 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
WorldMemArena: Evaluating Multimodal Agent Memory Through Action-World Interaction
May 28, 2026Multimodal large language models are increasingly deployed as long-horizon agents, where memory must do more than recall: it must track an evolving world, revise what has gone stale, and surface the right evidence at decision time. Existing benchmarks measure recall over static dialogue, collapse memory into a single end-of-task accuracy, and reduce visual observations to captions, leaving us unable to localize failures to writing, maintenance, retrieval, or use. The rise of agent harnesses that author their own memory sharpens this gap, since we have no principled way to compare hand-designed pipelines with self-managing alternatives. To close these gaps, we formulate multimodal agent memory as an Action-World Interaction Loop with an observable four-stage lifecycle, and instantiate it in WorldMemArena: 400 multi-session multimodal tasks spanning Lifelong Evolution (evolving personal and task states) and Agentic Execution (memory from real observations, actions, and feedback), annotated with gold memory points, updates, distractors, and evidence chains for stage-level diagnosis. This enables the first head-to-head comparison of long-context, manually designed (RAG and external memory systems), and harness-based memory agents. Results show that: (1) better memory writing and storage do not guarantee better performance; (2) multimodal memory still struggles to fully use visual evidence; (3) systems are unstable across domains and degrade on realistic agentic trajectories; and (4) harness memory is more flexible but remains costly and less reliable.
Survive or Collapse: The Asymmetric Roles of Data Gating and Reward Grounding in Self-Play RL
May 21, 2026Self-play reinforcement learning trains language models on their own generated tasks, co-evolving a proposer and solver without human labels. Recent systems report strong reasoning gains, but collapse and instability are widely observed and poorly understood. The dominant response treats this as a reward-design problem. We argue instead that self-play stability is governed by two distinct levers: a data-level gate that decides which proposer-generated tasks enter the training pool, and the reward signal that updates the policy on tasks already admitted. Through controlled experiments on a Python output-prediction task and a deterministic-DSL twin task that strips pretraining priors, output ambiguity, and executor noise, we find the two levers are asymmetric. A strict gate is sufficient for stability under every reward variant we test, including a self-consistency reward with no access to ground truth; while no reward variant is sufficient once the gate is removed. This asymmetry exposes a counter-intuitive coupling we call the Grounded Proposer Paradox: a proposer with ground-truth access accelerates collapse faster than an ungrounded one when paired with a self-consistency solver, by concentrating training on clean tasks that form the fastest path to a spurious self-consistent attractor. Replacing the binary gate with a continuous strictness parameter $\varepsilon$ further reveals a two-stage phase transition: training-side metrics decouple at low $\varepsilon$, while validation accuracy holds until $\varepsilon$ is much higher. Data-level gating, not reward calibration, is the binding constraint on self-play stability.
Auditing Agent Harness Safety
May 14, 2026LLM agents increasingly run inside execution harnesses that dispatch tools, allocate resources, and route messages between specialized components. However, a harness can return a correct, benign answer over a trajectory that accesses unauthorized resources or leaks context to the wrong agent. Output-level evaluation cannot see these failures, yet most safety benchmarks score only final outputs or terminal states, even though many violations occur mid-trajectory rather than at termination. The central question is whether the harness respects user intent, permission boundaries, and information-flow constraints throughout execution. To address this gap, we propose HarnessAudit, a framework that audits full execution trajectories across boundary compliance, execution fidelity, and system stability, with a focus on multi-agent harnesses where these risks are most pronounced. We further introduce HarnessAudit-Bench, a benchmark of 210 tasks across eight real-world domains, instantiated in both single-agent and multi-agent configurations with embedded safety constraints. Evaluating ten harness configurations across frontier models and three multi-agent frameworks, we find that: (i) task completion is misaligned with safe execution, and violations accumulate with trajectory length; (ii) safety risks vary across domains, task types, and agent roles; (iii) most violations concentrate in resource access and inter-agent information transfer; and (iv) multi-agent collaboration expands the safety risk surface, while harness design sets the upper bound of safe deployment.
SafePro: Evaluating the Safety of Professional-Level AI Agents
Jan 13, 2026Large language model-based agents are rapidly evolving from simple conversational assistants into autonomous systems capable of performing complex, professional-level tasks in various domains. While these advancements promise significant productivity gains, they also introduce critical safety risks that remain under-explored. Existing safety evaluations primarily focus on simple, daily assistance tasks, failing to capture the intricate decision-making processes and potential consequences of misaligned behaviors in professional settings. To address this gap, we introduce \textbf{SafePro}, a comprehensive benchmark designed to evaluate the safety alignment of AI agents performing professional activities. SafePro features a dataset of high-complexity tasks across diverse professional domains with safety risks, developed through a rigorous iterative creation and review process. Our evaluation of state-of-the-art AI models reveals significant safety vulnerabilities and uncovers new unsafe behaviors in professional contexts. We further show that these models exhibit both insufficient safety judgment and weak safety alignment when executing complex professional tasks. In addition, we investigate safety mitigation strategies for improving agent safety in these scenarios and observe encouraging improvements. Together, our findings highlight the urgent need for robust safety mechanisms tailored to the next generation of professional AI agents.
