 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
RAGRouter-Bench: A Dataset and Benchmark for Adaptive RAG Routing
Jan 30, 2026Retrieval-Augmented Generation (RAG) has become a core paradigm for grounding large language models with external knowledge. Despite extensive efforts exploring diverse retrieval strategies, existing studies predominantly focus on query-side complexity or isolated method improvements, lacking a systematic understanding of how RAG paradigms behave across different query-corpus contexts and effectiveness-efficiency trade-offs. In this work, we introduce RAGRouter-Bench, the first dataset and benchmark designed for adaptive RAG routing. RAGRouter-Bench revisits retrieval from a query-corpus compatibility perspective and standardizes five representative RAG paradigms for systematic evaluation across 7,727 queries and 21,460 documents spanning diverse domains. The benchmark incorporates three canonical query types together with fine-grained semantic and structural corpus metrics, as well as a unified evaluation for both generation quality and resource consumption. Experiments with DeepSeek-V3 and LLaMA-3.1-8B demonstrate that no single RAG paradigm is universally optimal, that paradigm applicability is strongly shaped by query-corpus interactions, and that increased advanced mechanism does not necessarily yield better effectiveness-efficiency trade-offs. These findings underscore the necessity of routing-aware evaluation and establish a foundation for adaptive, interpretable, and generalizable next-generation RAG systems.
Phenome-Wide Multi-Omics Integration Uncovers Distinct Archetypes of Human Aging
Oct 14, 2025Aging is a highly complex and heterogeneous process that progresses at different rates across individuals, making biological age (BA) a more accurate indicator of physiological decline than chronological age. While previous studies have built aging clocks using single-omics data, they often fail to capture the full molecular complexity of human aging. In this work, we leveraged the Human Phenotype Project, a