 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Fine-Grained Prototype Learning for Incomplete Image-Tabular Classification
Jun 03, 2026The missing-modality problem poses a significant challenge in image-tabular multimodal learning across a wide range of multimedia applications, including product understanding, recommendation systems, and medical diagnosis. This challenge is particularly pronounced when the two modalities are highly heterogeneous, as images and tabular attributes differ substantially in their semantic granularity and data distributions. Existing methods learn modality-invariant representations through disentanglement and alignment over global token-averaged features, capturing only coarse cross-modal consistency and overlooking fine-grained semantic and distributional misalignment, which hampers the exploitation of complementary cues under missing modalities. To address this, we propose DFPL, a novel framework for fine-grained prototype learning. Specifically, Shared-Specific Prototype Modeling (SSPM) extracts compact and diverse shared and modality-specific prototypes, and further performs prototype-level disentanglement to suppress redundant intra-modality correlations. Additionally, we propose a Prototype-guided Fine-grained Alignment (PFA) module that jointly enforces prototype-level distribution matching and prototype-to-class semantic alignment within a unified prototype space, thereby preserving both fine-grained distributional and semantic consistency across modalities. We further introduce a Class-aware Multi-scale Aggregation (CMA) module to adaptively aggregate shared semantics and modality-specific characteristics from global and prototype levels for robust predictions. Extensive experiments on three diverse image-tabular benchmarks demonstrate the superiority of our method compared to the previous approaches under various missing-modality settings. Code will be made publicly available.
Leveraging Persistence Image to Enhance Robustness and Performance in Curvilinear Structure Segmentation
Jan 25, 2026Segmenting curvilinear structures in medical images is essential for analyzing morphological patterns in clinical applications. Integrating topological properties, such as connectivity, improves segmentation accuracy and consistency. However, extracting and embedding such properties - especially from Persistence Diagrams (PD) - is challenging due to their non-differentiability and computational cost. Existing approaches mostly encode topology through handcrafted loss functions, which generalize poorly across tasks. In this paper, we propose PIs-Regressor, a simple yet effective module that learns persistence image (PI) - finite, differentiable representations of topological features - directly from data. Together with Topology SegNet, which fuses these features in both downsampling and upsampling stages, our framework integrates topology into the network architecture itself rather than auxiliary losses. Unlike existing methods that depend heavily on handcrafted loss functions, our approach directly incorporates topological information into the network structure, leading to more robust segmentation. Our design is flexible and can be seamlessly combined with other topology-based methods to further enhance segmentation performance. Experimental results show that integrating topological features enhances model robustness, effectively handling challenges like overexposure and blurring in medical imaging. Our approach on three curvilinear benchmarks demonstrate state-of-the-art performance in both pixel-level accuracy and topological fidelity.
StealthMark: Harmless and Stealthy Ownership Verification for Medical Segmentation via Uncertainty-Guided Backdoors
Jan 23, 2026Annotating medical data for training AI models is often costly and limited due to the shortage of specialists with relevant clinical expertise. This challenge is further compounded by privacy and ethical concerns associated with sensitive patient information. As a result, well-trained medical segmentation models on private datasets constitute valuable intellectual property requiring robust protection mechanisms. Existing model protection techniques primarily focus on classification and generative tasks, while segmentation models-crucial to medical image analysis-remain largely underexplored. In this paper, we propose a novel, stealthy, and harmless method, StealthMark, for verifying the ownership of medical segmentation models under black-box conditions. Our approach subtly modulates model uncertainty without altering the final segmentation outputs, thereby preserving the model's performance. To enable ownership verification, we incorporate model-agnostic explanation methods, e.g. LIME, to extract feature attributions from the model outputs. Under specific triggering conditions, these explanations reveal a distinct and verifiable watermark. We further design the watermark as a QR code to facilitate robust and recognizable ownership claims. We conducted extensive experiments across four medical imaging datasets and five mainstream segmentation models. The results demonstrate the effectiveness, stealthiness, and harmlessness of our method on the original model's segmentation performance. For example, when applied to the SAM model, StealthMark consistently achieved ASR above 95% across various datasets while maintaining less than a 1% drop in Dice and AUC scores, significantly outperforming backdoor-based watermarking methods and highlighting its strong potential for practical deployment. Our implementation code is made available at: https://github.com/Qinkaiyu/StealthMark.
