 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOFA-FL: Self-Organizing Hierarchical Federated Learning with Adaptive Clustered Data Sharing
Dec 09, 2025Federated Learning (FL) faces significant challenges in evolving environments, particularly regarding data heterogeneity and the rigidity of fixed network topologies. To address these issues, this paper proposes \textbf{SOFA-FL} (Self-Organizing Hierarchical Federated Learning with Adaptive Clustered Data Sharing), a novel framework that enables hierarchical federated systems to self-organize and adapt over time. The framework is built upon three core mechanisms: (1) \textbf{Dynamic Multi-branch Agglomerative Clustering (DMAC)}, which constructs an initial efficient hierarchical structure; (2) \textbf{Self-organizing Hierarchical Adaptive Propagation and Evolution (SHAPE)}, which allows the system to dynamically restructure its topology through atomic operations -- grafting, pruning, consolidation, and purification -- to adapt to changes in data distribution; and (3) \textbf{Adaptive Clustered Data Sharing}, which mitigates data heterogeneity by enabling controlled partial data exchange between clients and cluster nodes. By integrating these mechanisms, SOFA-FL effectively captures dynamic relationships among clients and enhances personalization capabilities without relying on predetermined cluster structures.
HiFusion: Hierarchical Intra-Spot Alignment and Regional Context Fusion for Spatial Gene Expression Prediction from Histopathology
Nov 19, 2025Spatial transcriptomics (ST) bridges gene expression and tissue morphology but faces clinical adoption barriers due to technical complexity and prohibitive costs. While computational methods predict gene expression from H&E-stained whole-slide images (WSIs), existing approaches often fail to capture the intricate biological heterogeneity within spots and are susceptible to morphological noise when integrating contextual information from surrounding tissue. To overcome these limitations, we propose HiFusion, a novel deep learning framework that integrates two complementary components. First, we introduce the Hierarchical Intra-Spot Modeling module that extracts fine-grained morphological representations through multi-resolution sub-patch decomposition, guided by a feature alignment loss to ensure semantic consistency across scales. Concurrently, we present the Context-aware Cross-scale Fusion module, which employs cross-attention to selectively incorporate biologically relevant regional context, thereby enhancing representational capacity. This architecture enables comprehensive modeling of both cellular-level features and tissue microenvironmental cues, which are essential for accurate gene expression prediction. Extensive experiments on two benchmark ST datasets demonstrate that HiFusion achieves state-of-the-art performance across both 2D slide-wise cross-validation and more challenging 3D sample-specific scenarios. These results underscore HiFusion's potential as a robust, accurate, and scalable solution for ST inference from routine histopathology.
Sparser2Sparse: Single-shot Sparser-to-Sparse Learning for Spatial Transcriptomics Imputation with Natural Image Co-learning
Jul 22, 2025Spatial transcriptomics (ST) has revolutionized biomedical research by enabling high resolution gene expression profiling within tissues. However, the high cost and scarcity of high resolution ST data remain significant challenges. We present Single-shot Sparser-to-Sparse (S2S-ST), a novel framework for accurate ST imputation that requires only a single and low-cost sparsely sampled ST dataset alongside widely available natural images for co-training. Our approach integrates three key innovations: (1) a sparser-to-sparse self-supervised learning strategy that leverages intrinsic spatial patterns in ST data, (2) cross-domain co-learning with natural images to enhance feature representation, and (3) a Cascaded Data Consistent Imputation Network (CDCIN) that iteratively refines predictions while preserving sampled gene data fidelity. Extensive experiments on diverse tissue types, including breast cancer, liver, and lymphoid tissue, demonstrate that our method outperforms state-of-the-art approaches in imputation accuracy. By enabling robust ST reconstruction from sparse inputs, our framework significantly reduces reliance on costly high resolution data, facilitating potential broader adoption in biomedical research and clinical applications.