large-scale cohort of 12,000 adults aged 30--70 years, with extensive longitudinal profiling that includes clinical, behavioral, environmental, and multi-omics datasets -- spanning transcriptomics, lipidomics, metabolomics, and the microbiome. By employing advanced machine learning frameworks capable of modeling nonlinear biological dynamics, we developed and rigorously validated a multi-omics aging clock that robustly predicts diverse health outcomes and future disease risk. Unsupervised clustering of the integrated molecular profiles from multi-omics uncovered distinct biological subtypes of aging, revealing striking heterogeneity in aging trajectories and pinpointing pathway-specific alterations associated with different aging patterns. These findings demonstrate the power of multi-omics integration to decode the molecular landscape of aging and lay the groundwork for personalized healthspan monitoring and precision strategies to prevent age-related diseases.
TAGS: A Test-Time Generalist-Specialist Framework with Retrieval-Augmented Reasoning and Verification
May 23, 2025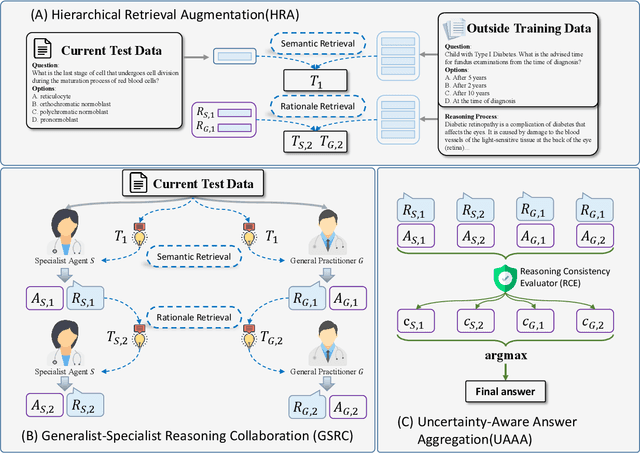
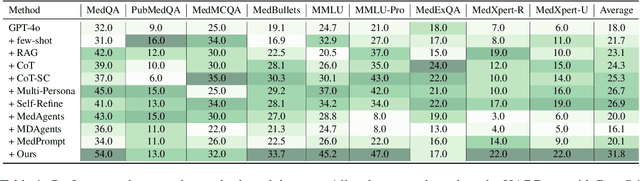
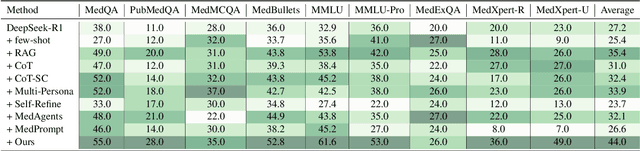
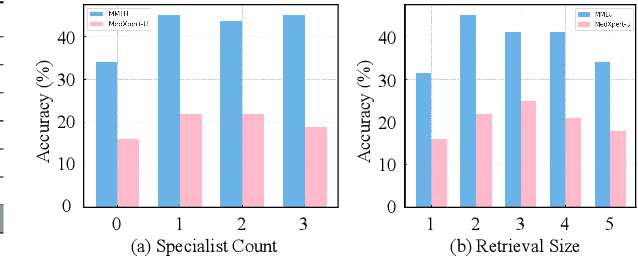
Recent advances such as Chain-of-Thought prompting have significantly improved large language models (LLMs) in zero-shot medical reasoning. However, prompting-based methods often remain shallow and unstable, while fine-tuned medical LLMs suffer from poor generalization under distribution shifts and limited adaptability to unseen clinical scenarios. To address these limitations, we present TAGS, a test-time framework that combines a broadly capable generalist with a domain-specific specialist to offer complementary perspectives without any model fine-tuning or parameter updates. To support this generalist-specialist reasoning process, we introduce two auxiliary modules: a hierarchical retrieval mechanism that provides multi-scale exemplars by selecting examples based on both semantic and rationale-level