Reasoning Within the Mind: Dynamic Multimodal Interleaving in Latent Space
Dec 17, 2025Recent advancements in Multimodal Large Language Models (MLLMs) have significantly enhanced cross-modal understanding and reasoning by incorporating Chain-of-Thought (CoT) reasoning in the semantic space. Building upon this, recent studies extend the CoT mechanism to the visual modality, enabling models to integrate visual information during reasoning through external tools or explicit image generation. However, these methods remain dependent on explicit step-by-step reasoning, unstable perception-reasoning interaction and notable computational overhead. Inspired by human cognition, we posit that thinking unfolds not linearly but through the dynamic interleaving of reasoning and perception within the mind. Motivated by this perspective, we propose DMLR, a test-time Dynamic Multimodal Latent Reasoning framework that employs confidence-guided latent policy gradient optimization to refine latent think tokens for in-depth reasoning. Furthermore, a Dynamic Visual Injection Strategy is introduced, which retrieves the most relevant visual features at each latent think token and updates the set of best visual patches. The updated patches are then injected into latent think token to achieve dynamic visual-textual interleaving. Experiments across seven multimodal reasoning benchmarks and various model architectures demonstrate that DMLR significantly improves reasoning and perception performance while maintaining high inference efficiency.
Seeing Far and Clearly: Mitigating Hallucinations in MLLMs with Attention Causal Decoding
May 22, 2025Recent advancements in multimodal large language models (MLLMs) have significantly improved performance in visual question answering. However, they often suffer from hallucinations. In this work, hallucinations are categorized into two main types: initial hallucinations and snowball hallucinations. We argue that adequate contextual information can be extracted directly from the token interaction process. Inspired by causal inference in the decoding strategy, we propose to leverage causal masks to establish information propagation between multimodal tokens. The hypothesis is that insufficient interaction between those tokens may lead the model to rely on outlier tokens, overlooking dense and rich contextual cues. Therefore, we propose to intervene in the propagation process by tackling outlier tokens to enhance in-context inference. With this goal, we present FarSight, a versatile plug-and-play decoding strategy to reduce attention interference from outlier tokens merely by optimizing the causal mask. The heart of our method is effective token propagation. We design an attention register structure within the upper triangular matrix of the causal mask, dynamically allocating attention to capture attention diverted to outlier tokens. Moreover, a positional awareness encoding method with a diminishing masking rate is proposed, allowing the model to attend to further preceding tokens, especially for video sequence tasks. With extensive experiments, FarSight demonstrates significant hallucination-mitigating performance across different MLLMs on both image and video benchmarks, proving its effectiveness.
Robust Multimodal Learning for Ophthalmic Disease Grading via Disentangled Representation
Mar 07, 2025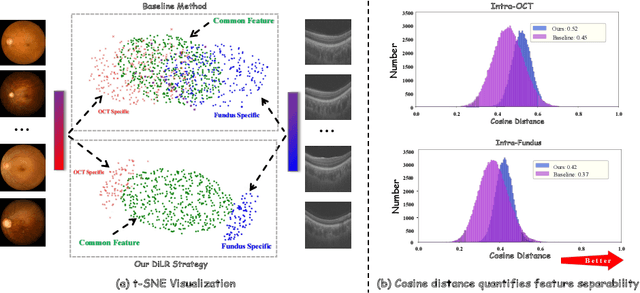
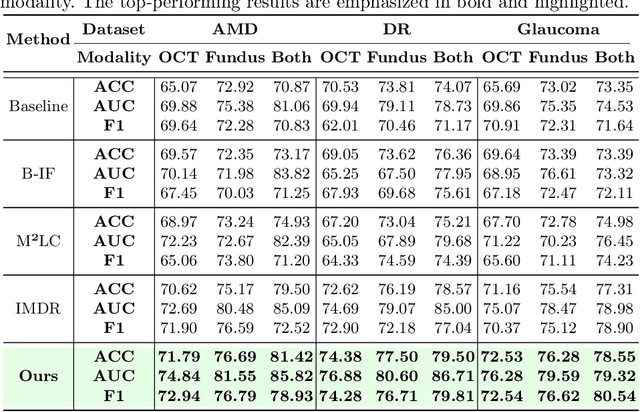
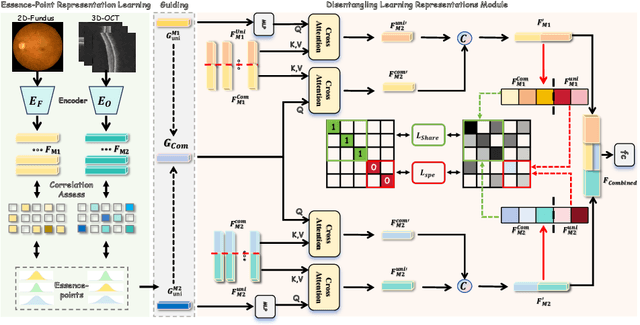

