 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Grammatical Error Annotation: Combining Language-Agnostic Framework with Language-Specific Flexibility
Jun 09, 2025



Grammatical Error Correction (GEC) relies on accurate error annotation and evaluation, yet existing frameworks, such as $\texttt{errant}$, face limitations when extended to typologically diverse languages. In this paper, we introduce a standardized, modular framework for multilingual grammatical error annotation. Our approach combines a language-agnostic foundation with structured language-specific extensions, enabling both consistency and flexibility across languages. We reimplement $\texttt{errant}$ using $\texttt{stanza}$ to support broader multilingual coverage, and demonstrate the framework's adaptability through applications to English, German, Czech, Korean, and Chinese, ranging from general-purpose annotation to more customized linguistic refinements. This work supports scalable and interpretable GEC annotation across languages and promotes more consistent evaluation in multilingual settings. The complete codebase and annotation tools can be accessed at https://github.com/open-writing-evaluation/jp_errant_bea.
Parsing Through Boundaries in Chinese Word Segmentation
Mar 29, 2025Chinese word segmentation is a foundational task in natural language processing (NLP), with far-reaching effects on syntactic analysis. Unlike alphabetic languages like English, Chinese lacks explicit word boundaries, making segmentation both necessary and inherently ambiguous. This study highlights the intricate relationship between word segmentation and syntactic parsing, providing a clearer understanding of how different segmentation strategies shape dependency structures in Chinese. Focusing on the Chinese GSD treebank, we analyze multiple word boundary schemes, each reflecting distinct linguistic and computational assumptions, and examine how they influence the resulting syntactic structures. To support detailed comparison, we introduce an interactive web-based visualization tool that displays parsing outcomes across segmentation methods.
Detail-Preserving Latent Diffusion for Stable Shadow Removal
Dec 23, 2024Achieving high-quality shadow removal with strong generalizability is challenging in scenes with complex global illumination. Due to the limited diversity in shadow removal datasets, current methods are prone to overfitting training data, often leading to reduced performance on unseen cases. To address this, we leverage the rich visual priors of a pre-trained Stable Diffusion (SD) model and propose a two-stage fine-tuning pipeline to adapt the SD model for stable and efficient shadow removal. In the first stage, we fix the VAE and fine-tune the denoiser in latent space, which yields substantial shadow removal but may lose some high-frequency details. To resolve this, we introduce a second stage, called the detail injection stage. This stage selectively extracts features from the VAE encoder to modulate the decoder, injecting fine details into the final results. Experimental results show that our method outperforms state-of-the-art shadow removal techniques. The cross-dataset evaluation further demonstrates that our method generalizes effectively to unseen data, enhancing the applicability of shadow removal methods.
OmniSR: Shadow Removal under Direct and Indirect Lighting
Oct 02, 2024



Shadows can originate from occlusions in both direct and indirect illumination. Although most current shadow removal research focuses on shadows caused by direct illumination, shadows from indirect illumination are often just as pervasive, particularly in indoor scenes. A significant challenge in removing shadows from indirect illumination is obtaining shadow-free images to train the shadow removal network. To overcome this challenge, we propose a novel rendering pipeline for generating shadowed and shadow-free images under direct and indirect illumination, and create a comprehensive synthetic dataset that contains over 30,000 image pairs, covering various object types and lighting conditions. We also propose an innovative shadow removal network that explicitly integrates semantic and geometric priors through concatenation and attention mechanisms. The experiments show that our method outperforms state-of-the-art shadow removal techniques and can effectively generalize to indoor and outdoor scenes under various lighting conditions, enhancing the overall effectiveness and applicability of shadow removal methods.
Disentangling Logic: The Role of Context in Large Language Model Reasoning Capabilities
Jun 04, 2024This study intends to systematically disentangle pure logic reasoning and text understanding by investigating the contrast across abstract and contextualized logical problems from a comprehensive set of domains. We explore whether LLMs demonstrate genuine reasoning capabilities across various domains when the underlying logical structure remains constant. We focus on two main questions (1) Can abstract logical problems alone accurately benchmark an LLM's reasoning ability in real-world scenarios, disentangled from contextual support in practical settings? (2) Does fine-tuning LLMs on abstract logic problem generalize to contextualized logic problems and vice versa? To investigate these questions, we focus on standard propositional logic, specifically propositional deductive and abductive logic reasoning. In particular, we construct instantiated datasets for deductive and abductive reasoning with 4 levels of difficulty, encompassing 12 distinct categories or domains based on the categorization of Wikipedia. Our experiments aim to provide insights into disentangling context in logical reasoning and the true reasoning capabilities of LLMs and their generalization potential. The code and dataset are available at: https://github.com/agiresearch/ContextHub.