GROK: From Quantitative Biomarkers to Qualitative Diagnosis via a Grounded MLLM with Knowledge-Guided Instruction
Oct 05, 2025
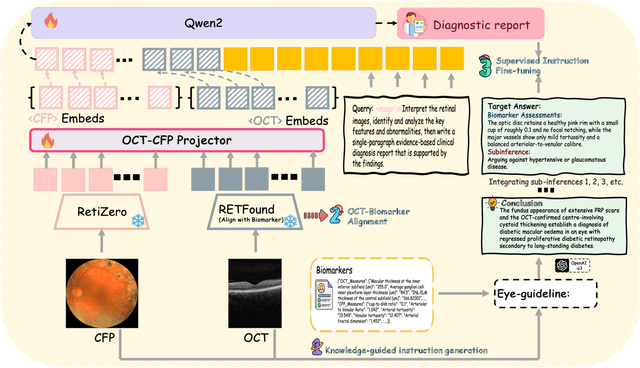


Multimodal large language models (MLLMs) hold promise for integrating diverse data modalities, but current medical adaptations such as LLaVA-Med often fail to fully exploit the synergy between color fundus photography (CFP) and optical coherence tomography (OCT), and offer limited interpretability of quantitative biomarkers. We introduce GROK, a grounded multimodal large language model that jointly processes CFP, OCT, and text to deliver clinician-grade diagnoses of ocular and systemic disease. GROK comprises three core modules: Knowledge-Guided Instruction Generation, CLIP-Style OCT-Biomarker Alignment, and Supervised Instruction Fine-Tuning, which together establish a quantitative-to-qualitative diagnostic chain of thought, mirroring real clinical reasoning when producing detailed lesion annotations. To evaluate our approach, we introduce the Grounded Ophthalmic Understanding benchmark, which covers six disease categories and three tasks: macro-level diagnostic classification, report generation quality, and fine-grained clinical assessment of the generated chain of thought. Experiments show that, with only LoRA (Low-Rank Adaptation) fine-tuning of a 7B-parameter Qwen2 backbone, GROK outperforms comparable 7B and 32B baselines on both report quality and fine-grained clinical metrics, and even exceeds OpenAI o3. Code and data are publicly available in the GROK repository.
A Clinician-Friendly Platform for Ophthalmic Image Analysis Without Technical Barriers
Apr 22, 2025Artificial intelligence (AI) shows remarkable potential in medical imaging diagnostics, but current models typically require retraining when deployed across different clinical centers, limiting their widespread adoption. We introduce GlobeReady, a clinician-friendly AI platform that enables ocular disease diagnosis without retraining/fine-tuning or technical expertise. GlobeReady achieves high accuracy across imaging modalities: 93.9-98.5% for an 11-category fundus photo dataset and 87.2-92.7% for a 15-category OCT dataset. Through training-free local feature augmentation, it addresses domain shifts across centers and populations, reaching an average accuracy of 88.9% across five centers in China, 86.3% in Vietnam, and 90.2% in the UK. The built-in confidence-quantifiable diagnostic approach further boosted accuracy to 94.9-99.4% (fundus) and 88.2-96.2% (OCT), while identifying out-of-distribution cases at 86.3% (49 CFP categories) and 90.6% (13 OCT categories). Clinicians from multiple countries rated GlobeReady highly (average 4.6 out of 5) for its usability and clinical relevance. These results demonstrate GlobeReady's robust, scalable diagnostic capability and potential to support ophthalmic care without technical barriers.
