directly mapping perception inputs into robot control commands. Most existing methods adopt uniform execution duration with robots taking commands at fixed intervals. As such, the length of execution duration becomes a crucial parameter to the navigation algorithm. In particular, if the duration is too short, then the navigation policy would be executed at a high frequency, with increased training difficulty and high computational cost. Meanwhile, if the duration is too long, then the policy becomes unable to handle complex situations, like those with crowded obstacles. It is thus tricky to find the "sweet" duration range; some duration values may render a DRL model to fail to find a navigation path. In this paper, we propose to employ adaptive execution duration to overcome this problem. Specifically, we formulate the navigation task as a Semi-Markov Decision Process (SMDP) problem to handle adaptive execution duration. We also improve the distributed proximal policy optimization (DPPO) algorithm and provide its theoretical guarantee for the specified SMDP problem. We evaluate our approach both in the simulator and on an actual robot. The results show that our approach outperforms the other DRL-based method (with fixed execution duration) by 10.3% in terms of the navigation success rate.