similarity, and a reliability scorer that evaluates reasoning consistency to guide final answer aggregation. TAGS achieves strong performance across nine MedQA benchmarks, boosting GPT-4o accuracy by 13.8%, DeepSeek-R1 by 16.8%, and improving a vanilla 7B model from 14.1% to 23.9%. These results surpass several fine-tuned medical LLMs, without any parameter updates. The code will be available at https://github.com/JianghaoWu/TAGS.
Rhythm of Opinion: A Hawkes-Graph Framework for Dynamic Propagation Analysis
Apr 21, 2025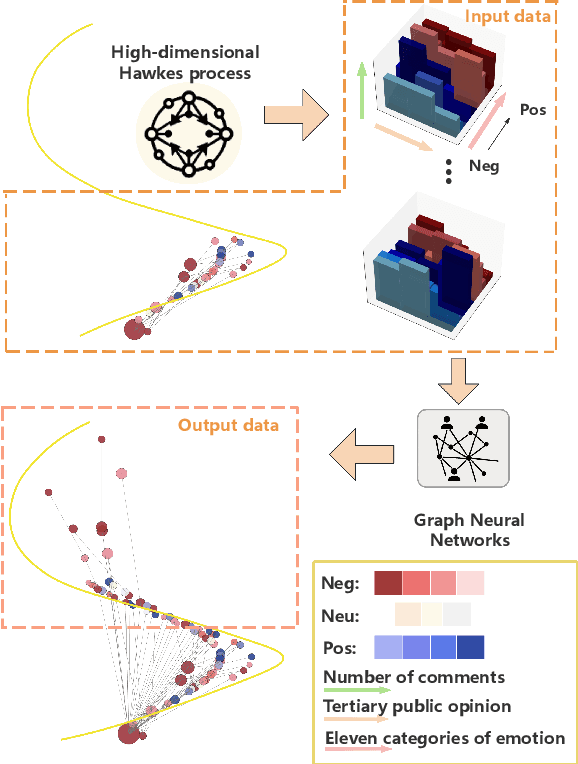
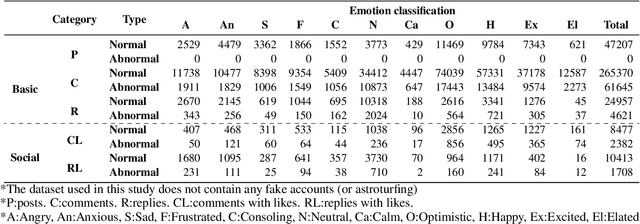
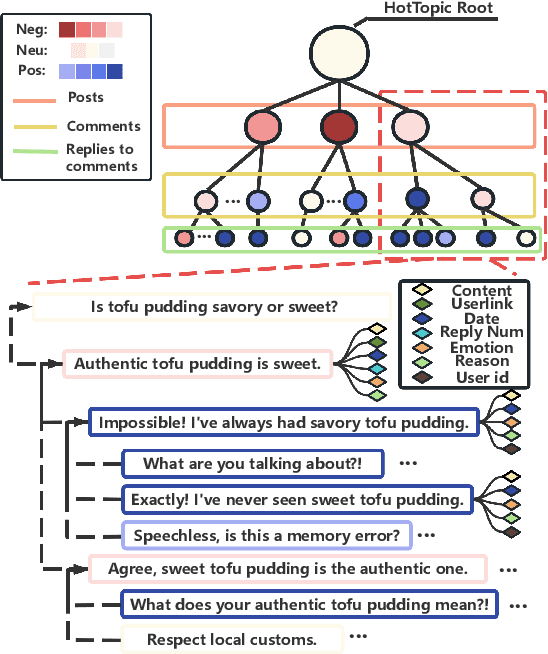
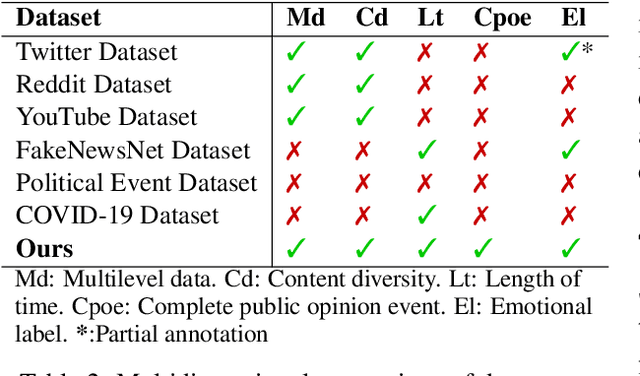
The rapid development of social media has significantly reshaped the dynamics of public opinion, resulting in complex interactions that traditional models fail to effectively capture. To address this challenge, we propose an innovative approach that integrates multi-dimensional Hawkes processes with Graph Neural Network, modeling opinion propagation dynamics among nodes in a social network while considering the intricate hierarchical relationships between comments. The extended multi-dimensional Hawkes process captures the hierarchical structure, multi-dimensional interactions, and mutual influences across different topics, forming a complex propagation network. Moreover, recognizing the lack of high-quality datasets capable of comprehensively capturing the evolution of public opinion dynamics, we introduce a new dataset, VISTA. It includes 159 trending topics, corresponding to 47,207 posts, 327,015 second-level comments, and 29,578 third-level comments, covering diverse domains such as politics, entertainment, sports, health, and medicine. The dataset is annotated with detailed sentiment labels across 11 categories and clearly defined hierarchical relationships. When combined with our method, it offers strong interpretability by linking sentiment propagation to the comment hierarchy and temporal evolution. Our approach provides a robust baseline for future research.
