 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat if LLMs Have Different World Views: Simulating Alien Civilizations with LLM-based Agents
Feb 21, 2024



In this study, we introduce "CosmoAgent," an innovative artificial intelligence framework utilizing Large Language Models (LLMs) to simulate complex interactions between human and extraterrestrial civilizations, with a special emphasis on Stephen Hawking's cautionary advice about not sending radio signals haphazardly into the universe. The goal is to assess the feasibility of peaceful coexistence while considering potential risks that could threaten well-intentioned civilizations. Employing mathematical models and state transition matrices, our approach quantitatively evaluates the development trajectories of civilizations, offering insights into future decision-making at critical points of growth and saturation. Furthermore, the paper acknowledges the vast diversity in potential living conditions across the universe, which could foster unique cosmologies, ethical codes, and worldviews among various civilizations. Recognizing the Earth-centric bias inherent in current LLM designs, we propose the novel concept of using LLMs with diverse ethical paradigms and simulating interactions between entities with distinct moral principles. This innovative research provides a new way to understand complex inter-civilizational dynamics, expanding our perspective while pioneering novel strategies for conflict resolution, crucial for preventing interstellar conflicts. We have also released the code and datasets to enable further academic investigation into this interesting area of research. The code is available at https://github.com/agiresearch/AlienAgent.
Time Series Forecasting with LLMs: Understanding and Enhancing Model Capabilities
Feb 19, 2024



Large language models (LLMs) have been applied in many fields with rapid development in recent years. As a classic machine learning task, time series forecasting has recently received a boost from LLMs. However, there is a research gap in the LLMs' preferences in this field. In this paper, by comparing LLMs with traditional models, many properties of LLMs in time series prediction are found. For example, our study shows that LLMs excel in predicting time series with clear patterns and trends but face challenges with datasets lacking periodicity. We explain our findings through designing prompts to require LLMs to tell the period of the datasets. In addition, the input strategy is investigated, and it is found that incorporating external knowledge and adopting natural language paraphrases positively affects the predictive performance of LLMs for time series. Overall, this study contributes to insight into the advantages and limitations of LLMs in time series forecasting under different conditions.
A Theoretical Approach to Characterize the Accuracy-Fairness Trade-off Pareto Frontier
Oct 19, 2023



While the accuracy-fairness trade-off has been frequently observed in the literature of fair machine learning, rigorous theoretical analyses have been scarce. To demystify this long-standing challenge, this work seeks to develop a theoretical framework by characterizing the shape of the accuracy-fairness trade-off Pareto frontier (FairFrontier), determined by a set of all optimal Pareto classifiers that no other classifiers can dominate. Specifically, we first demonstrate the existence of the trade-off in real-world scenarios and then propose four potential categories to characterize the important properties of the accuracy-fairness Pareto frontier. For each category, we identify the necessary conditions that lead to corresponding trade-offs. Experimental results on synthetic data suggest insightful findings of the proposed framework: (1) When sensitive attributes can be fully interpreted by non-sensitive attributes, FairFrontier is mostly continuous. (2) Accuracy can suffer a \textit{sharp} decline when over-pursuing fairness. (3) Eliminate the trade-off via a two-step streamlined approach. The proposed research enables an in-depth understanding of the accuracy-fairness trade-off, pushing current fair machine-learning research to a new frontier.
Improving genetic risk prediction across diverse population by disentangling ancestry representations
May 10, 2022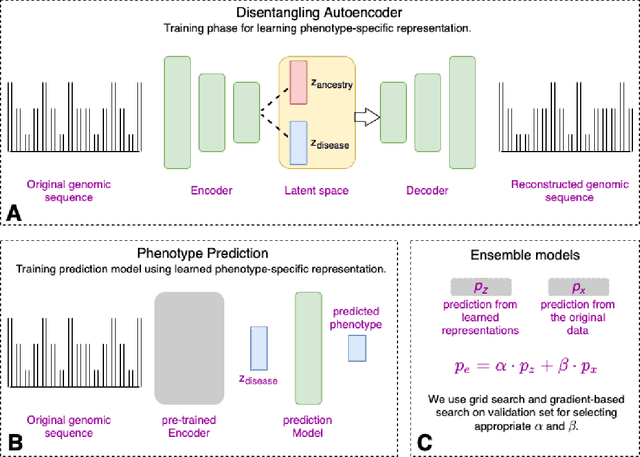
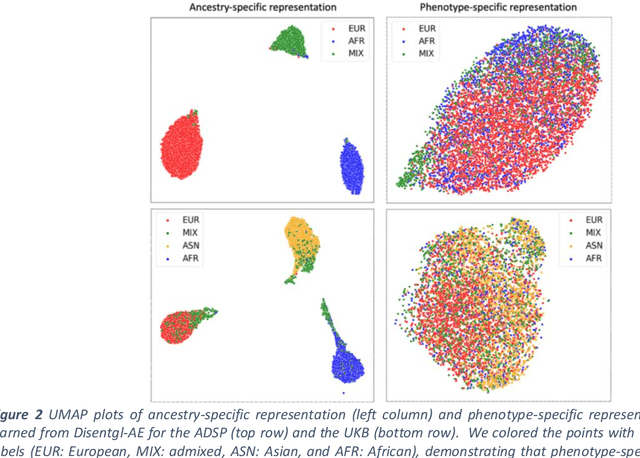
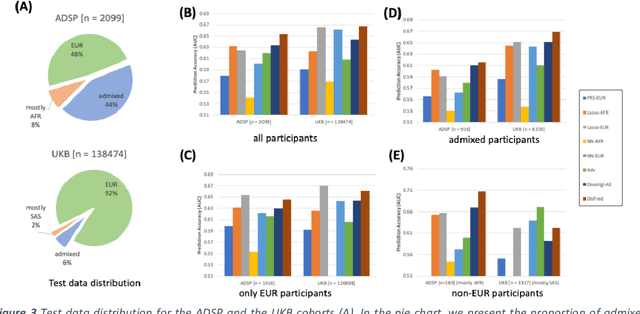
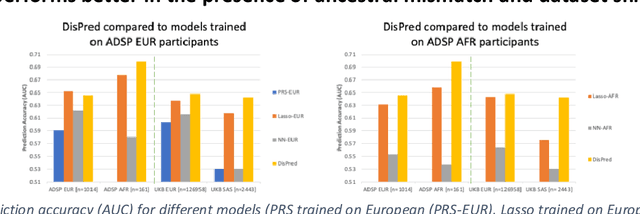
Risk prediction models using genetic data have seen increasing traction in genomics. However, most of the polygenic risk models were developed using data from participants with similar (mostly European) ancestry. This can lead to biases in the risk predictors resulting in poor generalization when applied to minority populations and admixed individuals such as African Americans. To address this bias, largely due to the prediction models being confounded by the underlying population structure, we propose a novel deep-learning framework that leverages data from diverse population and disentangles ancestry from the phenotype-relevant information in its representation. The ancestry disentangled representation can be used to build risk predictors that perform better across minority populations. We applied the proposed method to the analysis of Alzheimer's disease genetics. Comparing with standard linear and nonlinear risk prediction methods, the proposed method substantially improves risk prediction in minority populations, particularly for admixed individuals.