 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Agent Harness Safety
May 14, 2026LLM agents increasingly run inside execution harnesses that dispatch tools, allocate resources, and route messages between specialized components. However, a harness can return a correct, benign answer over a trajectory that accesses unauthorized resources or leaks context to the wrong agent. Output-level evaluation cannot see these failures, yet most safety benchmarks score only final outputs or terminal states, even though many violations occur mid-trajectory rather than at termination. The central question is whether the harness respects user intent, permission boundaries, and information-flow constraints throughout execution. To address this gap, we propose HarnessAudit, a framework that audits full execution trajectories across boundary compliance, execution fidelity, and system stability, with a focus on multi-agent harnesses where these risks are most pronounced. We further introduce HarnessAudit-Bench, a benchmark of 210 tasks across eight real-world domains, instantiated in both single-agent and multi-agent configurations with embedded safety constraints. Evaluating ten harness configurations across frontier models and three multi-agent frameworks, we find that: (i) task completion is misaligned with safe execution, and violations accumulate with trajectory length; (ii) safety risks vary across domains, task types, and agent roles; (iii) most violations concentrate in resource access and inter-agent information transfer; and (iv) multi-agent collaboration expands the safety risk surface, while harness design sets the upper bound of safe deployment.
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Feb 13, 2026Agent Skills are structured packages of procedural knowledge that augment LLM agents at inference time. Despite rapid adoption, there is no standard way to measure whether they actually help. We present SkillsBench, a benchmark of 86 tasks across 11 domains paired with curated Skills and deterministic verifiers. Each task is evaluated under three conditions: no Skills, curated Skills, and self-generated Skills. We test 7 agent-model configurations over 7,308 trajectories. Curated Skills raise average pass rate by 16.2 percentage points(pp), but effects vary widely by domain (+4.5pp for Software Engineering to +51.9pp for Healthcare) and 16 of 84 tasks show negative deltas. Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming. Focused Skills with 2--3 modules outperform comprehensive documentation, and smaller models with Skills can match larger models without them.
Making Bias Non-Predictive: Training Robust LLM Judges via Reinforcement Learning
Feb 02, 2026Large language models (LLMs) increasingly serve as automated judges, yet they remain susceptible to cognitive biases -- often altering their reasoning when faced with spurious prompt-level cues such as consensus claims or authority appeals. Existing mitigations via prompting or supervised fine-tuning fail to generalize, as they modify surface behavior without changing the optimization objective that makes bias cues predictive. To address this gap, we propose Epistemic Independence Training (EIT), a reinforcement learning framework grounded in a key principle: to learn independence, bias cues must be made non-predictive of reward. EIT operationalizes this through a balanced conflict strategy where bias signals are equally likely to support correct and incorrect answers, combined with a reward design that penalizes bias-following without rewarding bias agreement. Experiments on Qwen3-4B demonstrate that EIT improves both accuracy and robustness under adversarial biases, while preserving performance when bias aligns with truth. Notably, models trained only on bandwagon bias generalize to unseen bias types such as authority and distraction, indicating that EIT induces transferable epistemic independence rather than bias-specific heuristics. Code and data are available at https://anonymous.4open.science/r/bias-mitigation-with-rl-BC47.