MSWAL: 3D Multi-class Segmentation of Whole Abdominal Lesions Dataset
Mar 17, 2025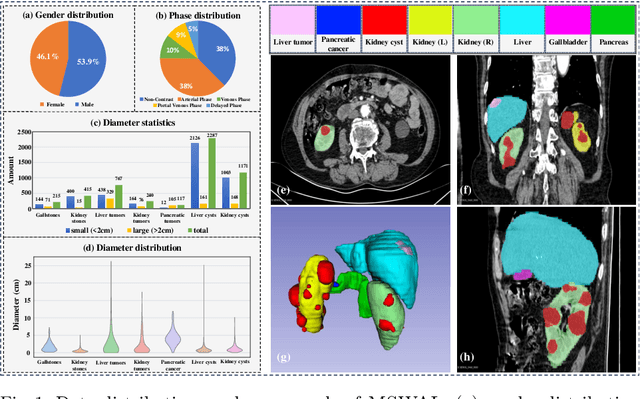
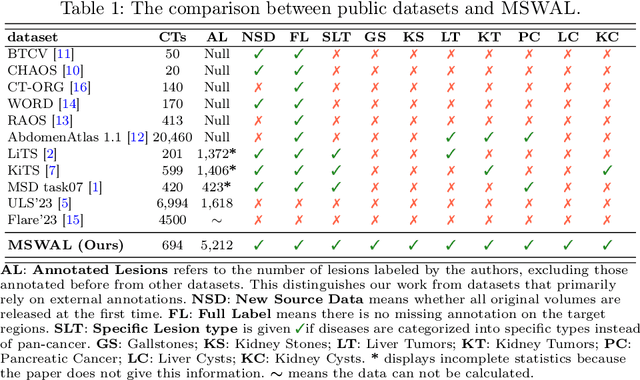
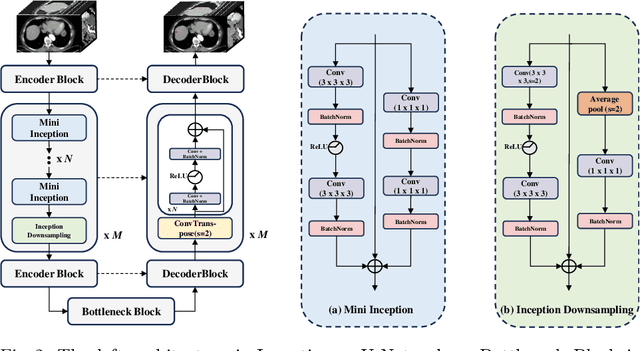
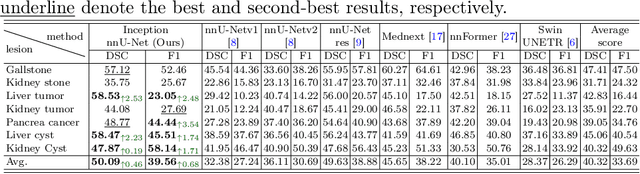
With the significantly increasing incidence and prevalence of abdominal diseases, there is a need to embrace greater use of new innovations and technology for the diagnosis and treatment of patients. Although deep-learning methods have notably been developed to assist radiologists in diagnosing abdominal diseases, existing models have the restricted ability to segment common lesions in the abdomen due to missing annotations for typical abdominal pathologies in their training datasets. To address the limitation, we introduce MSWAL, the first 3D Multi-class Segmentation of the Whole Abdominal Lesions dataset, which broadens the coverage of various common lesion types, such as gallstones, kidney stones, liver tumors, kidney tumors, pancreatic cancer, liver cysts, and kidney cysts. With CT scans collected from 694 patients (191,417 slices) of different genders across various scanning phases, MSWAL demonstrates strong robustness and generalizability. The transfer learning experiment from MSWAL to two public datasets, LiTS and KiTS, effectively demonstrates consistent improvements, with Dice Similarity Coefficient (DSC) increase of 3.00% for liver tumors and 0.89% for kidney tumors, demonstrating that the comprehensive annotations and diverse lesion types in MSWAL facilitate effective learning across different domains and data distributions. Furthermore, we propose Inception nnU-Net, a novel segmentation framework that effectively integrates an Inception module with the nnU-Net architecture to extract information from different receptive fields, achieving significant enhancement in both voxel-level DSC and region-level F1 compared to the cutting-edge public algorithms on MSWAL. Our dataset will be released after being accepted, and the code is publicly released at https://github.com/tiuxuxsh76075/MSWAL-.