CoRE: LLM as Interpreter for Natural Language Programming, Pseudo-Code Programming, and Flow Programming of AI Agents
May 11, 2024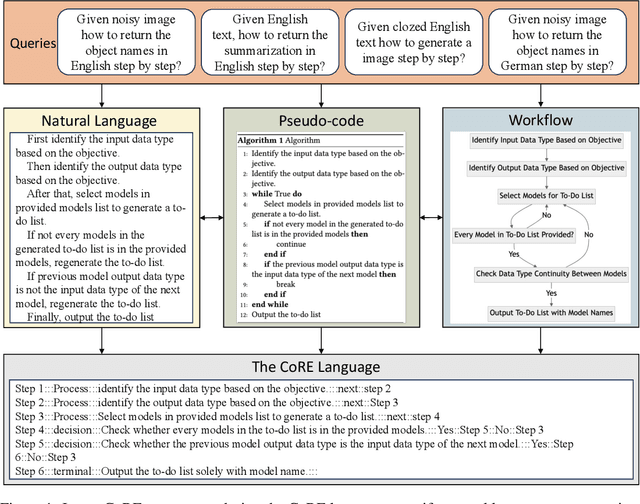
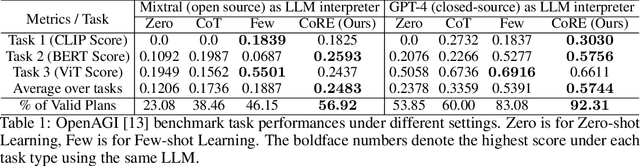


Since their inception, programming languages have trended towards greater readability and lower barriers for programmers. Following this trend, natural language can be a promising type of programming language that provides great flexibility and usability and helps towards the democracy of programming. However, the inherent vagueness, ambiguity, and verbosity of natural language pose significant challenges in developing an interpreter that can accurately understand the programming logic and execute instructions written in natural language. Fortunately, recent advancements in Large Language Models (LLMs) have demonstrated remarkable proficiency in interpreting complex natural language. Inspired by this, we develop a novel system for Code Representation and Execution (CoRE), which employs LLM as interpreter to interpret and execute natural language instructions. The proposed system unifies natural language programming, pseudo-code programming, and flow programming under the same representation for constructing language agents, while LLM serves as the interpreter to interpret and execute the agent programs. In this paper, we begin with defining the programming syntax that structures natural language instructions logically. During the execution, we incorporate external memory to minimize redundancy. Furthermore, we equip the designed interpreter with the capability to invoke external tools, compensating for the limitations of LLM in specialized domains or when accessing real-time information. This work is open-source at https://github.com/agiresearch/CoRE.
Towards LLM-RecSys Alignment with Textual ID Learning
Mar 27, 2024Generative recommendation based on Large Language Models (LLMs) have transformed the traditional ranking-based recommendation style into a text-to-text generation paradigm. However, in contrast to standard NLP tasks that inherently operate on human vocabulary, current research in generative recommendations struggles to effectively encode recommendation items within the text-to-text framework using concise yet meaningful ID representations. To better align LLMs with recommendation needs, we propose IDGen, representing each item as a unique, concise, semantically rich, platform-agnostic textual ID using human language tokens. This is achieved by training a textual ID generator alongside the LLM-based recommender, enabling seamless integration of personalized recommendations into natural language generation. Notably, as user history is expressed in natural language and decoupled from the original dataset, our approach suggests the potential for a foundational generative recommendation model. Experiments show that our framework consistently surpasses existing models in sequential recommendation under standard experimental setting. Then, we explore the possibility of training a foundation recommendation model with the proposed method on data collected from 19 different datasets and tested its recommendation performance on 6 unseen datasets across different platforms under a completely zero-shot setting. The results show that the zero-shot performance of the pre-trained foundation model is comparable to or even better than some traditional recommendation models based on supervised training, showing the potential of the IDGen paradigm serving as the foundation model for generative recommendation. Code and data are open-sourced at https://github.com/agiresearch/IDGenRec.