Clipping-Free Policy Optimization for Large Language Models
Jan 30, 2026Reinforcement learning has become central to post-training large language models, yet dominant algorithms rely on clipping mechanisms that introduce optimization issues at scale, including zero-gradient regions, reward hacking, and training instability. We propose Clipping-Free Policy Optimization (CFPO), which replaces heuristic clipping with a convex quadratic penalty derived from Total Variation divergence constraints, yielding an everywhere-differentiable objective that enforces stable policy updates without hard boundaries. We evaluate CFPO across both reasoning and alignment settings. In reasoning, CFPO matches clipping-based methods on downstream benchmarks while extending the stable training regime. In alignment, CFPO mitigates verbosity exploitation and reduces capability degradation, while achieving competitive instruction-following performance. CFPO requires only a one-line code change and no additional hyperparameters. Our results suggest that CFPO is a promising drop-in alternative to clipping-based methods for LLM post-training.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
InfoSynth: Information-Guided Benchmark Synthesis for LLMs
Jan 02, 2026Large language models (LLMs) have demonstrated significant advancements in reasoning and code generation. However, efficiently creating new benchmarks to evaluate these capabilities remains a challenge. Traditional benchmark creation relies on manual human effort, a process that is both expensive and time-consuming. Furthermore, existing benchmarks often contaminate LLM training data, necessitating novel and diverse benchmarks to accurately assess their genuine capabilities. This work introduces InfoSynth, a novel framework for automatically generating and evaluating reasoning benchmarks guided by information-theoretic principles. We propose metrics based on KL-divergence and entropy to quantify benchmark novelty and diversity without relying on costly model evaluations. Building on this framework, we develop an end-to-end pipeline that synthesizes robust Python coding problems from seed datasets using genetic algorithms and iterative code feedback. Our method generates accurate test cases and solutions to new problems 97% of the time, and the synthesized benchmarks consistently exhibit higher novelty and diversity compared to their seed datasets. Moreover, our algorithm provides a method for controlling the novelty/diversity and difficulty of generated problems. InfoSynth offers a scalable, self-verifying pipeline for constructing high-quality, novel and diverse benchmarks for LLMs. Project Page: https://ishirgarg.github.io/infosynth_web/
Machine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models
Jul 10, 2025Bullshit, as conceptualized by philosopher Harry Frankfurt, refers to statements made without regard to their truth value. While previous work has explored large language model (LLM) hallucination and sycophancy, we propose machine bullshit as an overarching conceptual framework that can allow researchers to characterize the broader phenomenon of emergent loss of truthfulness in LLMs and shed light on its underlying mechanisms. We introduce the Bullshit Index, a novel metric quantifying LLMs' indifference to truth, and propose a complementary taxonomy analyzing four qualitative forms of bullshit: empty rhetoric, paltering, weasel words, and unverified claims. We conduct empirical evaluations on the Marketplace dataset, the Political Neutrality dataset, and our new BullshitEval benchmark (2,400 scenarios spanning 100 AI assistants) explicitly designed to evaluate machine bullshit. Our results demonstrate that model fine-tuning with reinforcement learning from human feedback (RLHF) significantly exacerbates bullshit and inference-time chain-of-thought (CoT) prompting notably amplify specific bullshit forms, particularly empty rhetoric and paltering. We also observe prevalent machine bullshit in political contexts, with weasel words as the dominant strategy. Our findings highlight systematic challenges in AI alignment and provide new insights toward more truthful LLM behavior.
AgentSynth: Scalable Task Generation for Generalist Computer-Use Agents