LLM as GNN: Graph Vocabulary Learning for Text-Attributed Graph Foundation Models
Mar 05, 2025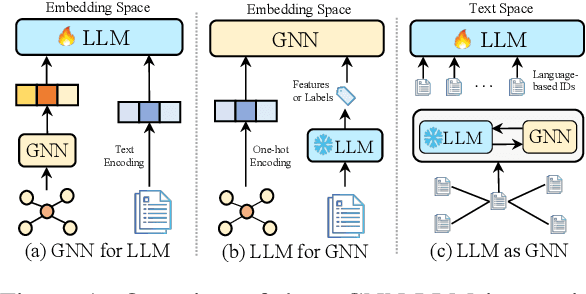
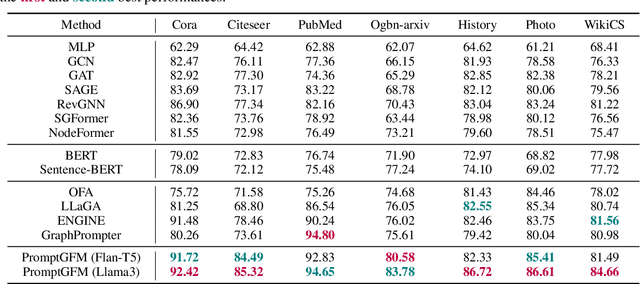
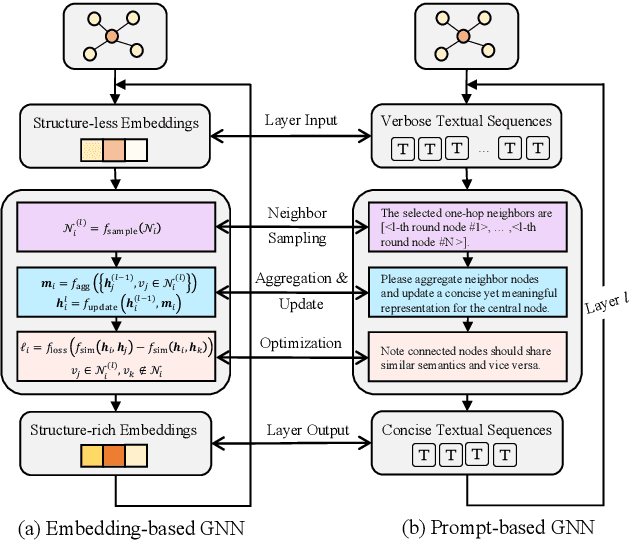
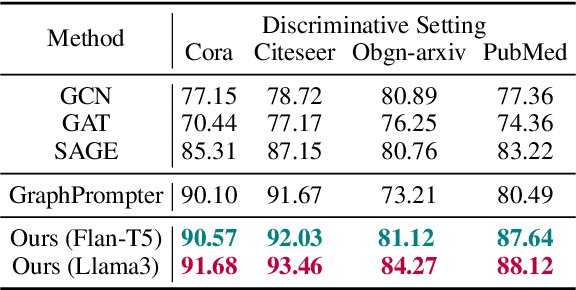
Text-Attributed Graphs (TAGs), where each node is associated with text descriptions, are ubiquitous in real-world scenarios. They typically exhibit distinctive structure and domain-specific knowledge, motivating the development of a Graph Foundation Model (GFM) that generalizes across diverse graphs and tasks. Despite large efforts to integrate Large Language Models (LLMs) and Graph Neural Networks (GNNs) for TAGs, existing approaches suffer from decoupled architectures with two-stage alignment, limiting their synergistic potential. Even worse, existing methods assign out-of-vocabulary (OOV) tokens to graph nodes, leading to graph-specific semantics, token explosion, and incompatibility with task-oriented prompt templates, which hinders cross-graph and cross-task transferability. To address these challenges, we propose PromptGFM, a versatile GFM for TAGs grounded in graph vocabulary learning. PromptGFM comprises two key components: (1) Graph Understanding Module, which explicitly prompts LLMs to replicate the finest GNN workflow within the text space, facilitating seamless GNN-LLM integration and elegant graph-text alignment; (2) Graph Inference Module, which establishes a language-based graph vocabulary ensuring expressiveness, transferability, and scalability, enabling readable instructions for LLM fine-tuning. Extensive experiments demonstrate our superiority and transferability across diverse graphs and tasks. The code is available at this: https://github.com/agiresearch/PromptGFM.