Robust Multimodal Learning for Ophthalmic Disease Grading via Disentangled Representation
Mar 07, 2025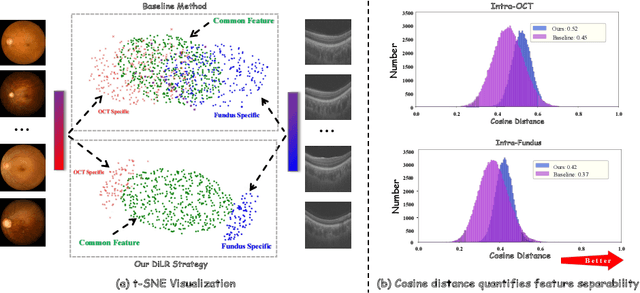
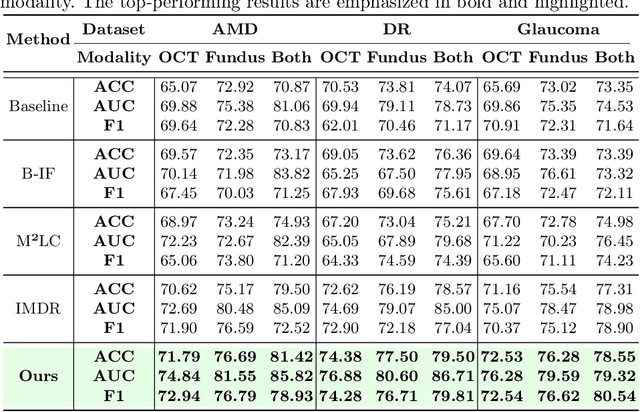
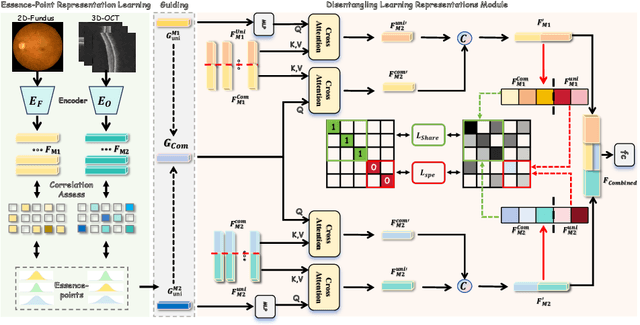

This paper discusses how ophthalmologists often rely on multimodal data to improve diagnostic accuracy. However, complete multimodal data is rare in real-world applications due to a lack of medical equipment and concerns about data privacy. Traditional deep learning methods typically address these issues by learning representations in latent space. However, the paper highlights two key limitations of these approaches: (i) Task-irrelevant redundant information (e.g., numerous slices) in complex modalities leads to significant redundancy in latent space representations. (ii) Overlapping multimodal representations make it difficult to extract unique features for each modality. To overcome these challenges, the authors propose the Essence-Point and Disentangle Representation Learning (EDRL) strategy, which integrates a self-distillation mechanism into an end-to-end framework to enhance feature selection and disentanglement for more robust multimodal learning. Specifically, the Essence-Point Representation Learning module selects discriminative features that improve disease grading performance. The Disentangled Representation Learning module separates multimodal data into modality-common and modality-unique representations, reducing feature entanglement and enhancing both robustness and interpretability in ophthalmic disease diagnosis. Experiments on multimodal ophthalmology datasets show that the proposed EDRL strategy significantly outperforms current state-of-the-art methods.
ProMISe: Promptable Medical Image Segmentation using SAM
Mar 07, 2024



With the proposal of the Segment Anything Model (SAM), fine-tuning SAM for medical image segmentation (MIS) has become popular. However, due to the large size of the SAM model and the significant domain gap between natural and medical images, fine-tuning-based strategies are costly with potential risk of instability, feature damage and catastrophic forgetting. Furthermore, some methods of transferring SAM to a domain-specific MIS through fine-tuning strategies disable the model's prompting capability, severely limiting its utilization scenarios. In this paper, we propose an Auto-Prompting Module (APM), which provides SAM-based foundation model with Euclidean adaptive prompts in the target domain. Our experiments demonstrate that such adaptive prompts significantly improve SAM's non-fine-tuned performance in MIS. In addition, we propose a novel non-invasive method called Incremental Pattern Shifting (IPS) to adapt SAM to specific medical domains. Experimental results show that the IPS enables SAM to achieve state-of-the-art or competitive performance in MIS without the need for fine-tuning. By coupling these two methods, we propose ProMISe, an end-to-end non-fine-tuned framework for Promptable Medical Image Segmentation. Our experiments demonstrate that both using our methods individually or in combination achieves satisfactory performance in low-cost pattern shifting, with all of SAM's parameters frozen.