AIOS: LLM Agent Operating System
Mar 26, 2024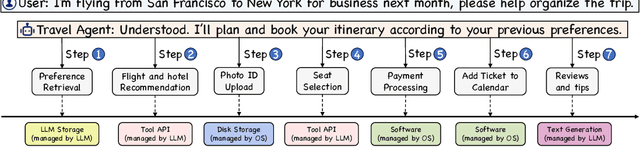
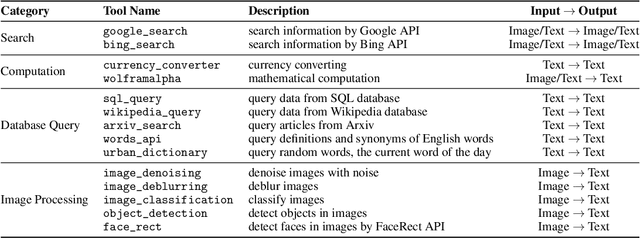
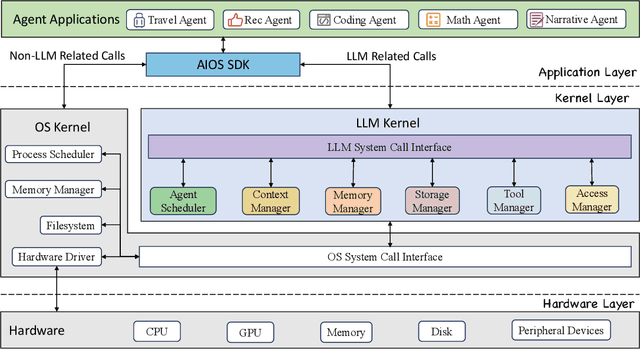
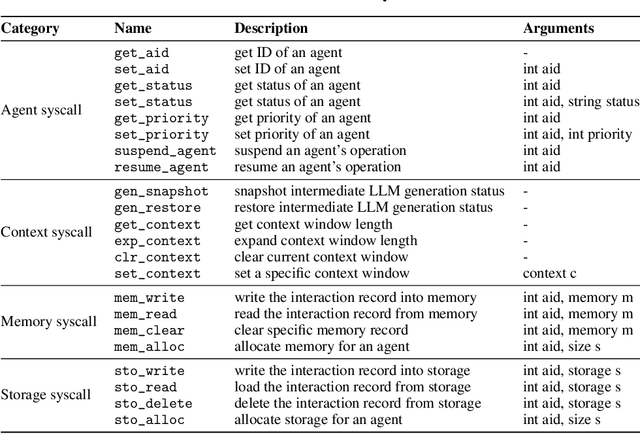
The integration and deployment of large language model (LLM)-based intelligent agents have been fraught with challenges that compromise their efficiency and efficacy. Among these issues are sub-optimal scheduling and resource allocation of agent requests over the LLM, the difficulties in maintaining context during interactions between agent and LLM, and the complexities inherent in integrating heterogeneous agents with different capabilities and specializations. The rapid increase of agent quantity and complexity further exacerbates these issues, often leading to bottlenecks and sub-optimal utilization of resources. Inspired by these challenges, this paper presents AIOS, an LLM agent operating system, which embeds large language model into operating systems (OS) as the brain of the OS, enabling an operating system "with soul" -- an important step towards AGI. Specifically, AIOS is designed to optimize resource allocation, facilitate context switch across agents, enable concurrent execution of agents, provide tool service for agents, and maintain access control for agents. We present the architecture of such an operating system, outline the core challenges it aims to resolve, and provide the basic design and implementation of the AIOS. Our experiments on concurrent execution of multiple agents demonstrate the reliability and efficiency of our AIOS modules. Through this, we aim to not only improve the performance and efficiency of LLM agents but also to pioneer for better development and deployment of the AIOS ecosystem in the future. The project is open-source at https://github.com/agiresearch/AIOS.
Formal-LLM: Integrating Formal Language and Natural Language for Controllable LLM-based Agents
Feb 04, 2024Recent advancements on Large Language Models (LLMs) enable AI Agents to automatically generate and execute multi-step plans to solve complex tasks. However, since LLM's content generation process is hardly controllable, current LLM-based agents frequently generate invalid or non-executable plans, which jeopardizes the performance of the generated plans and corrupts users' trust in LLM-based agents. In response, this paper proposes a novel ``Formal-LLM'' framework for LLM-based agents by integrating the expressiveness of natural language and the precision of formal language. Specifically, the framework allows human users to express their requirements or constraints for the planning process as an automaton. A stack-based LLM plan generation process is then conducted under the supervision of the automaton to ensure that the generated plan satisfies the constraints, making the planning process controllable. We conduct experiments on both benchmark tasks and practical real-life tasks, and our framework achieves over 50% overall performance increase, which validates the feasibility and effectiveness of employing Formal-LLM to guide the plan generation of agents, preventing the agents from generating invalid and unsuccessful plans. Further, more controllable LLM-based agents can facilitate the broader utilization of LLM in application scenarios where high validity of planning is essential. The work is open-sourced at https://github.com/agiresearch/Formal-LLM.
TrustAgent: Towards Safe and Trustworthy LLM-based Agents through Agent Constitution
Feb 02, 2024The emergence of LLM-based agents has garnered considerable attention, yet their trustworthiness remains an under-explored area. As agents can directly interact with the physical environment, their reliability and safety is critical. This paper presents an Agent-Constitution-based agent framework, TrustAgent, an initial investigation into improving the safety dimension of trustworthiness in LLM-based agents. This framework consists of threefold strategies: pre-planning strategy which injects safety knowledge to the model prior to plan generation, in-planning strategy which bolsters safety during plan generation, and post-planning strategy which ensures safety by post-planning inspection. Through experimental analysis, we demonstrate how these approaches can effectively elevate an LLM agent's safety by identifying and preventing potential dangers. Furthermore, we explore the intricate relationships between safety and helpfulness, and between the model's reasoning ability and its efficacy as a safe agent. This paper underscores the imperative of integrating safety awareness and trustworthiness into the design and deployment of LLM-based agents, not only to enhance their performance but also to ensure their responsible integration into human-centric environments. Data and code are available at https://github.com/agiresearch/TrustAgent.