Uncertainty is Fragile: Manipulating Uncertainty in Large Language Models
Jul 15, 2024



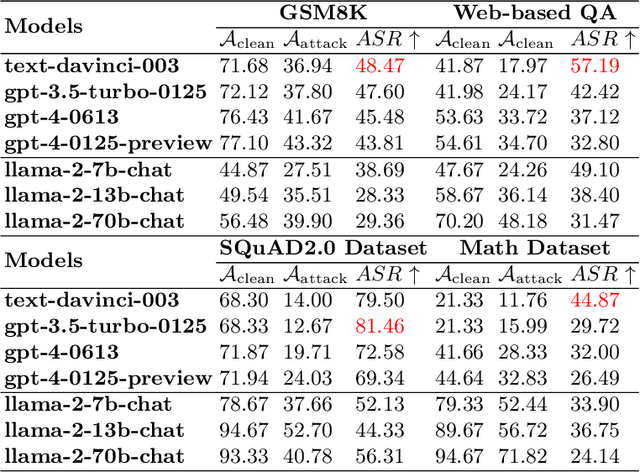
Large Language Models (LLMs) are employed across various high-stakes domains, where the reliability of their outputs is crucial. One commonly used method to assess the reliability of LLMs' responses is uncertainty estimation, which gauges the likelihood of their answers being correct. While many studies focus on improving the accuracy of uncertainty estimations for LLMs, our research investigates the fragility of uncertainty estimation and explores potential attacks. We demonstrate that an attacker can embed a backdoor in LLMs, which, when activated by a specific trigger in the input, manipulates the model's uncertainty without affecting the final output. Specifically, the proposed backdoor attack method can alter an LLM's output probability distribution, causing the probability distribution to converge towards an attacker-predefined distribution while ensuring that the top-1 prediction remains unchanged. Our experimental results demonstrate that this attack effectively undermines the model's self-evaluation reliability in multiple-choice questions. For instance, we achieved a 100 attack success rate (ASR) across three different triggering strategies in four models. Further, we investigate whether this manipulation generalizes across different prompts and domains. This work highlights a significant threat to the reliability of LLMs and underscores the need for future defenses against such attacks. The code is available at https://github.com/qcznlp/uncertainty_attack.
CLIP-DR: Textual Knowledge-Guided Diabetic Retinopathy Grading with Ranking-aware Prompting
Jul 04, 2024Diabetic retinopathy (DR) is a complication of diabetes and usually takes decades to reach sight-threatening levels. Accurate and robust detection of DR severity is critical for the timely management and treatment of diabetes. However, most current DR grading methods suffer from insufficient robustness to data variability (\textit{e.g.} colour fundus images), posing a significant difficulty for accurate and robust grading. In this work, we propose a novel DR grading framework CLIP-DR based on three observations: 1) Recent pre-trained visual language models, such as CLIP, showcase a notable capacity for generalisation across various downstream tasks, serving as effective baseline models. 2) The grading of image-text pairs for DR often adheres to a discernible natural sequence, yet most existing DR grading methods have primarily overlooked this aspect. 3) A long-tailed distribution among DR severity levels complicates the grading process. This work proposes a novel ranking-aware prompting strategy to help the CLIP model exploit the ordinal information. Specifically, we sequentially design learnable prompts between neighbouring text-image pairs in two different ranking directions. Additionally, we introduce a Similarity Matrix Smooth module into the structure of CLIP to balance the class distribution. Finally, we perform extensive comparisons with several state-of-the-art methods on the GDRBench benchmark, demonstrating our CLIP-DR's robustness and superior performance. The implementation code is available \footnote{\url{https://github.com/Qinkaiyu/CLIP-DR}
Exploring Concept Depth: How Large Language Models Acquire Knowledge at Different Layers?
