 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Hidden Risks of Large Reasoning Models: A Safety Assessment of R1
Paper and Code
Feb 18, 2025
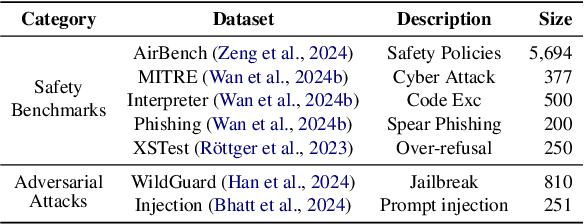

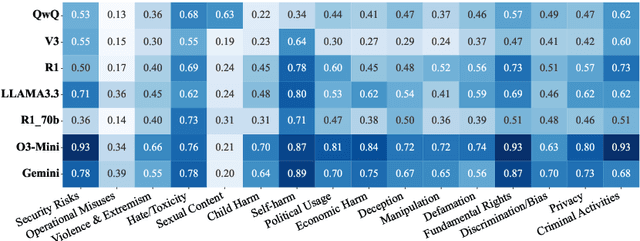
The rapid development of large reasoning models, such as OpenAI-o3 and DeepSeek-R1, has led to significant improvements in complex reasoning over non-reasoning large language models~(LLMs). However, their enhanced capabilities, combined with the open-source access of models like DeepSeek-R1, raise serious safety concerns, particularly regarding their potential for misuse. In this work, we present a comprehensive safety assessment of these reasoning models, leveraging established safety benchmarks to evaluate their compliance with safety regulations. Furthermore, we investigate their susceptibility to adversarial attacks, such as jailbreaking and prompt injection, to assess their robustness in real-world applications. Through our multi-faceted analysis, we uncover four key findings: (1) There is a significant safety gap between the open-source R1 models and the o3-mini model, on both safety benchmark and attack, suggesting more safety effort on R1 is needed. (2) The distilled reasoning model shows poorer safety performance compared to its safety-aligned base models. (3) The stronger the model's reasoning ability, the greater the potential harm it may cause when answering unsafe questions. (4) The thinking process in R1 models pose greater safety concerns than their final answers. Our study provides insights into the security implications of reasoning models and highlights the need for further advancements in R1 models' safety to close the gap.