 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason without External Rewards
May 26, 2025
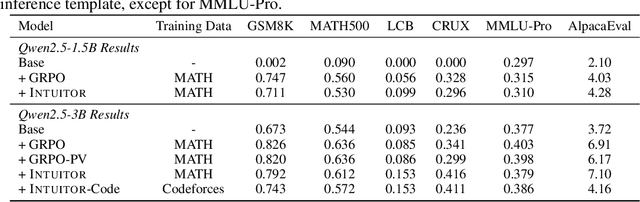
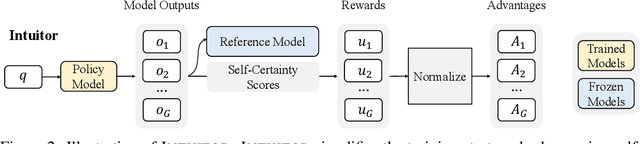
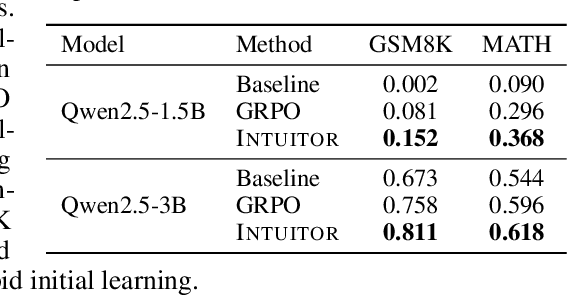
Training large language models (LLMs) for complex reasoning via Reinforcement Learning with Verifiable Rewards (RLVR) is effective but limited by reliance on costly, domain-specific supervision. We explore Reinforcement Learning from Internal Feedback (RLIF), a framework that enables LLMs to learn from intrinsic signals without external rewards or labeled data. We propose Intuitor, an RLIF method that uses a model's own confidence, termed self-certainty, as its sole reward signal. Intuitor replaces external rewards in Group Relative Policy Optimization (GRPO) with self-certainty scores, enabling fully unsupervised learning. Experiments demonstrate that Intuitor matches GRPO's performance on mathematical benchmarks while achieving superior generalization to out-of-domain tasks like code generation, without requiring gold solutions or test cases. Our findings show that intrinsic model signals can drive effective learning across domains, offering a scalable alternative to RLVR for autonomous AI systems where verifiable rewards are unavailable. Code is available at https://github.com/sunblaze-ucb/Intuitor
Scalable Best-of-N Selection for Large Language Models via Self-Certainty
Feb 25, 2025Best-of-N selection is a key technique for improving the reasoning performance of Large Language Models (LLMs) through increased test-time computation. Current state-of-the-art methods often employ computationally intensive reward models for response evaluation and selection. Reward-free alternatives, like self-consistency and universal self-consistency, are limited in their ability to handle open-ended generation tasks or scale effectively. To address these limitations, we propose self-certainty, a novel and efficient metric that leverages the inherent probability distribution of LLM outputs to estimate response quality without requiring external reward models. We hypothesize that higher distributional self-certainty, aggregated across multiple samples, correlates with improved response accuracy, as it reflects greater confidence in the generated output. Through extensive experiments on various reasoning tasks, we demonstrate that self-certainty (1) scales effectively with increasing sample size $N$, akin to reward models but without the computational overhead; (2) complements chain-of-thought, improving reasoning performance beyond greedy decoding; and (3) generalizes to open-ended tasks where traditional self-consistency methods fall short. Our findings establish self-certainty as a practical and efficient way for improving LLM reasoning capabilities. The code is available at https://github.com/backprop07/Self-Certainty