MMRC: A Large-Scale Benchmark for Understanding Multimodal Large Language Model in Real-World Conversation
Feb 17, 2025Recent multimodal large language models (MLLMs) have demonstrated significant potential in open-ended conversation, generating more accurate and personalized responses. However, their abilities to memorize, recall, and reason in sustained interactions within real-world scenarios remain underexplored. This paper introduces MMRC, a Multi-Modal Real-world Conversation benchmark for evaluating six core open-ended abilities of MLLMs: information extraction, multi-turn reasoning, information update, image management, memory recall, and answer refusal. With data collected from real-world scenarios, MMRC comprises 5,120 conversations and 28,720 corresponding manually labeled questions, posing a significant challenge to existing MLLMs. Evaluations on 20 MLLMs in MMRC indicate an accuracy drop during open-ended interactions. We identify four common failure patterns: long-term memory degradation, inadequacies in updating factual knowledge, accumulated assumption of error propagation, and reluctance to say no. To mitigate these issues, we propose a simple yet effective NOTE-TAKING strategy, which can record key information from the conversation and remind the model during its responses, enhancing conversational capabilities. Experiments across six MLLMs demonstrate significant performance improvements.
Beyond Words: AuralLLM and SignMST-C for Precise Sign Language Production and Bidirectional Accessibility
Jan 01, 2025
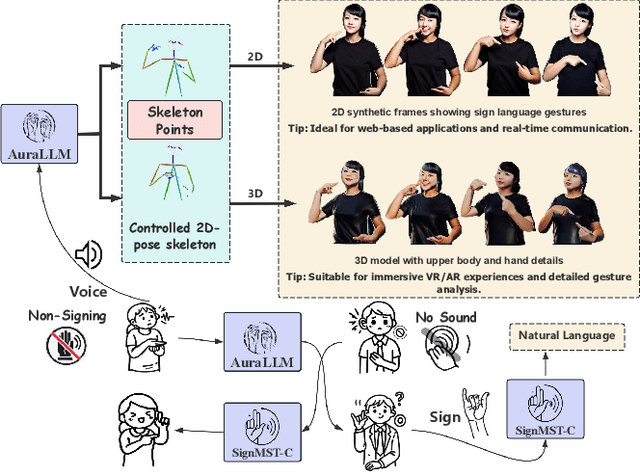


Although sign language recognition aids non-hearing-impaired understanding, many hearing-impaired individuals still rely on sign language alone due to limited literacy, underscoring the need for advanced sign language production and translation (SLP and SLT) systems. In the field of sign language production, the lack of adequate models and datasets restricts practical applications. Existing models face challenges in production accuracy and pose control, making it difficult to provide fluent sign language expressions across diverse scenarios. Additionally, data resources are scarce, particularly high-quality datasets with complete sign vocabulary and pose annotations. To address these issues, we introduce CNText2Sign and CNSign, comprehensive datasets to benchmark SLP and SLT, respectively, with CNText2Sign covering gloss and landmark mappings for SLP, and CNSign providing extensive video-to-text data for SLT. To improve the accuracy and applicability of sign language systems, we propose the AuraLLM and SignMST-C models. AuraLLM, incorporating LoRA and RAG techniques, achieves a BLEU-4 score of 50.41 on the CNText2Sign dataset, enabling precise control over gesture semantics and motion. SignMST-C employs self-supervised rapid motion video pretraining, achieving a BLEU-4 score of 31.03/32.08 on the PHOENIX2014-T benchmark, setting a new state-of-the-art. These models establish robust baselines for the datasets released for their respective tasks.