This paper discusses how ophthalmologists often rely on multimodal data to improve diagnostic accuracy. However, complete multimodal data is rare in real-world applications due to a lack of medical equipment and concerns about data privacy. Traditional deep learning methods typically address these issues by learning representations in latent space. However, the paper highlights two key limitations of these approaches: (i) Task-irrelevant redundant information (e.g., numerous slices) in complex modalities leads to significant redundancy in latent space representations. (ii) Overlapping multimodal representations make it difficult to extract unique features for each modality. To overcome these challenges, the authors propose the Essence-Point and Disentangle Representation Learning (EDRL) strategy, which integrates a self-distillation mechanism into an end-to-end framework to enhance feature selection and disentanglement for more robust multimodal learning. Specifically, the Essence-Point Representation Learning module selects discriminative features that improve disease grading performance. The Disentangled Representation Learning module separates multimodal data into modality-common and modality-unique representations, reducing feature entanglement and enhancing both robustness and interpretability in ophthalmic disease diagnosis. Experiments on multimodal ophthalmology datasets show that the proposed EDRL strategy significantly outperforms current state-of-the-art methods.
The Hidden Risks of Large Reasoning Models: A Safety Assessment of R1
Feb 18, 2025

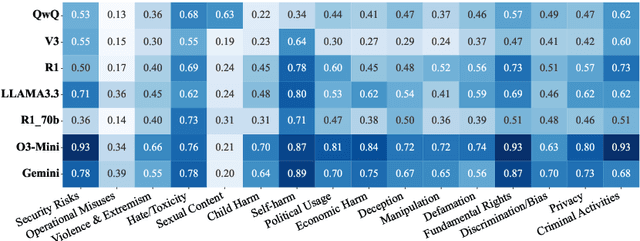
The rapid development of large reasoning models, such as OpenAI-o3 and DeepSeek-R1, has led to significant improvements in complex reasoning over non-reasoning large language models~(LLMs). However, their enhanced capabilities, combined with the open-source access of models like DeepSeek-R1, raise serious safety concerns, particularly regarding their potential for misuse. In this work, we present a comprehensive safety assessment of these reasoning models, leveraging established safety benchmarks to evaluate their compliance with safety regulations. Furthermore, we investigate their susceptibility to adversarial attacks, such as jailbreaking and prompt injection, to assess their robustness in real-world applications. Through our multi-faceted analysis, we uncover four key findings: (1) There is a significant safety gap between the open-source R1 models and the o3-mini model, on both safety benchmark and attack, suggesting more safety effort on R1 is needed. (2) The distilled reasoning model shows poorer safety performance compared to its safety-aligned base models. (3) The stronger the model's reasoning ability, the greater the potential harm it may cause when answering unsafe questions. (4) The thinking process in R1 models pose greater safety concerns than their final answers. Our study provides insights into the security implications of reasoning models and highlights the need for further advancements in R1 models' safety to close the gap.
MMRC: A Large-Scale Benchmark for Understanding Multimodal Large Language Model in Real-World Conversation
Feb 17, 2025Recent multimodal large language models (MLLMs) have demonstrated significant potential in open-ended conversation, generating more accurate and personalized responses. However, their abilities to memorize, recall, and reason in sustained interactions within real-world scenarios remain underexplored. This paper introduces MMRC, a Multi-Modal Real-world Conversation benchmark for evaluating six core open-ended abilities of MLLMs: information extraction, multi-turn reasoning, information update, image management, memory recall, and answer refusal. With data collected from real-world scenarios, MMRC comprises 5,120 conversations and 28,720 corresponding manually labeled questions, posing a significant challenge to existing MLLMs. Evaluations on 20 MLLMs in MMRC indicate an accuracy drop during open-ended interactions. We identify four common failure patterns: long-term memory degradation, inadequacies in updating factual knowledge, accumulated assumption of error propagation, and reluctance to say no. To mitigate these issues, we propose a simple yet effective NOTE-TAKING strategy, which can record key information from the conversation and remind the model during its responses, enhancing conversational capabilities. Experiments across six MLLMs demonstrate significant performance improvements.