Apr 10, 2024This paper studies the phenomenon that different concepts are learned in different layers of large language models, i.e. more difficult concepts are fully acquired with deeper layers. We define the difficulty of concepts by the level of abstraction, and here it is crudely categorized by factual, emotional, and inferential. Each category contains a spectrum of tasks, arranged from simple to complex. For example, within the factual dimension, tasks range from lie detection to categorizing mathematical problems. We employ a probing technique to extract representations from different layers of the model and apply these to classification tasks. Our findings reveal that models tend to efficiently classify simpler tasks, indicating that these concepts are learned in shallower layers. Conversely, more complex tasks may only be discernible at deeper layers, if at all. This paper explores the implications of these findings for our understanding of model learning processes and internal representations. Our implementation is available at \url{https://github.com/Luckfort/CD}.
Goal-guided Generative Prompt Injection Attack on Large Language Models
Apr 06, 2024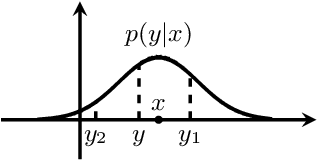
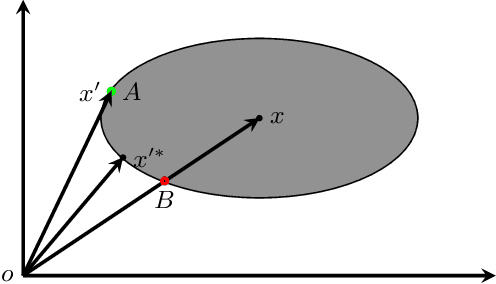
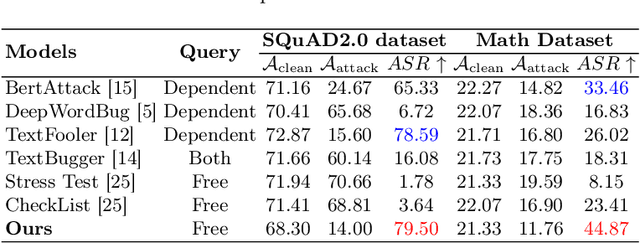
Current large language models (LLMs) provide a strong foundation for large-scale user-oriented natural language tasks. A large number of users can easily inject adversarial text or instructions through the user interface, thus causing LLMs model security challenges. Although there is currently a large amount of research on prompt injection attacks, most of these black-box attacks use heuristic strategies. It is unclear how these heuristic strategies relate to the success rate of attacks and thus effectively improve model robustness. To solve this problem, we redefine the goal of the attack: to maximize the KL divergence between the conditional probabilities of the clean text and the adversarial text. Furthermore, we prove that maximizing the KL divergence is equivalent to maximizing the Mahalanobis distance between the embedded representation $x$ and $x'$ of the clean text and the adversarial text when the conditional probability is a Gaussian distribution and gives a quantitative relationship on $x$ and $x'$. Then we designed a simple and effective goal-guided generative prompt injection strategy (G2PIA) to find an injection text that satisfies specific constraints to achieve the optimal attack effect approximately. It is particularly noteworthy that our attack method is a query-free black-box attack method with low computational cost. Experimental results on seven LLM models and four datasets show the effectiveness of our attack method.
Time Series Forecasting with LLMs: Understanding and Enhancing Model Capabilities
Feb 19, 2024



Large language models (LLMs) have been applied in many fields with rapid development in recent years. As a classic machine learning task, time series forecasting has recently received a boost from LLMs. However, there is a research gap in the LLMs' preferences in this field. In this paper, by comparing LLMs with traditional models, many properties of LLMs in time series prediction are found. For example, our study shows that LLMs excel in predicting time series with clear patterns and trends but face challenges with datasets lacking periodicity. We explain our findings through designing prompts to require LLMs to tell the period of the datasets. In addition, the input strategy is investigated, and it is found that incorporating external knowledge and adopting natural language paraphrases positively affects the predictive performance of LLMs for time series. Overall, this study contributes to insight into the advantages and limitations of LLMs in time series forecasting under different conditions.