Multi-task Prompt Words Learning for Social Media Content Generation
Jul 10, 2024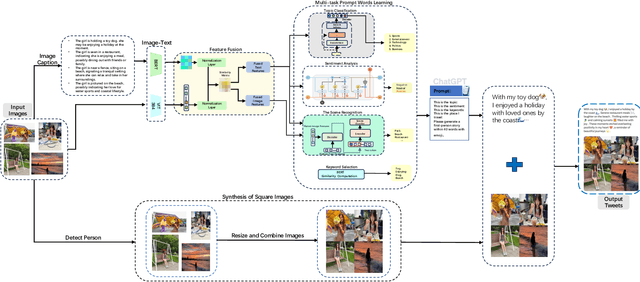
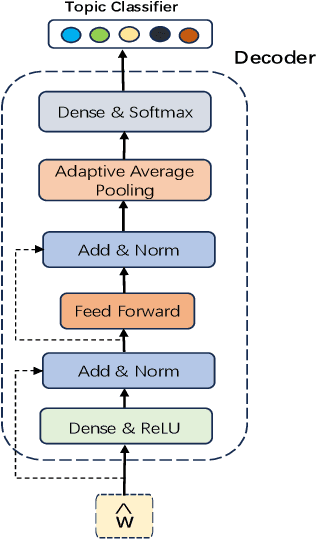
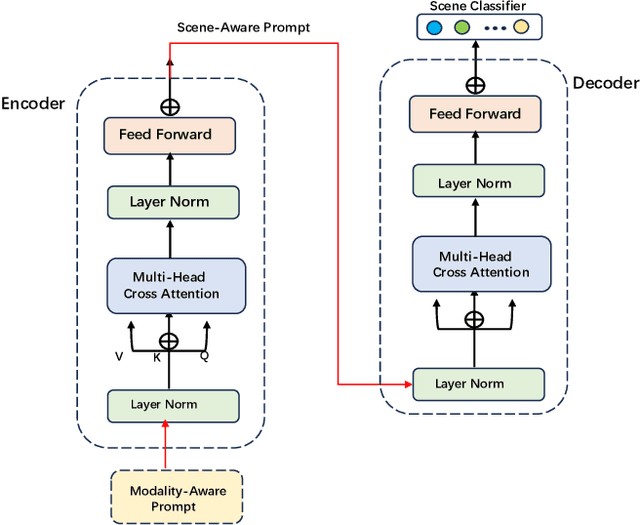
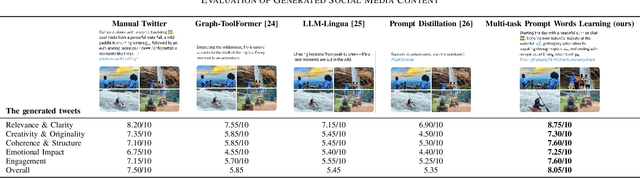
The rapid development of the Internet has profoundly changed human life. Humans are increasingly expressing themselves and interacting with others on social media platforms. However, although artificial intelligence technology has been widely used in many aspects of life, its application in social media content creation is still blank. To solve this problem, we propose a new prompt word generation framework based on multi-modal information fusion, which combines multiple tasks including topic classification, sentiment analysis, scene recognition and keyword extraction to generate more comprehensive prompt words. Subsequently, we use a template containing a set of prompt words to guide ChatGPT to generate high-quality tweets. Furthermore, in the absence of effective and objective evaluation criteria in the field of content generation, we use the ChatGPT tool to evaluate the results generated by the algorithm, making large-scale evaluation of content generation algorithms possible. Evaluation results on extensive content generation demonstrate that our cue word generation framework generates higher quality content compared to manual methods and other cueing techniques, while topic classification, sentiment analysis, and scene recognition significantly enhance content clarity and its consistency with the image.
* 8 pages, 5 figures