Jun 17, 2025We introduce AgentSynth, a scalable and cost-efficient pipeline for automatically synthesizing high-quality tasks and trajectory datasets for generalist computer-use agents. Leveraging information asymmetry, AgentSynth constructs subtasks that are simple during generation but significantly more challenging when composed into long-horizon tasks, enabling the creation of over 6,000 diverse and realistic tasks. Our pipeline begins with an LLM-based task proposer guided by a persona, followed by an execution agent that completes the task and logs the trajectory. This process is repeated iteratively to form a sequence of subtasks, which are then summarized by a separate agent into a composite task of controllable difficulty. A key strength of AgentSynth is its ability to precisely modulate task complexity by varying the number of subtasks. Empirical evaluations show that state-of-the-art LLM agents suffer a steep performance drop, from 18% success at difficulty level 1 to just 4% at level 6, highlighting the benchmark's difficulty and discriminative power. Moreover, our pipeline achieves a low average cost of \$0.60 per trajectory, orders of magnitude cheaper than human annotations. Our code and data are publicly available at https://github.com/sunblaze-ucb/AgentSynth
OVERT: A Benchmark for Over-Refusal Evaluation on Text-to-Image Models
May 28, 2025Text-to-Image (T2I) models have achieved remarkable success in generating visual content from text inputs. Although multiple safety alignment strategies have been proposed to prevent harmful outputs, they often lead to overly cautious behavior -- rejecting even benign prompts -- a phenomenon known as $\textit{over-refusal}$ that reduces the practical utility of T2I models. Despite over-refusal having been observed in practice, there is no large-scale benchmark that systematically evaluates this phenomenon for T2I models. In this paper, we present an automatic workflow to construct synthetic evaluation data, resulting in OVERT ($\textbf{OVE}$r-$\textbf{R}$efusal evaluation on $\textbf{T}$ext-to-image models), the first large-scale benchmark for assessing over-refusal behaviors in T2I models. OVERT includes 4,600 seemingly harmful but benign prompts across nine safety-related categories, along with 1,785 genuinely harmful prompts (OVERT-unsafe) to evaluate the safety-utility trade-off. Using OVERT, we evaluate several leading T2I models and find that over-refusal is a widespread issue across various categories (Figure 1), underscoring the need for further research to enhance the safety alignment of T2I models without compromising their functionality. As a preliminary attempt to reduce over-refusal, we explore prompt rewriting; however, we find it often compromises faithfulness to the meaning of the original prompts. Finally, we demonstrate the flexibility of our generation framework in accommodating diverse safety requirements by generating customized evaluation data adapting to user-defined policies.
Learning to Reason without External Rewards
May 26, 2025
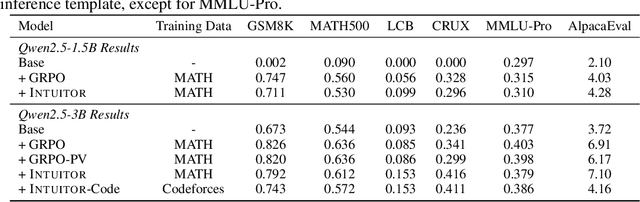
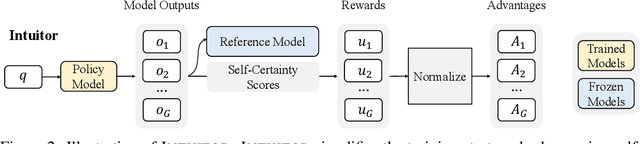
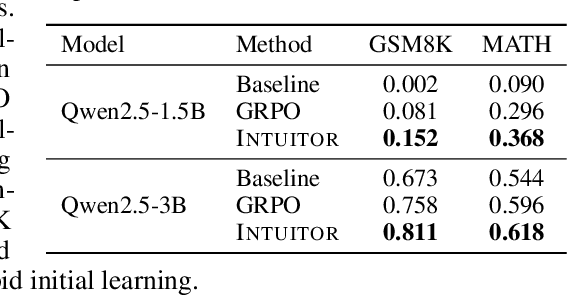
Training large language models (LLMs) for complex reasoning via Reinforcement Learning with Verifiable Rewards (RLVR) is effective but limited by reliance on costly, domain-specific supervision. We explore Reinforcement Learning from Internal Feedback (RLIF), a framework that enables LLMs to learn from intrinsic signals without external rewards or labeled data. We propose Intuitor, an RLIF method that uses a model's own confidence, termed self-certainty, as its sole reward signal. Intuitor replaces external rewards in Group Relative Policy Optimization (GRPO) with self-certainty scores, enabling fully unsupervised learning. Experiments demonstrate that Intuitor matches GRPO's performance on mathematical benchmarks while achieving superior generalization to out-of-domain tasks like code generation, without requiring gold solutions or test cases. Our findings show that intrinsic model signals can drive effective learning across domains, offering a scalable alternative to RLVR for autonomous AI systems where verifiable rewards are unavailable. Code is available at https://github.com/sunblaze-ucb/Intuitor